


Немного истории
47 постов
47 постов
10 постов
180 постов

4 поста

Windows — самое популярное семейство ОС для персональных компьютеров. За его сорокалетнюю историю друг друга сменили множество версий системы. Каждая из них радовала пользователей улучшенным интерфейсом и новыми функциями, но взамен становилась все тяжелее для компьютерного железа. Сравним скорость работы шести последних Windows: от старушки XP до современной 11.
Дебютная Windows 1.0 появилась на свет в 1985 году. Однако первой во многих смыслах стала лишь вышедшая на десять лет позже Windows 95. Именно эта ОС принесла удобный графический интерфейс, меню «Пуск», полноценный рабочий стол, технологию Plug and Play и API DirectX, сделавший возможным разработку и запуск графически продвинутых игр.

Благодаря этой системе ПК из устройств для энтузиастов понемногу стали становиться полноценными домашними рабоче-развлекательными центрами. Однако аппаратное обеспечение компьютеров все время совершенствуется, и для полноценной реализации его функциональности нередко требуются кардинальные изменения в ОС. Раз в несколько лет Microsoft решает этот вопрос выпуском новой Windows, попутно улучшая и расширяя ее функциональность.
За три десятилетия после выпуска Windows 95 пользователи домашних компьютеров увидели еще восемь крупных релизов «окон»: 98, ME, XP, Vista, 7, 8, 10 и 11. И тут нас подстерегает первая проблема: сравнить их все на одном и том же ПК просто невозможно — ведь поддержки старого железа у последних версий системы нет, а старые ОС на новом железе просто не запустятся.
Впрочем, если отказаться от самых древних версий Windows, то поиск подходящего компьютера становится куда проще. Но тут возникает вторая проблема: в большинстве таких ПК по меркам современных Windows 10 и 11 стоят довольно медленные процессоры. Поэтому новые системы заведомо окажутся в неравных условиях со старыми и будут выглядеть явными «тормозами».
Обе проблемы решает наш тестовый стенд, обладающий следующими параметрами:
Центральный процессор: Intel Core i7-4790 3.6-4.0 ГГц,
Материнская плата: Gigabyte GA-Z97-HD3;
Система охлаждения ЦП: Intel BOX (E97378-001);
Термоинтерфейс: Arctic Cooling MX-4 (2019 Edition);
Оперативная память: 16 ГБ (2x8) DDR3 Kingston HyperX KHX1600C9D3/8GX;
Видеокарта: Sparkle GeForce GT610 2 ГБ DDR3 (SX610L2048GCU);
Дисковая подсистема: SSD Transcend 370S 128 ГБ + HDD Seagate Barracuda 7200.12 500 ГБ;
Блок питания: Gigabyte Superb E570;
Корпус: Gigabyte GZ-F Plus 3.
Конфигурация нашего ПК позволяет без «танцев с бубном» и модификации драйверов запустить шесть последних версий Windows. А именно:
Windows XP SP3 (Professional)
Windows Vista SP2 (Ultimate)
Windows 7 SP1 (Ultimate)
Windows 8.1 Update 3 (Pro)
Windows 10 22H2 (Pro)
Windows 11 25H2 (Pro)
Тестирование будет производиться с 64-битными версиями всех систем, кроме Windows XP. Автор посчитал неправильным брать XP x64, ведь она основана на другом ядре, нежели всем привычная 32-битная, да и 99 % пользователей домашних ПК ее так и не застали.
Для нашего обзора были взяты версии программ и бенчмарков, которые с одинаковым успехом работают от Windows XP до Windows 11. А именно:
CPU-Z v1.91
GPU-Z v2.66
AIDA64 v6.92.6600
Cinebench R10
3DMark 03 v3.6.0
3DMark 06 v1.2.1
Crysis v1.2.1 (1.1.1.6156)
WinRAR v6.02
7-Zip v26.00
CrystalDisk Mark v8.0.4
Для установки были использованы оригинальные образы MSDN. Перед тестами никакие компоненты или службы систем не отключались и не приостанавливались. Во избежание влияния на результаты фоновой активности ОС каждый бенчмарк прогонялся по три раза, а тесты скорости загрузки и замеры потребления фоновых ресурсов повторялись по семь раз. В качестве итоговых результатов были взяты средние арифметические значения всех запусков.
Перед тестами давайте посмотрим, сколько места свежеустановленные системы занимают на накопителе.
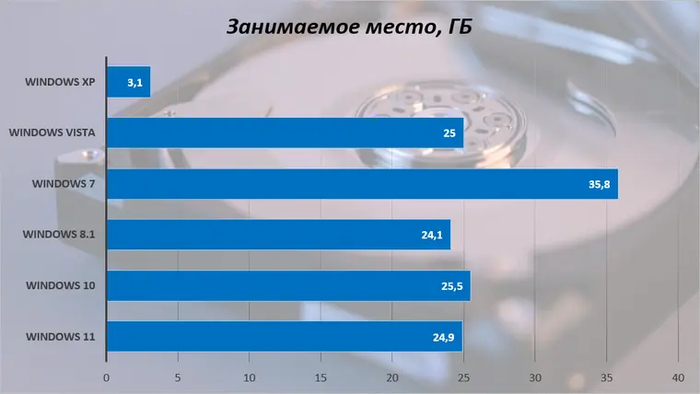
Как же мало весила старушка XP! После нее Vista ощущается гигантом, а Windows 7 — так вообще настоящим монстром.
Однако с выходом Windows 8 и появлением недорогих устройств с памятью eMMC перед Microsoft встала задача уместить ОС и базовые программы в 32 ГБ постоянной памяти. Компания справилась с ней с помощью оптимизации и технологии сжатия системных файлов, которые по наследству передались и более новым версиям Windows.
Теперь взглянем, сколько оперативной памяти после загрузки потребляют наши испытуемые.
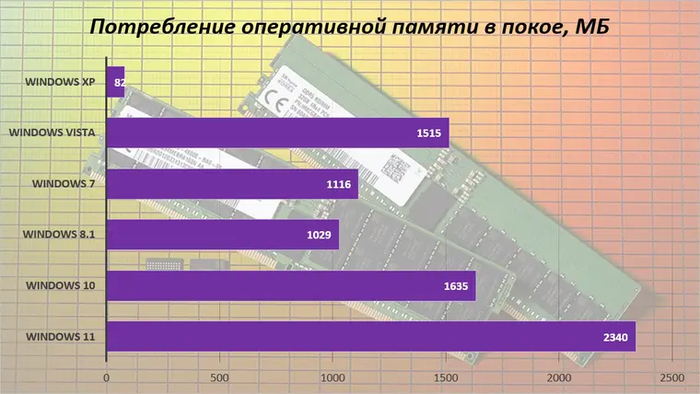
При переходе от XP к Vista наблюдается огромное увеличение потребления ОЗУ. Не стоит удивляться: даже 32-битной «Висте» требуется около 1 ГБ в простое. В 2007 году, когда данная ОС стала распространяться, это нередко повергало пользователей в шок.
В Windows 7 потребление памяти заметно оптимизировали, а визуальный стиль системы почти не пострадал. Но пик оптимизации пришелся на Windows 8/8.1 — множество планшетных ПК тех лет с ней имели малый объем ОЗУ, из-за которого грамотное управление ресурсами системы стало еще более критично.
Windows 10 по сравнению с предшественницей заметно «разъелась», а потребление памяти у Windows 11 так вообще бьет все рекорды. Можно было бы найти в этом повод не переходить на новую ОС, если бы не одно «но» — отключив пару ненужных служб, можно поумерить ее аппетиты до 1700–1800 МБ.
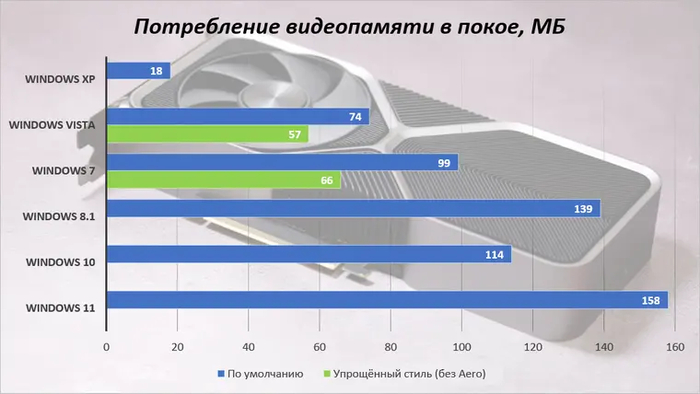
Интересное наблюдение: Vista и 7 даже со всеми красотами стиля Aero требуют меньше видеопамяти, чем «плоская» 8.1. В Windows 10 потребление видео ОЗУ уменьшили, но в Windows 11 из-за обновленного интерфейса оно снова слегка подросло. Впрочем, на фоне объемов памяти современных (и не очень) видеокарт не играет какой-то практической роли.
Эта категория тестов для наглядности проводилась с двумя видами системных накопителей — HDD и SSD.
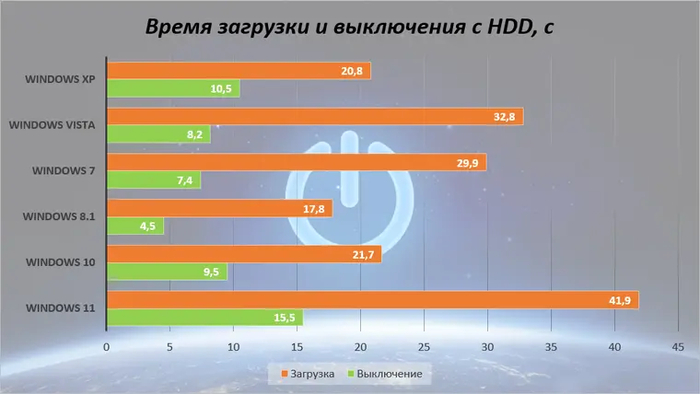
Начиная с «восьмерки», время загрузки заметно сокращается. Но это никакая не магия, просто у Windows 8 и более современных ОС семейства вместо полноценного выключения ядро системы отправляется в гибернацию (функция «быстрый запуск»). Правда, c Windows 11 на HDD даже это уже не помогает: с ней ПК загружается и выключается очень долго.
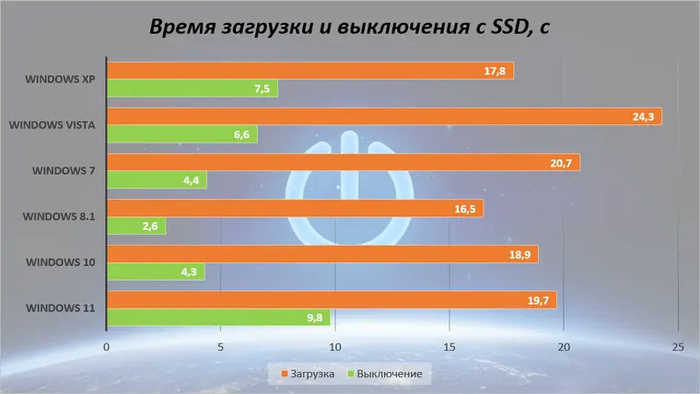
С твердотельным накопителем все системы чувствуют себя заметно лучше. Новые ОС опережают старичков не просто так: ведь XP и Vista о SSD еще «не знают» и не имеют для них встроенных оптимизаций. 7 и 10 тут сравнялись, но королем все также осталась Windows 8.1.
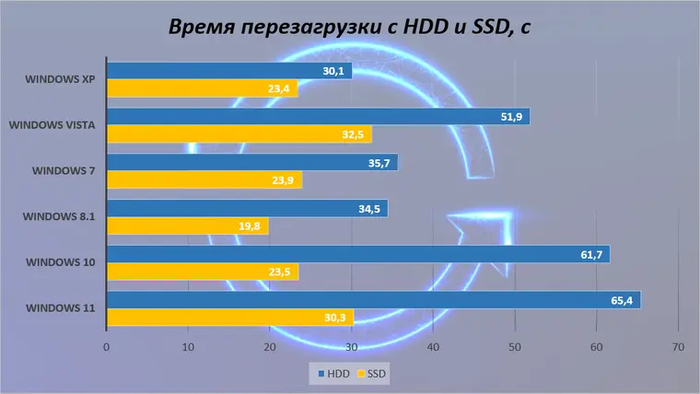
В случае с перезагрузкой и HDD все системы оказываются в равных условия. Быстрый запуск тут не играет роли, поэтому XP самая быстрая. Но на SSD ее все-таки обгоняет Windows 8.1, имеющая встроенные оптимизации для данного вида накопителей.
Теперь посмотрим, как разные системы влияют на скорость вычислений тестового ЦП.
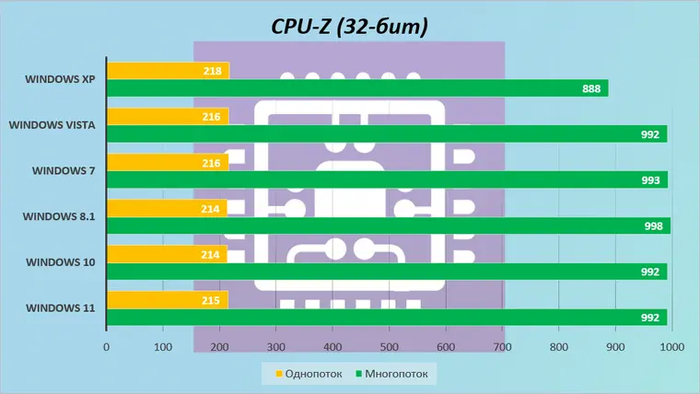
Windows XP создавалась во времена одноядерных процессоров. И хотя ее планировщик поддерживает до 32 логических ЦП, он не умеет взаимодействовать с ними так же эффективно, как более современные системы.
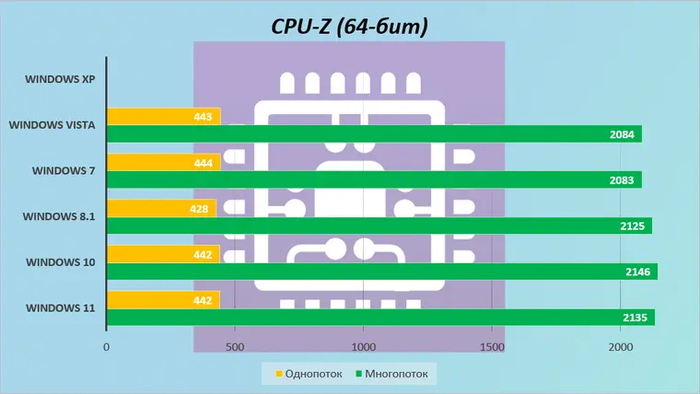
В 64-битном режиме лидерство в многопоточных вычислениях захватывают три последние ОС. Впрочем, «семерка» и Vista отстают от них не так сильно — всего на пару процентов.
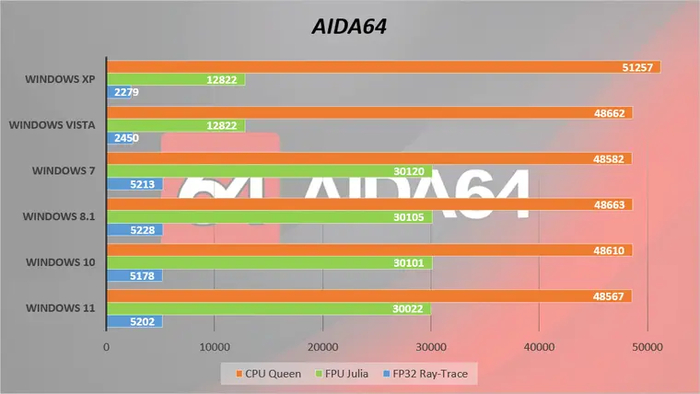
А вот тут ждал cюрприз: XP и Vista не поддерживают инструкции AVX и FMA, поэтому их результаты в тестах с плавающей запятой в несколько раз ниже. Однако самая старая система опередила всех в чисто математическом тесте CPU Queen — скорее всего потому, что у нее практически полностью отсутствует фоновая активность.
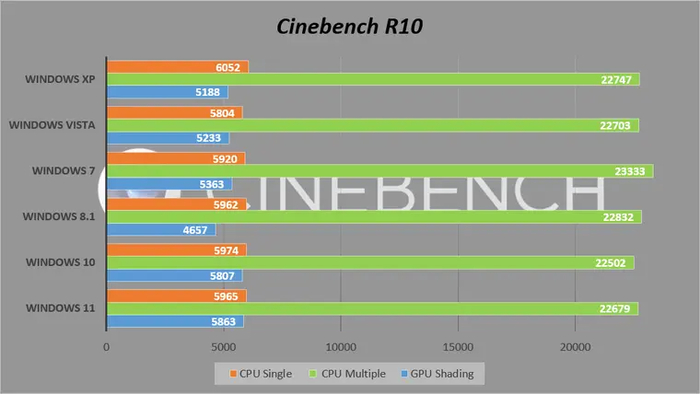
В рендеринге старой версии Cinebench, не имеющей поддержки новых инструкций, все системы выступили почти одинаково. Любопытный момент: оценка производительности графического процессора в «десятке» и «одиннадцатой» выше, чем в более старых ОС. И это несмотря на то, что для данного теста используется устаревший API OpenGL.
С выходом каждой новой Windows многим пользователям наверняка приходилось слышать советы вроде «Не переходи на нее, игры станут тормозить!» Давайте проверим это, оценив производительность графического стека наших испытуемых.
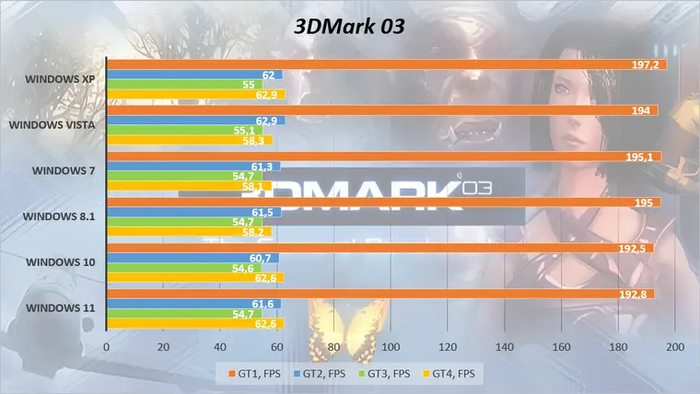
Тестовая видеокарта в современных реалиях очень слаба и уступает даже встроенной графике десятилетней давности. Казалось бы, новые ОС должны «съесть» ее производительность только работой своего интерфейса... Но нет, все системы выступили примерно на одном уровне.
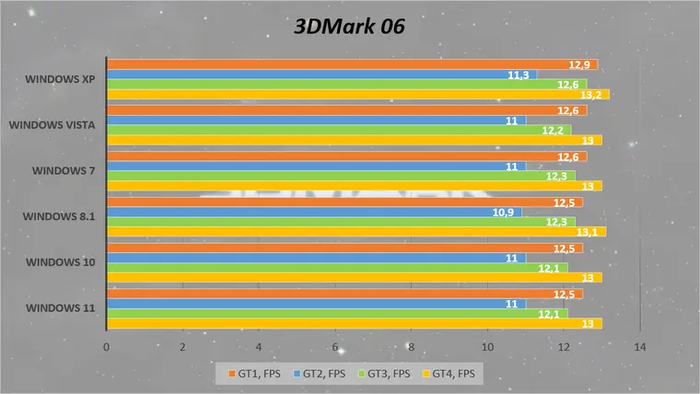
Абсолютно такая же картина и в более новом 3DMark 06.

Crysis со средними настройками в разрешении 1024х768 лишь подтверждает предыдущие наблюдения. Так что играть в старые игры эпохи DirectX 9 с одинаковым успехом можно на любой ОС семейства. Помехой, снижающей производительность в этом случае, может стать разве что медленный ЦП.
Проверим тандем из вычислительных возможностей процессора и оперативной памяти с помощью архиваторов.
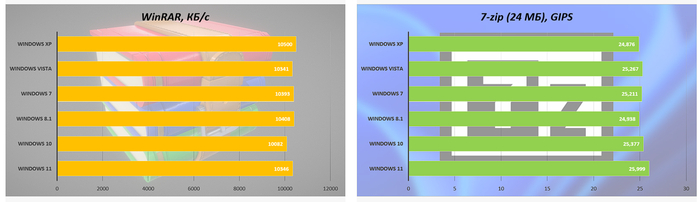
В WinRAR XP опережает своих потомков, но совсем чуть-чуть. А вот в 7-Zip обратная картина: даже с его старой версией более новые ОС оказываются эффективнее.
Напоследок посмотрим, как наши системы работают с накопителями.

Обновленный стек ввода-вывода ядра появился в семействе Windows NT 6.x (Vista и выше). В XP его еще нет, поэтому даже со старым HDD она работает медленнее.
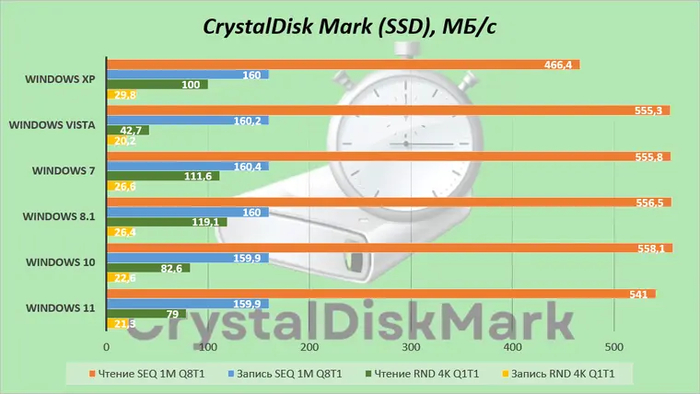
Обратите внимание на скорости случайного доступа (RND). В Windows 7 и 8.1 достигаются пиковые значения: обе ОС умеют работать с SSD, но при этом нетребовательны к дисковой подсистеме. В 10 и 11 эти скорости планомерно снижаются, так как эти системы все время «лезут» на накопитель. Именно из-за этого пользоваться ими на обычных жестких дисках очень трудно.
XP и Vista, в свою очередь, не знакомы с твердотельными накопителями. Поэтому их результаты в одних тестах почти на уровне более новых ОС, а в других — заметно ниже.
Прогресс в софте — это всегда хорошо. От Windows XP до Windows 11 «окна» проделали огромный путь, с каждой версией получая новые функции и открывая перед собой ранее невиданные горизонты возможностей.
При этом почти у каждой новой ОС ожидаемо росли требования к «железу». Особенно заметным это стало при переходе от XP к Vista: потребление ресурсов тогда возросло кратно, совсем не соответствуя обновленной функциональности.
Однако Vista была лишь пробой пера для нового ядра NT 6.x. Позже в доработанном виде оно легло в основу всех последующих версий Windows, включая самые современные.
Поэтому в последние 20 лет фундамент «окон» остается все тем же. В большинстве случаев это позволяет использовать достаточно старое «железо» и запускать приложения прошлых лет даже с новыми ОС. При этом, как мы убедились, практически не теряя в производительности.

В отличие от процессоров для ПК, чипы для смартфонов и планшетов имеют гораздо более широкий ассортимент и крайне запутанную систему названий. Немудрено, что обычному пользователю трудно в них разобраться. Однако на деле все мобильные SoC состоят из нескольких типов одних и тех же ядер. Какими бывают ядра в современных гаджетах? И как по их названиям понять, насколько быстрый перед вами чип?
«Сердцем» любого современного смартфона или планшета является система на чипе (System-on-Chip, SoC). Это миниатюрный кристалл, в котором находятся ядра центрального процессора (CPU), графический ускоритель (GPU), нейронный процессор (NPU), процессоры обработки изображений (ISP) и цифровых сигналов (DSP), модули сотовой и беспроводной связи, а также множество других вспомогательных блоков.

Компания Apple проектирует ключевые компоненты своих SoC сама. Но разработчики чипов для Android-устройств (такие, как Qualcomm, Mediatek, Samsung, Google, Huawei, Xiaomi и Unisoc ) в этом плане нередко полагаются на сторонние решения. Особенно это касается процессорной части: в качестве нее в подавляющем большинстве SoC используются ядра семейства Cortex, разработанные компанией ARM.
В отличие от ПК, где каждая линейка процессоров построена на архитектуре одного поколения, новейшие ядра ARM изначально попадают только в топовые SoC. Но с течением времени большинство из них постепенно появляется во все более бюджетных моделях чипов. Это приводит к тому, что в смартфонах и планшетах одного года выпуска могут использоваться ядра из совершенно разных поколений — от прошлогодних новинок до разработок десятилетней давности.
Современные ядра ARM делятся на три категории: производительные, сверхбыстрые (Prime) и энергоэффективные.
Самый большой «зоопарк» по традиции наблюдается среди производительных ядер: в смартфонах 2024-2025 годов можно встретить aж девять их поколений.
Cortex-A73
Основа топовых чипов 2016 года, которая все еще используется в очень бюджетных смартфонах. Имеет архитектуру ARM v8, имеет простой двухполосный декодер инструкций и шесть исполнительных портов, двумя из которых являются целочисленные ALU.
В последних SoC ядро A73 способно достигать немалых 2,8 ГГц. Однако это помогает ему мало — современные решения, работающие на схожей частоте, быстрее почти на целый порядок.
Cortex-A75
Первое поколение ядер на архитектуре ARM v8.2 с технологией ARM DynamIQ, благодаря которой в мобильных SoC стало не два, а три уровня кэша. За счет новой системы кэширования, добавления дополнительного декодера и ALU ядро A75 способно обогнать предшественника на весомые 25-30 %.
Впрочем, в современных реалиях производительность этого решения все равно считается низкой. Поэтому и такие ядра сегодня встречаются разве что в самых бюджетных гаджетах.
Cortex-A76
Ядра, всколыхнувшие рынок ARM-устройств в 2018 году и прозванные «убийцей Intel». Архитектура A76 была переписана практически с нуля, обеспечив заметный рывок производительности — до 50 % на одной частоте. Этому поспособствовал новый четырехполосный декодер c вдвое большей шириной выдачи, а также заметно усовершенствованные алгоритмы предсказания.
Несмотря на приличный возраст, A76 все еще обеспечивают уровень производительности, который достаточен для повседневных задач. На современных техпроцессах эти ядра занимают крайне малую площадь, а их частота масштабируется вплоть до 3 ГГц. Именно поэтому A76 и сегодня продолжает использоваться в большинстве недорогих смартфонов.
Последователями A76 в 2019 году стали ядра A77. Но они получились прожорливыми и горячими, поэтому перестали использоваться в новых чипах достаточно быстро.
Cortex-A78
Следующие ядра-«долгожители», которые постепенно занимают место A76 в бюджетных SoC. В отличие от предшественников, A78 разрабатывались в качестве ядер второй роли — первую в 2020 году заняло дебютное сверхбыстрое ядро Cortex-X1.
A78 унаследовало от предшественника A77 множество улучшений. В частности — увеличение количества ALU до четырех, а также новый кэш макроопераций, позволяющий хранить уже декодированные инструкции и выполнять их в обход декодера. Бэкэнд ядра был заметно расширен: вместо семи и восьми портов у A75 и A76 новое ядро обзавелось целыми 13. Все это позволило поднять производительность примерно на 20 %.
Cortex-A710
Новинка 2021 года, активно использующаяся в чипах среднего сегмента. Данное ядро первым из производительных получило архитектуру ARM v9 с поддержкой векторных инструкций SVE2. Благодаря этому оно почти вдвое опережает предшественников в задачах машинного обучения: например, при использовании AI-фильтров в камере.
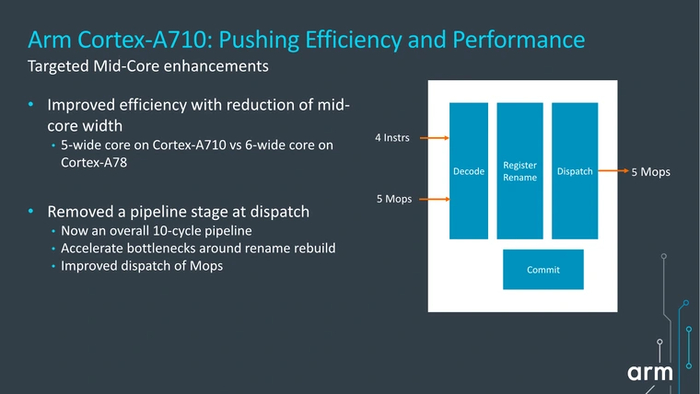
A710 было заметно переработано. Добавился пятый декодер инструкций, а изнутри было «выкинуто» все лишнее: широкая очередь выдачи сменилась традиционной по количеству декодеров, а кэш микроопераций был уменьшен. Вдобавок некоторые исполнительные порты были объединены в универсальные, за счет чего их количество было сокращено до 10. Благодаря этим изменениям конвейер ядра стал загружаться гораздо эффективнее, чем раньше: по сравнению с A78 это принесло около 7-10 % дополнительной производительности.
Cortex-A715
Несмотря на схожее с предшественником числовое обозначение, появление A715 в 2022 году стало знаковым — с него началась эпоха ARM-ядер, поддерживающих только 64-битные вычисления.

Это поколение можно считать глубокой оптимизацией. Помимо удаления части, отвечающей за 32-битные расчеты, был сильно улучшен предсказатель ветвлений. Настолько, что от кэша макроопераций было решено полностью отказаться.
В итоге A715 стало потреблять заметно меньше энергии, однако чистая производительность по сравнению с предшественником почти не выросла. Но взамен ядро научилось работать на более высокой частоте — в самых быстрых чипах она достигает 3,3-3,4 ГГц.
Cortex-A720
Следующее ядро, продолжающее развитие идей A715. Значимых изменений в конвейере не несет, но перешло на обновленную архитектуру ARM v9.2, в которой много внимания было уделено управлению памятью.
A720 получило улучшенный предсказатель переходов, более быстрый кэш L2 и новый движок предвыборки данных, позаимствованный у сверхбыстрых ядер серии Cortex-X. Энергоэффективность ядра возросла заметно, а вот производительность гораздо скромнее — примерно на 5 %.
Cortex-A725
Производительное ядро образца 2024 года. По сравнению с предшественником поддерживает вдвое больший объем кэша L2, эффективнее работает с L3, обзавелось более вместительными буферами инструкций и в очередной раз улучшенным предсказателем переходов.
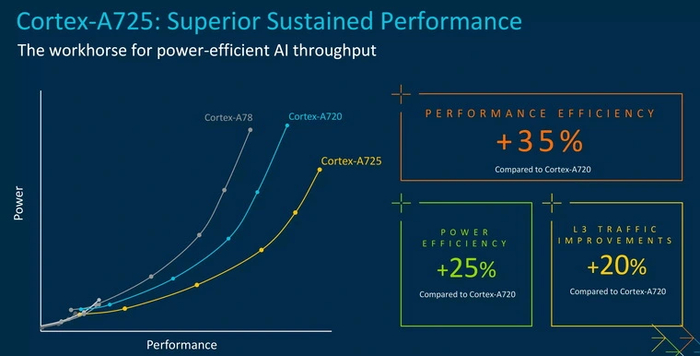
Изменения в A725 были направлены на устранение «узких» мест архитектуры. За счет этого данное поколение ядер обеспечило прирост, как три предыдущих вместе взятые — около 15 % на одной частоте. Ну а энергоэффективность, по традиции, выросла гораздо больше.
По спецификации ядро A725 может работать с новыми матричными инструкциями SME/SME2, ускоряющими задачи машинного обучения до пяти раз. Но их поддержка опциональна и зависит от производителя чипа.
Lumex C1-Pro и C1-Premium
Самые свежие разработки ARM, которые относятся к архитектуре ARM v9.3, вошли в новую линейку под названием Lumex. В ней вместо трех видов ядер уже четыре, а к производительным относятся сразу два — C1 Pro и C1 Premium. Оба в обязательном порядке оснащаются поддержкой инструкций SME/SME2.
С1-Pro — прямой наследник A725. Это ядро с пятиполосным декодером инструкций и четырьмя ALU, которое обзавелось улучшенным предсказателем переходов и обновленной подсистемой памяти. Отрыв от прошлого поколения на уровне 5-10 %.
C1-Premium — новый вид ядер, который в иерархии занимает место между производительными и сверхбыстрыми. Здесь широкий восьмиполосный декодер и 17 исполнительных портов, среди которых шесть целочисленных ALU. Производительность заметно выше и схожа с недавним сверхбыстрым ядром Cortex-X4.
В отличие от производительных, сверхбыстрые ядра в новых SoC заменяются на актуальные поколения гораздо оперативнее. Поэтому их разнообразие в современных моделях смартфонов и планшетов заметно меньше.
Cortex-X4
Одно из самых удачных Prime-ядер родом из 2023 года, которое нашло приют во множестве флагманских и субфлагманских чипов. Способно работать на частоте до 3,4 ГГц и обладает восьмиполосным декодером с 15 исполнительными портами, среди которых нашлось место шести ALU. Такая связка позволяет X4 опережать современные производительные ядра семейства A7** на 40–60 %.
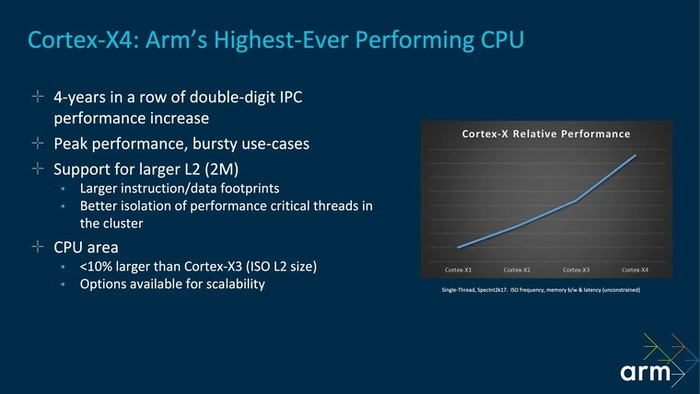
Cortex-X925
Следующее поколение сверхбыстрых ядер, доставшееся флагманским чипам 2024 года. Обзавелось более быстрыми и объемными кэшами, а также усовершенствованным блоком предсказания ветвлений, за счет чего быстрее предшественника примерно на 15 %. Пиковая частота теперь может достигать 3,8 ГГц.
Как и X4, X925 основано на архитектуре ARM v9.2. Но разница в скорости выполнения задач машинного обучения между этими двумя ядрами может быть кратной, так как более новое X925 поддерживает матричные инструкции SME/SME2 и имеет в полтора раза больше векторных движков.
Lumex C1-Ultra
Последнее поколение Prime-ядер, основанное на архитектуре ARM v9.3. Имеет невероятно широкий десятиполосный декодер, 21 исполнительный порт и целых восемь ALU. Вдобавок ядро получило в очередной раз улучшенный предсказатель ветвлений, а также увеличенные и ускоренные кэши. При равных условиях опережает предшественника примерно на 10 %, но может работать на заметно более высокой частоте — вплоть до 4,3 ГГц.
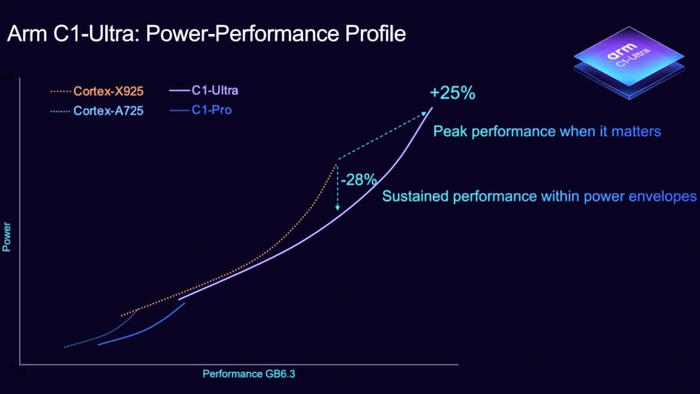
Qualcomm Oryon
Говоря о сверхбыстрых ARM-решениях, стоит упомянуть и о собственной разработке компании Qualcomm — ядрах Oryon. Их первое поколение дебютировало в 2023 году в SoC для ноутбуков, но уже второе стало «сердцем» флагманских смартфонов.
Oryon — универсальные ядра, которые могут быть сконфигурированы как сверхбыстрые или производительные. Они способны работать на частотах свыше 4,4 ГГц, но при этом остаются довольно экономичными и поэтому не нуждаются в энергоэффективных компаньонах.

Oryon первых двух поколений имеют по восемь декодеров и 14 исполнительных блоков, из которых шесть приходится на ALU. Формально они соответствуют не самой новой архитектуре ARM v8.7, но обладают очень продвинутым предсказателем переходов и быстрыми векторными движками, которые не являются частью ядер и подключаются к ним по отдельной шине. В равных условиях Oryon второго поколения немного уступает ядру X925, но за счет более высоких частот слегка опережает его.
Oryon третьего поколения еще «шире»: здесь 10 декодеров и 16 портов, среди которых на ALU приходится уже восемь. Обновленное ядро соответствует спецификации ARM v9.2 и поддерживает инструкции SVE2 и SME. Но главная его фишка — кастомные специализированные блоки Matrix Accelerator, которые еще больше ускоряют расчеты машинного обучения. По производительности наблюдается примерный паритет с C1-Ultra, но ядро Qualcomm может работать и быстрее за счет более высокой частоты.
Такие решения выпускаются ARM гораздо реже, чем производительные и сверхбыстрые. Поэтому срок их актуальности по сравнению со «старшими братьями» заметно больше.
Низкое потребление энергоэффективных ядер достигается в первую очередь за счет отсутствия внеочередного исполнения инструкций (Out-of-Order). В отличие от производительных и cверхбыстрых, такие ядра умеют выполнять их только строго по порядку (In-Order). Поэтому в них нет конфигурируемых исполнительных портов — за каждым декодером закреплен ровно один порт с ALU.
Cortex-A53
Старейшие ядра родом из 2012 года, которые до сих пор встречаются в самом нижнем сегменте Android-устройств. Имеют двухполосный декодер и способны работать на частоте до 2,3 ГГц. Крайне медленны и неповоротливы: даже A75, «тормозные» по современным меркам, вдвое быстрее.
A53 стали первыми энергоэффективными решениями, которые могут работать самостоятельно, то есть без производительных ядер. Множество ультрабюджетных SoC используют их именно в такой конфигурации.
Cortex-A55
Это ядро пришло на смену предшественнику только в 2017 году. Предсказатель переходов был заметно улучшен, а благодаря технологии ARM DynamIQ появилась трехуровневая система кэширования. Это позволило увеличить производительность на 7–10 %.
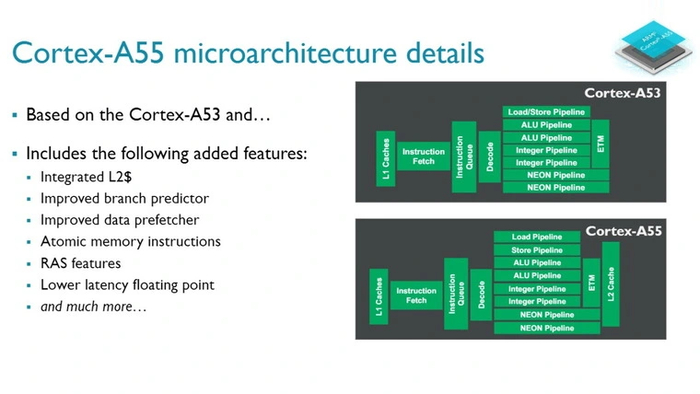
За счет перехода с архитектуры ARM v8 на ARM v8.2 у этих ядер появилась поддержка инструкций DOT, способных заменить собой целую последовательность сложений и умножений. Поэтому A55 стало справляться с задачами машинного обучения до двух раз быстрее.
Cortex-A510
2021 год был ознаменован появлением архитектуры ARM v9, вместе с которой дебютировали и новые экономичные ядра A510. Они обзавелись трехполосным декодером, увеличившим производительность примерно на 35 %. А машинные алгоритмы стали работать на этих ядрах и вовсе вдвое быстрее — все за счет поддержки новых инструкций SVE2.
В отличие от A53 и A55, начиная с этого поколения энергоэффективные ядра используются в SoC только в паре с производительными.
Cortex-A520
Разработка 2023 года, вернувшая развитие энергоэффективных ядер в привычное русло. «Раздутый» декодер предшественников требовал много энергии, поэтому в этом поколении ARM снова вернулась к двухполосной схеме. Вдобавок из ядра была удалена логика, отвечающая за 32-битные вычисления, а его архитектура была обновлена до актуальной ARM v9.2.
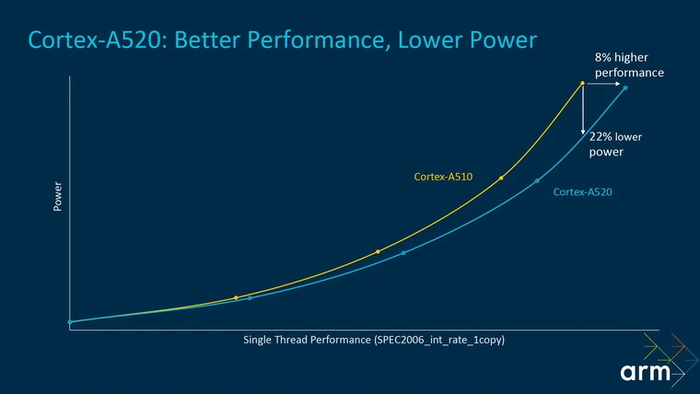
За счет глубокой оптимизации конвейера и избавления от ненужных блоков A520 стало заметно экономичнее. Но самое главное, что от этого его производительность не упала, а выросла на 5-8 %.
Lumex С1-Nano
Последнее поколение «малых» ядер, дебютировавших в 2025 году. Они сохранили классический декодер с двумя полосами, но блок предсказаний здесь впервые был отделен от блока выборки инструкций — это позволяет подгружать инструкции, не дожидаясь завершения текущих. Благодаря этому простои конвейера были в очередной раз уменьшены, что позволило улучшить производительность примерно на 5–10 %.
Как и старшие варианты C1, C1 Nano имеют архитектуру ARM v9.3 c поддержкой инструкций SME2, позволяющих выполнять матричные вычисления до пяти раз быстрее. К тому же именно у этих энергоэффективных ядер впервые за долгие годы заметно выросла частота — теперь она может достигать отметки в 2,6 ГГц.
Объединим ключевые характеристики актуальных ARM-ядер в сравнительных таблицах.
Таблица №1
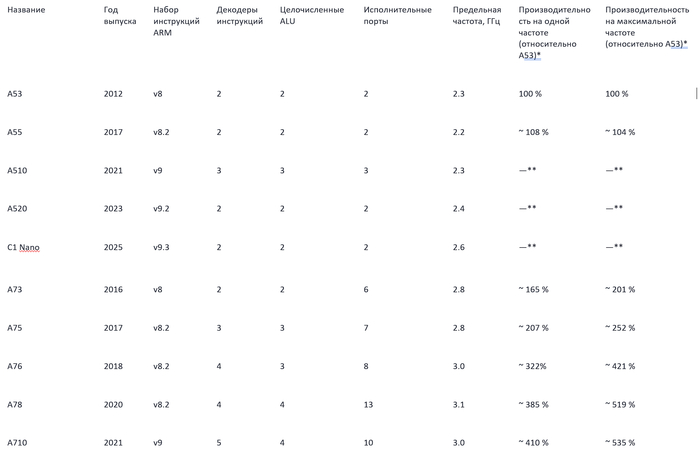
Таблица №2
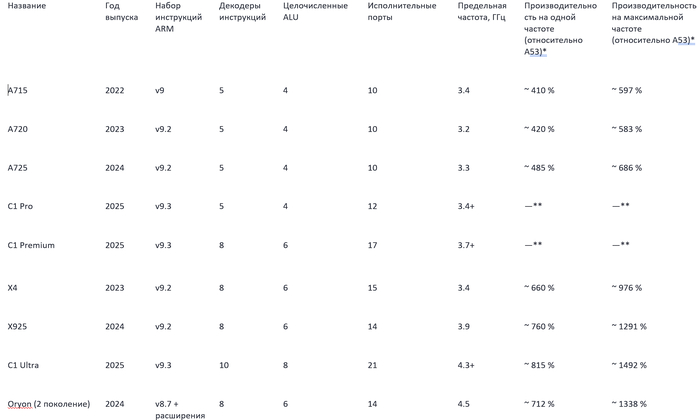
*на основе результатов Geekbench 6 Single Score
**информация отсутствует, так как эти ядра не используются в качестве «больших»
Для наглядности представим данные об относительной производительности этих ядер на следующем графике.
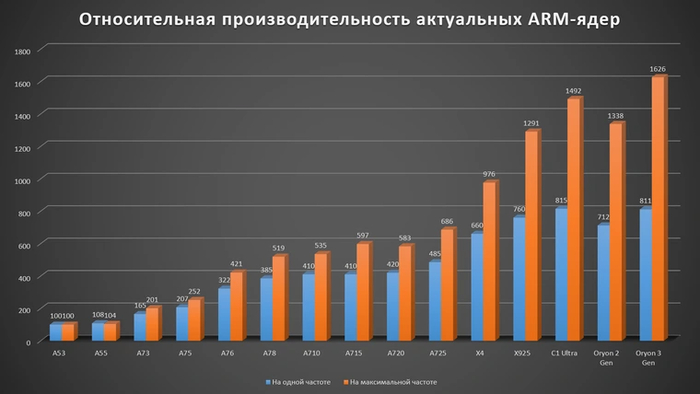
Как можно видеть, разница в производительности между последними топовыми ядрами и устаревшими решениями, которые все еще используются в бюджетных смартфонах и планшетах, просто колоссальная. И это только однопоток. В сложных задачах, где используется множество потоков, она может быть больше еще в пять-восемь раз.
Поэтому при выборе гаджета важно понимать, какие ядра в нем установлены и хватит ли их для комфортного использования устройства в ваших задачах. Разработчики SoC могут комбинировать разные типы ядер, но ведущую роль в оценке скорости работы чипа всегда играет их наиболее быстрый вид.
Условно весь ассортимент актуальных ARM-ядер можно поделить на следующие категории:
A53, A55, A73, A75 — если старшими в процессоре устройства являются одни из этих ядер, то оно относится к разряду самых бюджетных решений уровня «для позвонить и мессенджеров хватит».
A76, A78, A710 — «рабочие лошадки» бюджетного сегмента. Позволяют с комфортом решать большинство задач и играть в несильно требовательные игры. Однако для тяжелых нагрузок уже не годятся.
A715, A720, A725, C1 Pro — серьезные ядра, являющиеся основными в новых SoC среднего сегмента. Обеспечивают высокую производительность, которой достаточно для любых задач.
X4, X925, C1 Premium/Ultra, Oryon — топовые решения, обеспечивающие наивысшую пиковую производительность. Их наличие максимально сокращает время запуска и загрузки «тяжелых» приложений и игр.

Выбор рисунка зависит от типа маски-трафарета. Там, где соединения идут преимущественно горизонтально, лучшим образом подходит одна схема освещения. Там, где вертикально — вторая, а для круглых межслойных соединений — третья.

Здесь вновь можно вспомнить аналогию с тонкой ручкой. Например, чтобы рисовать точечные межслойные соединения, свет от «ручки» должен быть направлен строго вниз. А для создания прямых непрерывных линий нужно наклонить ее под углом.

Теперь посмотрим, как происходит работа с фотомаской — шаблоном-трафаретом одного слоя будущих чипов.
С помощью подвесной транспортной системы маска в условиях вакуума загружается в EUV-машину. Там первым делом сверяется ее штрих-код и происходит проверка на дефекты. Пройдя ее, положение маски выравнивается по специальным меткам на краях с точностью до нанометра.

Проверенная маска закрепляется на столике визирной сетки. В процессе работы машины он движется вдоль лучей EUV-света на очень высокой скорости, линия за линией проецируя рисунок с маски на кремниевую пластину.

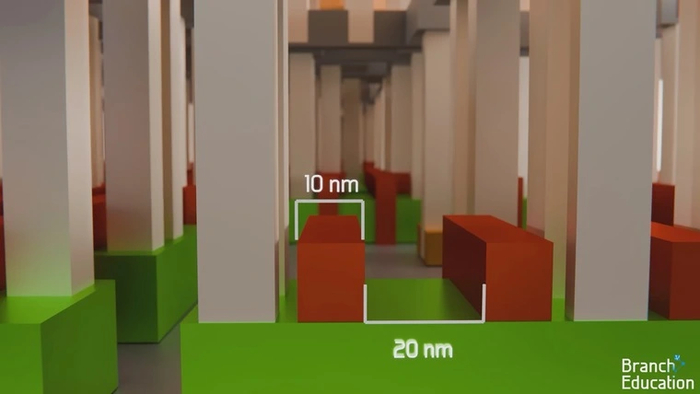
Поверхность маски напоминает уже описанный нами многослойный отражатель Брэгга. Но в местах, где рисунок отсутствует, используется светопоглощающий материал. Размер точки этого материала очень мал — примерно 10х10 нм. Габариты самой маски составляют 104х132 мм, поэтому разрешение ее рисунка получается очень высоким.

С помощью системы зеркал рисунок от маски масштабируется, попадая на кремниевую пластину в уменьшенном виде. Каждая маска может содержать от одного до нескольких шаблонов будущих чипов — это зависит от их размера. Например, на ней поместится один крупный графический процессор, два менее габаритных центральных процессора, или сразу 12 чипов оперативной памяти.

В соответствии с размерами чипов меняется и их общее количество, умещающееся на одной пластине. Крупных графических процессоров получится 90, центральных процессоров — 185, а чипов памяти — почти 1000.

Маска для будущих чипов не должна иметь ни малейшего дефекта. Если вспомнить нашу аналогию с библиотекой, то ни в одной ее книге среди 21 миллионов страниц текста не должно ни грамматической ошибки, ни даже лишнего изгиба буквы — иначе это повредит каждую заготовку чипа на пластине.

Настала очередь рассмотреть работу с кремниевыми пластинами. В контейнере FOUP они транспортируются на литографический кластер, состоящий из трекового инструмента и EUV-машины.

В условиях вакуума пластина перемещается из контейнера в трековый инструмент. В первой его области наносится слой фоторезиста, а затем происходит перемещение во вторую область — там, где резист нагревается и высушивается.

С помощью роботизированного манипулятора через вакуумный шлюз пластина переносится в EUV-машину.

Данная система получила название TwinScan. Она позволяет за раз транспортировать две пластины: пока одна обрабатывается, вторую за это время можно загрузить на столик и выровнять с точностью до нанометра.
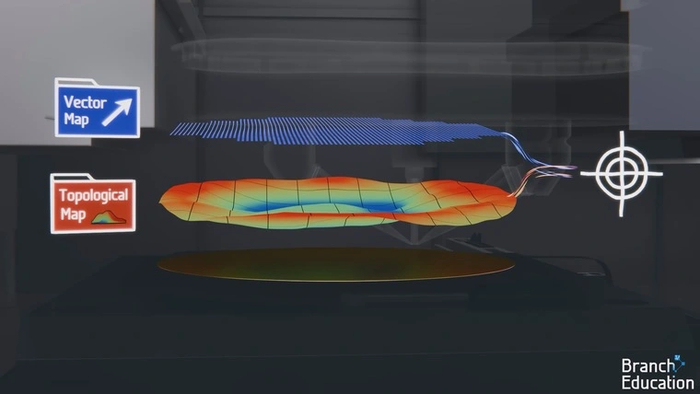
Чтобы убедиться, что формируемый слой идеально совмещен с предыдущим, пластина тщательно проверяется с помощью меток совмещения и датчиков выравнивания. На основе этой информации создается высокоточная двухмерная карта смещений.

Затем датчики выравнивания используют отраженный свет для измерения высоты по всей поверхности пластины. Таким образом, формируется еще и топологическая карта пластины, позволяющая идеально сфокусировать на ней EUV-лучи.
Подобная точность — важная составляющая производственного процесса. Размеры самых маленьких элементов транзисторов составляют менее 10 нм, поэтому даже погрешность в пару нанометров может привести к нарушению их электрических соединений со следующим слоем.
Когда чипы будут готовы, пластина будет разрезана по их размерам. Поэтому между рисунками на пластине должны оставаться небольшие промежутки. Когда нанесение одной копии рисунка закончено, затвор столика визирной сетки временно перекрывается — до тех пор, пока столик с пластиной не сдвинется и не примет положение для печати следующей заготовки.

Напоследок расскажем, как устроен фоторезист. Он представляет собой синтетическую смолу, смешанную с фоточувствительным органическим красителем — сенсибилизатором. Когда фотоны EUV-света попадают на смолу, высвобождаются электроны с высокой энергией. Под их воздействием сенсибилизатор превращается в кислоту, делающую структуру смолы слабее.

В результате на областях, подвергшихся EUV-излучению, резист легко становится легко смываемым с помощью проявляющей жидкости.

Важно то, что резист не разрушается кусками: ослабевает лишь та его часть, в которую непосредственно проникли лучи света. Это позволяет создавать элементы транзисторов и их соединений с четкими контурами.


Далее пластина вновь перемещается в трековый инструмент. Здесь модифицированный резист смывается с ее поверхности с помощью растворителя, а для затвердевания оставшегося резиста еще раз применяются нагрев и высушивание.

После формирования рисунка пластина отправляется в другие машины. Области без затвердевшего резиста подвергаются травлению, и на них распыляются различные химические вещества — одни заполняют собой образовавшиеся канавки, а другие образуют основу для следующего слоя.

Данный процесс повторяется несколько раз, пока поверх первого слоя не образуется множество дополнительных слоев соединений. Именно через них транзисторы чипов будут «общаться» друг с другом. Толщина этих соединительных проводов зависит от высоты слоя: внизу с транзисторами контактируют самые тонкие, а наверху располагаются самые крупные.

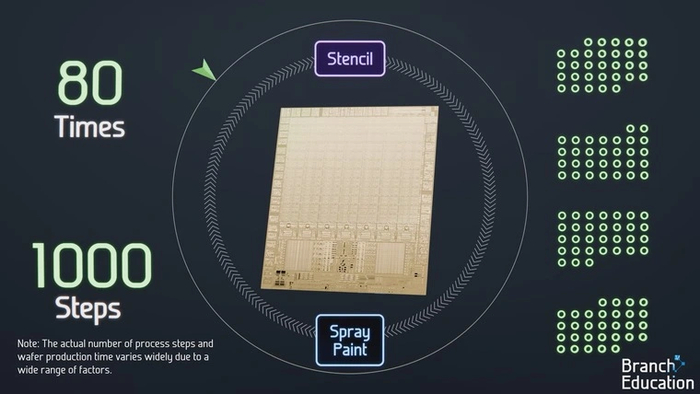
Циклы построения слоев повторяются десятки раз, а количество их отдельных этапов приближается к тысяче. Поэтому общее время, необходимо для создания одной пластины с чипами, достигает четырех месяцев.
Транзисторный слой современных чипов формируется с помощью машин EUV (Extreme UltraViolet), которые работают с экстремально короткими ультрафиолетовыми волнами длиной всего 13 нм.

Верхние соединения чаще всего создаются с помощью машин DUV (Deep Ultra Violet), которые работают с более длинными ультрафиолетовыми волнами — обычно от 193 до 365 нм.

Машины DUV появились еще в 2000-х годах и обходятся намного дешевле, чем более передовые EUV. Поэтому некоторые простые чипы, для которых не требуются тонкие техпроцессы производства, до сих пор производятся только их силами.
Давайте заглянем внутрь EUV-машины. Она состоит из пяти основных компонентов: источника света (Source), осветителя (Illuminator), манипулятора и столика визирной сетки (Reticle Handler/Stage), проекционной оптики (Projection Optics), а также манипулятора и столика пластин (Wafer Handler/Stage).

Ключевой компонент — это источник экстремального ультрафиолетового света (EUV). Почему используется именно такой свет, и что он дает?
Представьте, что вы переносите буквы с трафарета на бумагу с помощью толстого маркера. Если закрашивать крупные буквы, они будут выглядеть четко. Но стоит закрасить несколько мелких букв рядом, и краска расплывется, не давая их прочитать. А вот если повторить тот же процесс с помощью тонкой ручки, то даже мелкие буквы перенесутся четко и будут читаемыми.

EUV-свет с длиной 13 нм — это та самая тонкая ручка, которая позволяет копировать рисунки с линиями толщиной около 10 нм.

Если использовать свет с большой длиной волны, то он не сможет проникнуть в микроскопические отверстия нашей маски-трафарета, и узор ее рисунка потеряется.

В отличие от него, экстремально короткие ультрафиолетовые волны беспрепятственно проходят через маску, четко перенося на пластину все детали и контуры.

Ультрафиолетовое излучение такой длины не встречается в природных источниках света, поэтому создается искусственно. Для этого используется сложная система из двух лазеров и нескольких усилителей, которые установлены под EUV-машиной.

С помощью зеркал импульсы лазера проходят в контейнер-источник, где на их пути распыляются микроскопические шарики из олова. Первый импульс мощностью в 5 кВт превращает олово в жидкую каплю. Второй импульс имеет мощность в 25 кВт — при взаимодействии с ним капля испаряется, переходя в состояние раскаленной плазмы. В процессе этого происходит выброс электронов, благодаря которому и возникает EUV-свет.

Олово для этой операции хранится в специальной емкости и поддерживается в расплавленном состоянии. С помощью системы шлангов оно попадает в пьезоэлектрический распылитель, который за счет высокого давления азота внутри своего резервуара обеспечивает подачу тонкой и равномерной струи.

Когда капля олова попадает в рабочую область контейнера, ее траекторию отслеживает несколько высокоскоростных камер. Эта информация передается приводам зеркал, цель которых сдвинуть отраженный лазерный луч так, чтобы он попал точно в каплю.

Для генерации EUV-света нужной интенсивности выстрелы по каплям совершаются около 50 тысяч раз в секунду. Чтобы поддерживать равномерный темп излучения, система может пропускать некоторые капли мимо лазера — они попадают в специальный отвод.

Излученный свет собирается в пучок с помощью первого зеркала, называемого коллектором. Он направляется в промежуточный фокус — микроскопическое отверстие, которое пропускает только EUV-лучи и отсеивает более длинные.
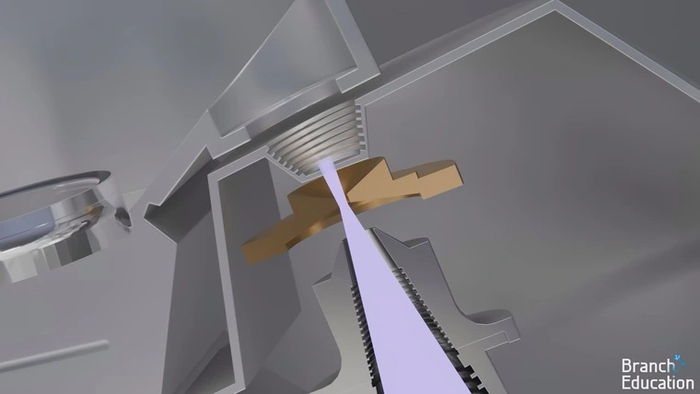
Затем луч EUV-света попадает в осветитель — систему из нескольких фацетных зеркал, которые рассеивают его на более широкий пучок из множества линий.

Пучок света проецируется на маску, а прошедшие через нее лучи с помощью еще одного массива зеркал отправляются в конечную цель путешествия — на поверхность кремниевой пластины.

Экстремально глубокий ультрафиолет отличается от видимого света многими свойствами. Например, он сразу поглощается молекулами воздуха, поэтому внутри его пути в EUV-машине всегда соблюдается вакуум.

Более того, EUV поглощается стеклом и почти всеми прочими материалами. Поэтому для фокусировки и передачи такого света используются зеркала, а не линзы. Но и обычные зеркала для этой цели тоже не подходят. В EUV-машине используются специальные зеркала, называемые отражателями Брэгга. Они состоят из десятков чередующихся слоев кремния и молибдена, каждый из которых имеет толщину всего в несколько нанометров. Когда EUV-луч попадает на поверхность такого отражателя, то только 3 % отражается от одного слоя, а оставшийся свет проходит насквозь. Благодаря множеству слоев луч отражается от каждого, поэтому в сумме одно зеркало способно перенаправить чуть более 70 % попавшего на него света.

В оптической системе EUV-машины более десяти зеркал, поэтому часть исходного потока света теряется после каждого переотражения. В результате до кремниевой пластины доходит менее 10 % от его изначальной яркости. Именно поэтому первоначальный свет от источника должен быть максимально ярким.

Другой особенностью работы с EUV-лучами являются фацетные зеркала. Они состоят из множества сегментов, наклон каждого из которых управляется независимо с помощью системы с миниатюрным электроприводом.

За счет этого можно создавать из точечного EUV-света сложные рисунки освещения.
В виду ограничения фотоматериалов
ПРОДОЛЖЕНИЕ СЛЕДУЕТ...

В основе любой электроники, которой мы пользуемся ежедневно, лежат микрочипы из миллиардов транзисторов. Их существование стало возможным благодаря фотолитографии — сложному процессу, позволяющему наносить огромное количество логических элементов на миниатюрные кремниевые пластины. Как работает современное фотолитографическое производство, и как оно устроено внутри?
ПК, ноутбуки, смартфоны, планшеты, громоздкие автомобили и миниатюрные смарт-часы. Внутри этих устройств скрывается несколько разновидностей современных микрочипов: центральные и графические процессоры, системы на чипе (SoC), а также чипы оперативной (DRAM) и флеш-памяти (NAND).

Каждый из таких чипов состоит из миллиардов миниатюрных транзисторов, соединенных вместе несколькими слоями токопроводящих дорожек.

Самые мелкие элементы подобных транзисторов имеют размер около 10 нм — это всего 45 атомов кремния.
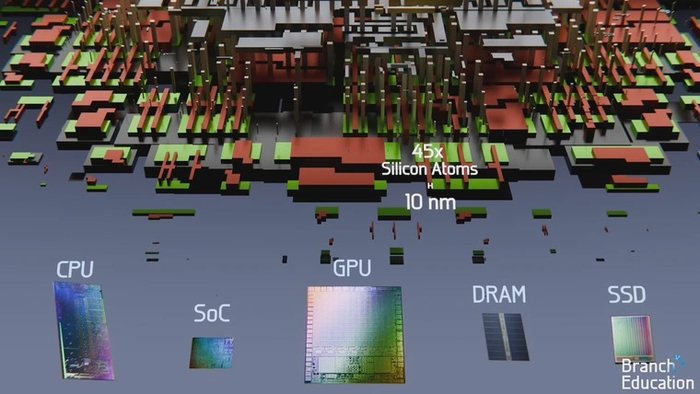
Чтобы производить такие сложные чипы, используется сложная последовательность фотолитографических процессов. Каждый из них состоит из нескольких этапов, которыми занимается специализированная машина-установка.

Принцип фотолитографии можно сравнить с копировальным аппаратом. С ее помощью на кремниевую подложку переносятся микроскопические рисунки элементов транзисторов и слоев соединяющих их дорожек.

Инструменты для фотолитографии постоянно совершенствуются, позволяя копировать все более мелкие элементы. Тут можно привести сравнение с печатью текста: чем тоньше и прогрессивнее технологический процесс, тем меньшим шрифтом можно напечатать буквы (то есть — транзисторы чипа).

Ключевыми установками для производства современных микрочипов являются машины, работающие с экстремально глубоким ультрафиолетовым светом — EUV (Extreme UltraViolet).
Начнем обзор с принципа работы EUV-машины. Первым делом в нее помещается фотомаска — трафарет транзисторного слоя будущего чипа.

Затем в машину загружается предварительно обработанная круглая пластина из кремния диаметром 300 мм.

С помощью источника ультрафиолетового света и системы зеркал шаблон с маски переносится на небольшой кусочек пластины. После этого пластина сдвигается, и процесс повторяется снова и снова — до тех пор, пока она полностью не заполнится «рисунками» транзисторного слоя будущих микрочипов.

На обработку одной пластины EUV-машина тратит около 18 секунд — за это время шаблон переносится около сотни раз. Затем подается следующая пластина, и весь процесс повторяется снова. После окончания процедуры заготовка отправляется в другую разновидность фотолитографической машины, где поверх транзисторов аналогичным образом формируются несколько слоев их соединений. Если заглянуть внутрь готового чипа, можно будет увидеть вот такой лабиринт из них.

Здесь можно привести аналогию с книгой. Слои соединений — это страницы с буквами среднего размера, а транзисторный слой — страница с самыми мелкими. Поэтому для «печати» соединений в ряде случаев может использоваться более простая фотолитография в глубоком ультрафиолете (DUV — Deep Ultra Violet).
Насколько мелки элементы транзисторного слоя? Представьте, что толщина штриха каждой буквы составляет 13 нм. Тогда слово «cat» будет иметь размер в 240х155 нм.

Страница подобного текста будет иметь размер эритроцита. А одна глава книги займет область, схожую по размерам с пылинкой.

С таким шрифтом на площади графического процессора топовой видеокарты уместятся семь книг о Гарри Поттере, все творчество Стивена Кинга, весь текст английской Википедии, а также все книги из крупной городской библиотеки. Система фотолитографии копирует подобный рисунок с «текстом» из транзисторов очень быстро — менее, чем за одну секунду.
Рассмотрев принцип формирования микрочипов, совершим виртуальную экскурсию на их производство. Кремниевые пластины попадают сюда сложенными в специальные контейнеры FOUP.

В процессе производства чипов эти контейнеры переносятся от машины к машине с помощью автоматизированной подвесной транспортной системы.

Прибыв к нужной машине, контейнер опускается. Пластины поочередно выгружаются из него для той или иной обработки — нанесения, засвечивания или удаления материала.

После завершения одного процесса пластины вновь попадают в FOUP и переносятся к следующей машине. Так продолжается до тех пор, пока не будут «выстроены» все слои будущих чипов.

Шаги этого процесса можно сравнить с распылением краски на бумагу через трафарет: она остается там, где в трафарете присутствуют отверстия, и не попадает туда, где этих отверстий нет.

А после распыления нескольких слоев краски разных цветов получается итоговое цветное изображение.

В нашем случае вместо слоев рисунка на масках-трафаретах находятся схемы слоев транзисторов и соединяющих их дорожек, которые вместо бумаги переносятся на пластину из кремния.

В этом процессе участвуют разные типы установок. Одни осаждают материалы на кремний или смывают их с него (Spray Paint) — подобно тому, как распыляется или смывается краска. А EUV- и DUV-машины выполняют роль трафаретной печати (Stencil), благодаря которой перед нанесением краски на пластины переносятся контуры нужного рисунка.

Перейдем к тому, как создаются слои чипа. Сначала кремниевая пластина поступает в установку, называемую трековым инструментом. Здесь на нее добавляется светочувствительный материал — фоторезист, который равномерно распределяется по поверхности пластины за счет вращения центрифуги.

Чтобы резист затвердел, пластина нагревается и высушивается.

По окончанию процедуры пластина переходит в EUV-машину. Здесь ультрафиолетовый свет пропускается через маску-трафарет, а затем с помощью системы зеркал уменьшается и проецируется на малую область пластины.

На всех участках, где свет попал на пластину, резист под действием ультрафиолета модифицируется — таким образом, рисунок маски «отпечатывается» на ее поверхности. Затем пластина сдвигается, и процесс повторяется сотни раз до ее полного заполнения этими отпечатками.
В виду ограничения фотоматериалов
ПРОДОЛЖЕНИЕ СЛЕДУЕТ...
После этого выполняются расчеты для обнаружения пересечения луча и полигонов — вместо миллиардов операций при обычном подходе здесь их требуется всего шесть.

Несмотря на все ухищрения, для быстрых расчетов трассировки все также требуется мощное вычислительное оборудование. Поэтому видеокарты, поддерживающие ее, оснащаются тысячами шейдерных процессоров и специализированными вычислительными блоками — RT-ядрами.

Шейдерные процессоры выполняют арифметические операции, в то время как RT-ядра разработаны и оптимизированы именно для операций трассировки лучей.

Внутри RT-ядер находится два вычислительных движка. Первым начинает работу движок, занимающийся поиском пересечений лучей с объемами-коробками BVH.
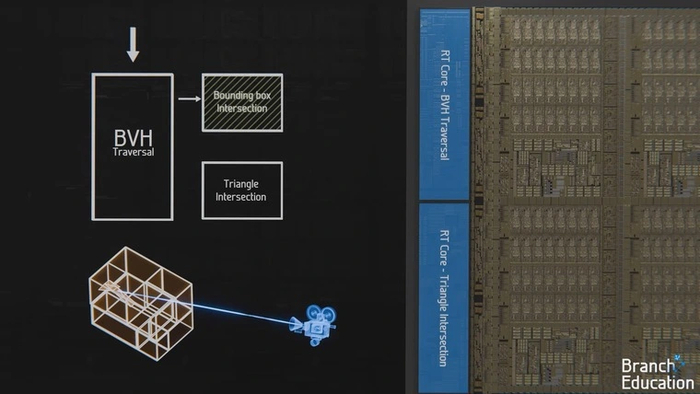
Когда находится самая маленькая коробочка, пересекающая луч, в дело вступает второй движок. Он ищет пересечения лучей с полигонами.
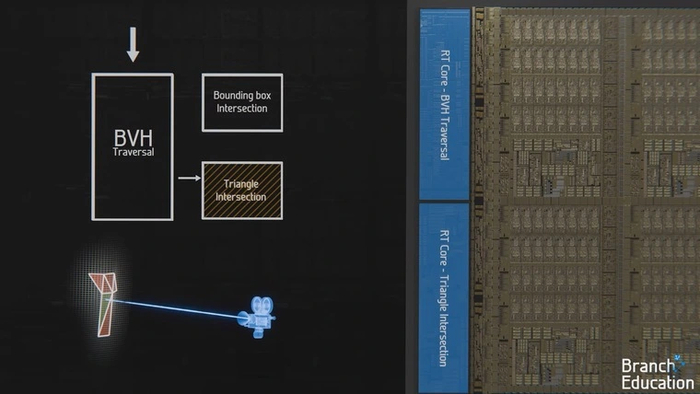
Как и шейдерные процессоры, RT-ядра работают параллельно друг с другом. На современных видеокартах это позволяет обрабатывать несколько миллиардов лучей в секунду, а общий счет выполненных операций при этом достигает триллионов. Например, NVIDIA GeForce RTX 3090 родом из 2022 года выполняет за одну секунду до 36 триллионов операций. Тогда как самый мощный суперкомпьютер 2000 года, полагающийся на грубую вычислительную мощность центральных процессоров, за то же время осуществлял лишь 12,3 триллиона.

Трассировка пути — наиболее продвинутый способ получения компьютерных изображений. Но из-за ее высоких требований в играх пока более распространена обычная трассировка лучей. Оба способа имеют схожую основу, но трассировка лучей обеспечивает меньшую реалистичность освещения взамен на гораздо более скромные требования к оборудованию.
Для реализации трассировки лучей существует несколько техник. Рассмотрим две самые распространенные. Первый вариант схож с трассировкой пути, но имеет некоторые упрощения. Сначала для моделей сцены создаются дубликаты низкого разрешения с малым количеством полигонов.

Кадр с этими моделями просчитывается вне экрана, чтобы получить карту освещенности поверхностей. А затем полученная карта накладывается на кадр высокого разрешения, выводимый на экран.
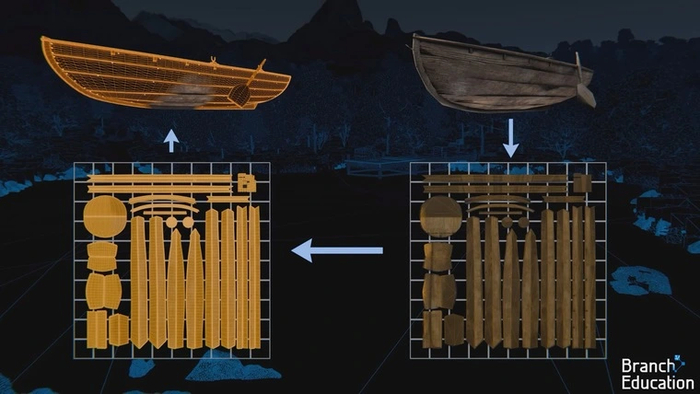
Это позволяет хорошо интерполировать непрямое освещение, не прибегая к огромному количеству вычислений. Данный способ является одним из методов трассировки, который используется системой освещения Lumen в графическом движке Unreal Engine 5. Второй вариант техники называется трассировкой лучей в экранном пространстве. Тут используется совершенно другой подход на основе трех составляющих: изображения, полученного с помощью традиционного рендеринга, карты глубины кадра и карты нормалей. Из отрендеренного изображения берется информация о цвете объектов. Карта глубины показывает, насколько далеко они находятся от камеры.

В свою очередь, карта нормалей сообщает, в какую сторону полигоны отражают свет.

Когда в процессе трассировки луч попадает на отражающую поверхность, его дальнейшее распространение продолжается в соответствии с этой информацией. Например, попав в озеро, лучи отразились в сторону деревьев — значит на поверхности озера появится искаженное изображение последних.

Главная проблема подобного подхода в том, что он может использовать только отрендеренные кадры с экрана. То есть, когда деревья исчезнут из поля зрения игрока, пропадет и их отражение в озере. Такую технику трассировки лучей используют многие игры прошлых лет, в том числе — Cyberpunk 2077.

Трассировка пути — продвинутая технология построения изображений в компьютерной графике. Она широко применяется для создания реалистичных сцен в фильмах, и все больше становится популярной в новых играх для ПК и консолей. Как работает эта технология, и в чем ее отличия от более распространенной трассировки лучей?
Компьютерная графика, используемая в современном кинематографе, основана на одной из техник трассировки лучей — трассировке пути (Path Tracing). Этот алгоритм появился в далеком 1986 году, но из-за своей сложности лишь спустя 30 лет начал массово использоваться для создания графики в фильмах.
Чтобы понять, почему все это время трассировка пути оставалась неосуществимой, ознакомимся с основами построения подобной картинки. Сначала 3D-художники вручную моделируют форму объектов в сцене, а программное обеспечение для рендера разбивает их на мелкие треугольники — полигоны.

Затем на модели накладываются текстуры, которые симулируют материалы определенного цвета и типа — например, шероховатые, гладкие или стеклянные.

Готовые объекты и источники света: солнце, небо, фонари, размещаются в нужных положениях на 3D-сцене. После этого добавляется виртуальная камера и запускается процесс рендеринга — благодаря ему картинка в кадре визуализируется в виде привычного 2D-изображения.

С помощью трассировки пути имитируются отражения света от различных материалов. К примеру, попав на матовую красную черепицу крыши, часть света ей будет поглощена, а другая часть — отразится красным. Отраженный свет от каждого объекта попадает в виртуальную камеру, внося свой вклад в создание изображения.

Для образования каждой точки конечной картинки осуществляется несколько тысяч подобных расчетов. А для формирования одного кадра изображения с разрешением 4К их потребуется несколько миллиардов.

Именно из-за этого долгое время создание изображений с использованием трассировки пути было очень медленным процессом. Например, в 2016 году рендерингом фильмов «Зверополис» и «Моана» занималась ферма из тысяч серверов, которые производили вычисления в течении нескольких месяцев — и это всего для двух часов анимации.
Для начала ознакомимся с принципом создания изображения при трассировке пути. Этот алгоритм относится к виду вычислений, которые очень хорошо распараллеливаются: точки картинки независимы друг от друга, поэтому тысячи лучей для каждой из них можно рассчитывать одновременно.

Если показать на картинке траектории всех лучей, которые просчитываются для этой сцены, то она заполнится огромным количеством линий. Поэтому рассмотрим данный процесс на примере одной точки. Первый луч испускается из ее центра и попадает на полигон какого-либо объекта в кадре.

Базовый цвет точки формируется с помощью нескольких лучей, которые попадают рядом с центральным — для этого все их цвета усредняются. Подобные лучи называются первичными.

В результате такого подхода формируется изображение с правильной перспективой.

Мы рассмотрели, как цвет полигонов передается точкам виртуального кадра. Но для получения реалистичной сцены нужно просчитать глобальное освещение объектов — ведь яркость и оттенок цвета каждой точки зависит именно от него.

Для этой цели комбинируются два вида расчетов: прямого (Direct) и непрямого (Indirect) освещения. При первом виде вычислений просчитываются лучи непосредственно от источников освещения — солнца, неба и ламп. Они называются теневыми.

Теневые лучи отражаются от всех объектов сцены, попутно приобретая характер и окраску от их материалов. Таким образом все поверхности, на которые попадает прямое освещение, становятся источниками непрямого. Отраженный свет проникает во все области кадра. В том числе в те, которые закрыты преградами от лучей прямого освещения. На примере ниже можно увидеть, как освещенная зеленая точка на стене отражает свой свет на синюю точку столба, находящуюся в тени.
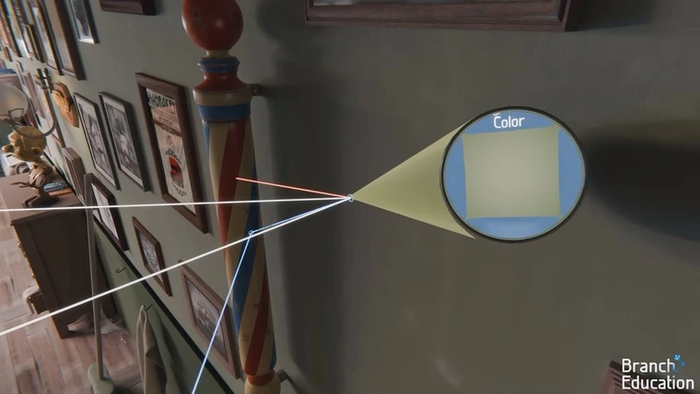
Этот луч, проходящий между двумя точками, называют вторичным. Если при первом отражении он снова попадет в тень, то от него будут просчитаны дополнительные лучи. Так будет продолжаться либо до попадания на освещенную прямым светом точку, либо до достижения лимита отскоков, при котором дальнейший поиск траектории луча прекращается.

Вместе с траекториями лучей от источников прямого освещения это создает большое количество вычислений. Например, в кадре ниже для получения 20 первичных лучей необходимо рассчитать почти сотню вторичных и теневых.

Благодаря непрямому освещению реалистично просчитывается не только изменение яркости точек, но и их взаимное влияние на цвет друг друга. К примеру, если расположить рядом со столбом красный воздушный шар, то за счет непрямого освещения в его оттенок окрасится и тень от столба.

Не менее важно и то, что направление распространения вторичных лучей зависит от свойств материала объекта. Если он идеально гладкий, то угол падения луча будет равен углу его отражения — благодаря этому поверхность будет выглядеть зеркальной. А от шероховатого материала того же цвета лучи будут отражаться в случайные стороны — из-за этого он, как и положено, будет отображаться матовым.

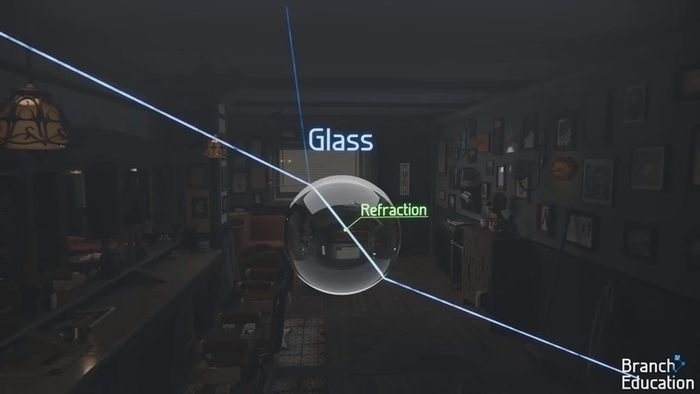
В случае, если материалом выступает стекло, то будет просчитываться не только отражение света, но еще и его преломление при прохождении насквозь.
Сложность трассировки пути зависит от количества источников света, количества лучей на точку и предельно допустимого числа их дополнительных отскоков. У сцены из первого примера с замком используется четыре источника света, тысяча лучей на точку и 12 отскоков. Чтобы визуализировать один ее кадр в 4К, нужно просчитать примерно 400 миллиардов лучей.

А для создания всего одной секунды такого видео их понадобится просчитать уже около триллиона. Именно поэтому в течение нескольких десятилетий трассировка пути для фильмов считалась невозможной.
Чтобы достичь приемлемой производительности, в современных играх трассировка пути реализована намного проще — один-два луча на точку и от одного до четырех отскоков. Но даже при таких параметрах и базовом разрешении Full HD для комфортной игры каждую секунду видеокарте понадобится просчитывать около полумиллиарда лучей.
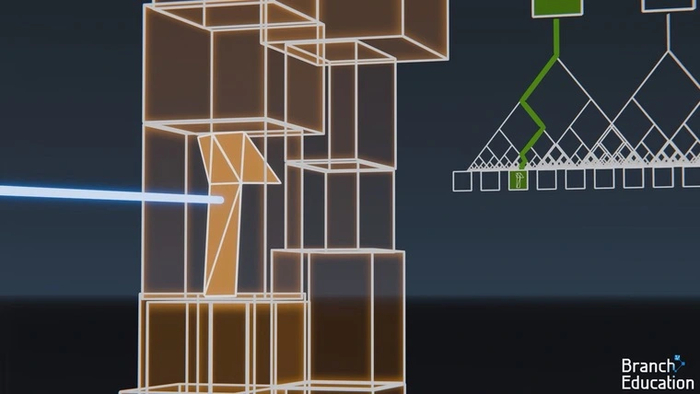
Еще одна ключевая трудность при трассировке пути — узнать, на какой именно полигон луч из точки попадает первым, чтобы определить ее основной цвет. В случае, если полигонов десятки или сотни, можно воспользоваться вычислением траектории луча с помощью математических уравнений. Но в современных сценах их миллионы, поэтому этот способ потребует огромных вычислительных ресурсов. Чтобы упростить данный процесс, используется иерархия ограничивающих объемов (Bounding Volume Hierarchy, BVH). При таком подходе сцена разделяется на виртуальные объемы-коробки, в каждой из которых оказывается одинаковое количество полигонов.
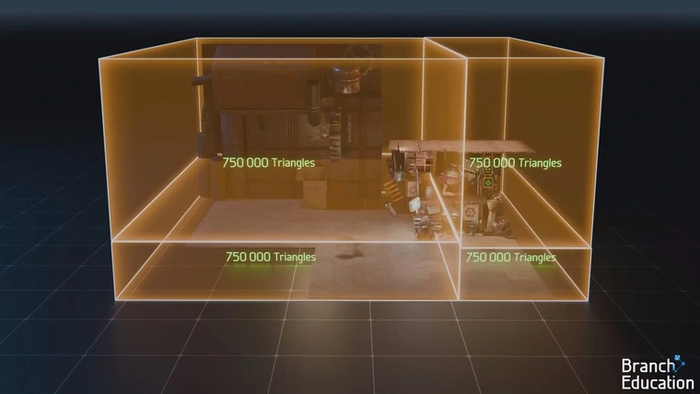
Коробки делятся надвое до тех пор, пока в каждой из них не останется всего несколько полигонов (обычно от 4 до 32). В нашем примере сцена состоит из трех миллионов полигонов, которые «раскладываются» в полмиллиона небольших коробочек.

Положение каждой коробки в пространстве выровнено строго по осям координат. Когда луч начинает свое путешествие из точки, его направление сравнивается с координатами первой пары больших коробок. Коробка, которую он не пересекает, исключается из расчетов — как и все более мелкие, на которые она поделена.
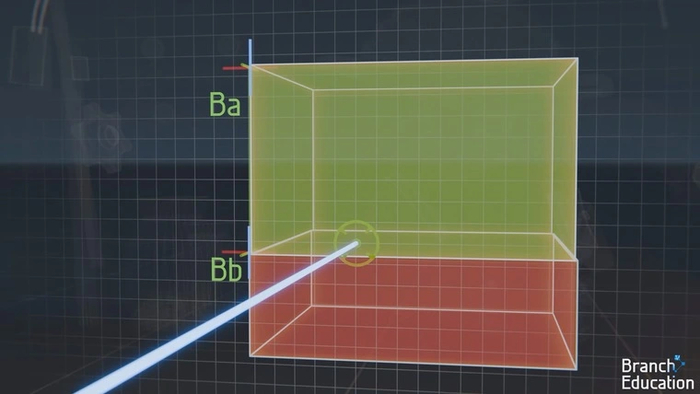
Затем направление луча сравнивается с координатами двух меньших коробок, на которые разделена исходная. И так до тех пор, пока луч не достигнет самой маленькой коробки.
В виду ограничения фотоматериалов
ПРОДОЛЖЕНИЕ СЛЕДУЕТ...
