


Наука
6 постов
6 постов

8 постов

10 постов

3 поста

6 постов

4 поста

1 пост

4 поста

1 пост
Сегодня, 16 марта 2026 года, мы отмечаем ровно 100 лет одному из самых абсурдных, смешных и одновременно великих событий в истории человечества. Ровно век назад стартовала первая в мире ракета на жидком топливе.
Но самое смешное в этой истории — не сам полет, а то, как один упрямый чувак с паяльной лампой эпично унизил самых заносчивых медиа-экспертов своего времени.
Знакомьтесь: Роберт Годдард. Гений-одиночка, которого вся Америка считала поехавшим фантазером:

Роберт Годдард и его первая ракета на жидком топливе перед историческим стартом 16 марта 1926 года. Авторы: Esther C. Goddard. Источник: Great Images in NASA.
На черно-белой фотографии запечатлен Роберт Годдард в зимнем пальто и шляпе, стоящий на заснеженном поле. Одной рукой он держится за пусковую раму, внутри которой установлена тонкая ракета из металлических трубок с необычным расположением двигателя в верхней части. Авторы: Esther C. Goddard. Источник: Great Images in NASA.
За шесть лет до исторических событий, в 1920 году, уважаемая (и очень надменная) газета The New York Times выпустила разгромную редакционную статью, где раскатала Годдарда в пух и прах за его идею полета на Луну. Журналисты писали:
«Профессору не хватает базовых знаний, которые ежедневно вдалбливают в средних школах! В космосе вакуум, там нет воздуха, от чего его ракете отталкиваться?!»
Газетчики радостно прилепили ему кличку «Лунный сумасшедший», и все подхватили: ха-ха-ха, дурачок, иди учи физику.
Что сделал Годдард? Он не пошел ругаться в Твиттер (за неимением оного). Он молча пошел на задний двор фермы своей тёти Эффи в Массачусетсе и собрал из водопроводных труб, бензина и жидкого кислорода трехметровую ракету. Скромно назвал её «Нелл».
Конструкция была… специфичной. Годдард тогда думал, что ракета полетит стабильнее, если двигатель будет тащить баки за собой — ну, как лошадь тянет телегу. Поэтому двигатель был сверху, а баки внизу.
А теперь оцените уровень техники безопасности 1926 года. Запалом служили обычные спичечные головки. Чтобы поджечь эту адскую трубу с топливом и не отправиться к праотцам, ассистент Годдарда привязал паяльную лампу к длинной палке.
Процедура старта: мужик тянется палкой со струей огня к верхушке ракеты, поджигает спички, бросает палку и со всех ног бежит прятаться за хлипкую деревянную дверь, которую заботливо подперли бревном. Сам Годдард сидел в сугробе за куском листового железа, как в окопе.
«Пламя вырвалось, стоял непрерывный рев…» — романтично записал позже Годдард в дневнике. — «Казалось, она сказала: «Я тут уже достаточно побыла, пожалуй, полечу куда-нибудь ещё»».
И она полетела!
На целых 2,5 секунды.
На жалкие 12,5 метров в высоту.
Прямо в промёрзшую капусту тёти Эффи, рухнув в 56 метрах от старта со скоростью 96 км/ч.
Тётя Эффи до сих пор не оставила комментариев (история умалчивает, отхлестала ли она племянника полотенцем за сожженный урожай). Местные репортеры тоже промолчали — то ли Годдард хорошо всё убрал, то ли журналистам было лень тащиться за город смотреть на какую-то дымящуюся трубу в грядках.
Годдард умер в 1945-м, так и не дождавшись прижизненного триумфа. Журналистам понадобилось целых 43 года медийного позора с момента того самого запуска в капусту, чтобы признать, что физику за 8 класс прогуливали именно они.
17 июля 1969 года — в день, когда ракета миссии «Аполлон-11» уже летела к Луне (на секундочку, благодаря его чертовым идеям!) — The New York Times тихонько, в самом незаметном уголке газеты, напечатала крошечное извинение:
«Дальнейшие исследования подтвердили… ракета может работать в вакууме. Газета сожалеет об ошибке».
Никакого «Прости, Роберт, мы сломали тебе жизнь и затормозили науку». Никакого упоминания высадки на Луну. Просто сухое канцелярское «ну ладно, мы не знали третий закон Ньютона, бывает». Классика диванной аналитики!
Сегодня, ровно 100 лет спустя, когда огромный Starship Илона Маска красиво и итеративно взрывается над океаном, а ступени Falcon 9 буднично садятся на хвост — это всё огромный пламенный привет от дяди Роберта из 1926 года. С его капустой, спичками и паяльной лампой на палке.
Не слушайте умников в пиджаках. Делайте. Даже если ваша первая версия улетает прямиком в капусту. А если родственники начнут орать за испорченный огород — просто скажите: «Узбагойся, тёть. Через 100 лет об этом напишут в интернете».
А теперь признавайтесь: кто готов запускать свою «ракету» несмотря на хейт — ставьте «+» в комментах. А кто бы как нормальный сосед сразу вызвал полицию за взрывы на огороде — тоже пишите, интересно сравнить!
Сегодня 14 марта (3.14) — международный День числа Пи. Обычно в этот день принято публиковать пресные статьи о том, что без Пи мы не могли бы рассчитывать орбиты планет, строить круглые трубы и передавать радиоволны. Это правда, но это скучно.

Для математика Пи — это 3.1415926…, для физика — 3.14, а для сурового инженера Пи = 3. Ну а если нужно с запасом, то 4!
Число Пи — это не просто коэффициент для вычисления площади круга. Это фундаментальная «прошивка» нашей реальности, которая вылезает в местах, где ни о каких кругах не идет и речи.
Вот 4 факта о числе Пи, которые звучат как бред сумасшедшего, но являются абсолютно строгой наукой.

Каждый год энтузиасты с суперкомпьютерами соревнуются в вычислении числа Пи. Сейчас счет идет на сотни триллионов знаков после запятой. Обывателям кажется, что чем точнее мы знаем Пи, тем лучше работают наши технологии.
Но реальность суровее и прагматичнее. Инженеры Лаборатории реактивного движения NASA (JPL), которые отправляют аппараты на Марс и за пределы Солнечной системы, используют в своих расчетах всего 15 знаков после запятой (3.141592653589793).
Почему так мало? Потому что этой точности хватает, чтобы рассчитать орбиту полета через всю Солнечную систему с погрешностью в толщину человеческого мизинца.
А что, если мы захотим рассчитать длину окружности всей видимой Вселенной (диаметром около 93 миллиардов световых лет)? Нам понадобится всего 39-40 знаков после запятой. Эта точность позволит вычислить границы Вселенной с погрешностью, равной размеру одного атома водорода. Все остальные триллионы вычисленных знаков не имеют абсолютно никакого физического смысла — это просто способ протестировать вычислительные мощности процессоров.

Представьте, что вы оказались на необитаемом острове без калькулятора, но вам срочно понадобилось число Пи. Вам не нужно рисовать идеальные круги на песке. Вам понадобятся только палочки (или обычные спички).
Это знаменитая «Игла Бюффона» — один из первых в истории примеров метода Монте-Карло, открытый еще в 18 веке.
Если вы возьмете лист бумаги и расчертите его параллельными линиями так, чтобы расстояние между линиями было в точности равно длине спички, а затем начнете случайным образом бросать спички на этот лист, произойдет чудо. Вероятность того, что брошенная спичка пересечет одну из начерченных линий, строго равна 2/π.
То есть, если вы бросите 1000 спичек, и 636 из них пересекут линии, вам нужно просто разделить общее количество бросков (1000) на количество пересечений (636), а затем умножить результат на 2. 1000/636∗2≈3.1441000/636∗2≈3.144. Чем больше спичек вы бросите, тем точнее получите число Пи. Задумайтесь: в вероятности случайного падения прямого куска дерева зашита константа круга!
Это самый красивый и парадоксальный пример в кинематике (открыт математиком Григорием Гальпериным). В нем нет никаких окружностей, только движение по прямой.
Представьте абсолютно гладкий пол, на котором стоят два кубика (маленький и большой), а слева от них — абсолютно твердая стена. Трение отсутствует, все столкновения абсолютно упругие (без потери энергии). Вы толкаете большой кубик влево, в сторону маленького.
Большой кубик бьет маленький, тот отлетает в стену, отскакивает от нее, снова бьется о большой кубик (замедляя его), снова летит к стене, и так далее. Маленький кубик мечется между стеной и большим кубиком, пока большой кубик не остановится и не покатится в обратную (правую) сторону со скоростью, достаточной, чтобы маленький его больше не догнал.
А теперь самое интересное — считаем общее количество столкновений (удары кубиков друг о друга + удары маленького кубика о стену):
Если массы кубиков равны, произойдет 3 столкновения.
Если большой кубик в 100 раз тяжелее маленького — 31 столкновение.
Если в 10 000 раз тяжелее — 314 столкновений.
Если в 1 000 000 раз тяжелее — 3141 столкновение.
Если в 100 000 000 раз тяжелее — 31415 столкновений!
Умножая массу большого кубика на степени сотни, количество ударов будет с идеальной точностью генерировать цифры числа Пи! Почему? Потому что математическое пространство состояний (энергии и импульса) этой системы образует идеальную окружность.

Мы знаем, что Пи — иррациональное число. Его знаки после запятой бесконечны и никогда не образуют циклических, повторяющихся паттернов. Но поскольку число бесконечно, в нем можно найти любую конечную комбинацию цифр (как в теореме о бесконечных обезьянах).
На 762-й позиции после запятой происходит странная аномалия — там внезапно идут шесть девяток подряд (…999999…). Это место назвали «Точкой Фейнмана».
Выдающийся физик Ричард Фейнман славился своим чувством юмора. На одной из лекций он заявил, что хотел бы вызубрить число Пи ровно до 767-го знака только ради одной шутки. Он мечтал в разговоре начать перечислять знаки числа Пи по памяти, дойти до этого места и произнести скороговоркой: «…девять, девять, девять, девять, девять, девять и так далее!», намекая слушателям, что дальше идут одни девятки и число на самом деле рациональное.
Математика — это не скучные формулы в тетради. Это код, на котором написана наша Вселенная. И Пи — одна из самых удивительных строк в этом коде.
С Днем числа Пи, Пикабу!
Команда разработчиков под руководством Андрея Бреслава, российского разработчика и автора языка программирования Kotlin, представила публичную альфа-версию нового инструмента для разработчиков — CodeSpeak. Платформа позиционируется как язык программирования нового поколения, в котором инженеры пишут спецификации на английском языке, а нейросети берут на себя генерацию, тестирование и рефакторинг исполняемого кода. Полноценное внедрение инструмента позволяет сократить объем кодовой базы в проектах в пять-десять раз. Технология поддерживает интеграцию в существующие сложные проекты на Python.
ИИ-язык, созданный для людей

CodeSpeak — язык программирования нового поколения на базе LLM
В феврале 2026 года проект CodeSpeak перешел в стадию открытого альфа-тестирования, предложив инженерам концепцию поддержания спецификаций вместо исходного кода. Платформа представляет собой консольную утилиту, которая интегрируется в рабочее окружение и выступает прослойкой между разработчиком, пишущим требования на английском языке, и большой языковой моделью, которая эти требования реализует. В качестве основного движка генерации CodeSpeak использует модель Claude Opus 4.6 от компании Anthropic.
Основной метрикой эффективности CodeSpeak разработчики называют кратное уменьшение объема проекта, с которым напрямую взаимодействует человек. На примере перевода существующих open-source библиотек под управление платформы, объем исходных файлов сокращается в среднем от шести до десяти раз. Человеку остается поддерживать только короткий текстовый документ, описывающий суть алгоритма, в то время как техническая реализация скрыта под капотом системы тестирования и сборки.
В отличие от популярных чат-ботов и ИИ-агентов, CodeSpeak ориентирован не на быстрое прототипирование, а на долгосрочную поддержку продакшен-систем. Платформа изначально создавалась для работы в командах и подразумевает управление сложной архитектурой. Система умеет разворачивать проекты с нуля, однако ее главная особенность заключается в способности встраиваться в существующие кодовые базы и локально перехватывать управление отдельными модулями, не нарушая работу остального приложения.
Переход к разработке на естественном языке стал для Андрея Бреслава логичным продолжением его предыдущей работы. Во время работы в JetBrains в 2010-х годах он спроектировал язык Kotlin с целью избавить Java-разработчиков от избыточного шаблонного кода. В то время синтаксис Kotlin позволил автоматизировать множество рутинных операций на уровне компилятора, сделав программы более читаемыми.
С развитием больших языковых моделей проблема избыточности вышла на новый уровень. По мнению Бреслава, огромный пласт современного кода является очевидным не только для инженера, но и для алгоритмов машинного обучения. Если раньше компилятору требовались точные синтаксические конструкции для понимания задачи, то сегодня нейросеть способна извлечь нужную техническую реализацию из своего внутреннего представления, обученного на всем мировом открытом коде. Это делает ручное написание стандартных алгоритмов неэффективной тратой времени.
При разработке CodeSpeak команда исходила из того, что программирование исторически двигалось по пути повышения уровня абстракций: от машинных кодов к ассемблеру, затем к языкам высокого уровня вроде C и Java. CodeSpeak рассматривается как следующий шаг в этой иерархии, где уровень абстракции поднимается до естественного языка, а языковая модель выполняет роль сверхмощного компилятора, генерирующего итоговую логику.
Процесс разработки в CodeSpeak кардинально отличается от классического цикла. Точкой входа служит файл с расширением .cs.md, содержащий спецификацию конкретного модуля. Инженер описывает в нем структуру данных, логику обработки и форматы вывода. После запуска команды сборки система анализирует этот файл, собирает контекст проекта и передает план действий языковой модели.
Важнейшим элементом архитектуры платформы является автономное тестирование. В процессе сборки CodeSpeak не просто генерирует код, но и самостоятельно пишет модульные тесты для проверки заявленных в спецификации требований. Если тесты не проходят, система итеративно исправляет сгенерированный код до тех пор, пока функциональность не будет полностью соответствовать тексту. Для разработчика процесс выглядит как компиляция: на входе подается текстовое описание, на выходе получается рабочий и протестированный модуль.
В текущей версии система глубоко интегрирована с экосистемой Python и менеджером пакетов uv. Инструмент автоматически управляет виртуальными окружениями и зависимостями, позволяя создавать полноценные веб-приложения, например, на базе фреймворка Django, буквально из одного файла спецификации.
Чтобы понять, как абстрактный текст превращается в детерминированную логику, достаточно взглянуть на структуру типичного исходника CodeSpeak. На прикрепленном к статье демонстрационном видео показан процесс работы с платформой, где разработчик оперирует исключительно такими текстовыми контрактами.
Допустим, нам нужно написать конвертер для разбора сохраненных почтовых сообщений. Вместо написания десятков строк на Python разработчик создает файл eml_converter.cs.md со следующим содержимым:
# EmlConverter
Converts RFC 5322 email files (.eml) to Markdown using Python's built-in `email` module.
## Accepts
`.eml` extension or `message/rfc822` MIME type.
## Output Structure
1. **Headers section**: From, To, Cc, Subject, Date as `**Key:** value` pairs
2. **Body**: plain text preferred; if only HTML, convert to markdown
3. **Attachments section** (if any): list with filename, MIME type, human-readable size
## Parsing Requirements
- Decode RFC 2047 encoded headers (e.g., `=?UTF-8?B?...?=`)
- Decode body content (base64, quoted-printable)
Из этой спецификации система автоматически генерирует два артефакта: непосредственно исполняемый Python-компонент (например, eml_converter.py) и набор юнит-тестов (test_eml_converter.py). Система самостоятельно прогоняет тесты и убеждается, что функция корректно обрабатывает структуру файлов, извлекает нужные заголовки и не падает при отсутствии вложений.
Главная ценность такого подхода заключается в жесткой изоляции. Так как спецификация предельно четкая и имеет строгие контракты ввода-вывода, ИИ-агенту не нужно выдумывать, что именно реализовать, или галлюцинировать дополнительный функционал. Нейросеть ограничена рамками Markdown-файла. Если спустя время разработчику понадобится добавить извлечение даты получения письма, он просто допишет одну строку в раздел «Output Structure» в .cs.md файле. После команды сборки CodeSpeak обновит исключительно eml_converter.py и его тесты, совершенно не затрагивая остальную кодовую базу проекта.
Понимая, что переписать существующие энтерпрайз-проекты с нуля практически невозможно, создатели CodeSpeak предусмотрели возможность частичной интеграции. В так называемом смешанном режиме (Mixed Mode) разработчик может инициализировать CodeSpeak внутри старого репозитория и строго ограничить список файлов, с которыми системе разрешено взаимодействовать. Это позволяет внедрять новые функции через текстовые спецификации, не подвергая риску устоявшуюся архитектуру.
Для работы с уже написанным кодом реализован механизм автоматического реверс-инжиниринга и передачи управления (команда takeover). Инженеру достаточно указать утилите конкретный исходный файл: система проанализирует алгоритмы и извлечет их бизнес-логику, сгенерировав для нее новый текстовый Markdown-файл со спецификацией. В официальном блоге проекта приводится показательный пример с конвертером форматов из библиотеки Microsoft MarkItDown, где CodeSpeak успешно превратил сотни строк Python-кода в лаконичное текстовое описание правил парсинга.
Как только существующий код переведен под контроль платформы, править оригинальные исходники вручную больше не нужно. Если в дальнейшем потребуется, например, добавить обработку нового поля в почтовом сообщении, разработчик просто вписывает одно дополнительное требование в Markdown-спецификацию. Опираясь на это обновление, CodeSpeak самостоятельно перепишет исходный код конвертера, создаст нужные вспомогательные методы и расширит тестовую базу для проверки новых требований.
Архитектура CodeSpeak решает одну из главных проблем современных ИИ-помощников вроде Cursor или GitHub Copilot. При использовании агентов инженер формулирует свои намерения в интерфейсе чата. Агент выдает готовый код, который затем отправляется в репозиторий проекта. При этом сам диалог, содержащий истинный смысл и бизнес-логику решения, теряется навсегда.
Бреслав отмечает, что при таком подходе коллеги разработчика видят только результат работы машины, а не изначальное намерение. Код становится языком общения между инженерами, хотя изначально он генерировался машиной для машины. В долгосрочной перспективе это приводит к усложнению код-ревью и потере контроля над архитектурой, так как тестировать и проверять огромные массивы сгенерированного кода без понимания изначальной логики практически невозможно.
Платформа CodeSpeak меняет этот парадокс, фиксируя диалог с ИИ в виде статических файлов спецификаций. Спецификация становится главным артефактом, подлежащим контролю версий и код-ревью. Команда обсуждает и утверждает смысловую часть алгоритма, оставляя валидацию синтаксиса на откуп автоматизированным тестам.
Подход с использованием формальных спецификаций решает проблему масштабирования и поддержки больших кодовых баз, однако ручное создание таких документов, вероятно, окажется лишь промежуточным этапом в эволюции разработки. Логика развития инструментов на базе больших языковых моделей указывает на то, что в обозримом будущем инженеры перестанут писать даже сами спецификации.
Вместо структурированных файлов разработчик будет формулировать бизнес-требования на свободном естественном языке — в виде высокоуровневых продуктовых пожеланий или пользовательских историй. ИИ-агенты возьмут на себя роль системных аналитиков: они будут переводить неструктурированный текст от человека в строгие формальные спецификации. Этот процесс станет логичным развитием механизма реверс-инжиниринга, который уже сейчас используется в CodeSpeak для генерации контрактов из старого кода. Сформировав спецификацию, машина самостоятельно сгенерирует по ней исполняемый код и тесты.
В такой парадигме роль программиста кардинально меняется. Навык написания формальных контрактов с нуля будет требоваться крайне редко, уступая место навыку аналитического чтения. Главной задачей разработчика станет умение читать спецификации, понимать заложенную в них архитектуру и верифицировать логику. Человеку предстоит выступать в роли валидатора, который проверяет, правильно ли ИИ-агент интерпретировал изначальную бизнес-идею, прежде чем эта спецификация превратится в работающий продукт. Фокус профессии окончательно сместится от создания строк кода или текста к экспертной оценке и управлению смыслом.
Развитие ИИ-агентов породило в индустрии феномен, который западные разработчики в шутку окрестили vibe-coding — подходом, при котором человек просто описывает желаемый результат текстом, а нейросеть выдает готовое приложение. На фоне резкого скачка возможностей моделей многие компании начали замораживать наем младших разработчиков, ошибочно полагая, что алгоритмы способны полностью заменить начинающих специалистов.
В большом интервью, видео которого представлено ниже, Андрей Бреслав прямо называет массовый отказ от найма джуниоров глупой и временной ошибкой рынка. По его словам, управленцы сейчас ослеплены хайпом вокруг ИИ-инструментов, но эта эйфория неизбежно пройдет, когда индустрия столкнется с необходимостью поддерживать сгенерированные проекты на длинной дистанции. Рано или поздно бизнес осознает, что для развития технологий в индустрию должен постоянно поступать приток новых людей.
Главная проблема бездумного делегирования заключается в потере контроля. Бреслав подчеркивает, что если всю архитектурную работу начнут выполнять исключительно модели, а люди перестанут понимать, как именно работает код, это приведет к потере субъектности инженера. Задача человека — управлять так называемой «сущностной сложностью» (essential complexity), точно формулировать намерения и принимать технические решения. Машина выступает лишь исполнителем, и для корректной постановки задач ей по-прежнему требуется полноценный инженерный склад ума.
Начинающим разработчикам создатель Kotlin советует не поддаваться панике, а извлекать из ситуации выгоду. С одной стороны, необходимо в совершенстве освоить новые ИИ-инструменты, чтобы многократно повысить свою продуктивность. С другой — использовать освободившееся время для максимально глубокого погружения в фундаментальные, хардкорные основы программирования. Умение разобраться в том, как всё устроено «под капотом», вскоре станет редкой и крайне востребованной экспертизой на рынке, переполненном операторами нейросетей.
На данный момент CodeSpeak имеет статус альфа-версии и требует от пользователей готовности к техническим шероховатостям. Команда проекта фокусируется на улучшении механизмов синхронизации: система должна гарантировать, что при удалении кода его всегда можно в точности восстановить из спецификации, а любые изменения текста транслируются в адекватные изменения архитектуры. Несмотря на раннюю стадию, инструмент уже обозначает новый вектор развития индустрии, где главной компетенцией инженера становится умение структурировать сложность и управлять намерениями, а не владение синтаксисом конкретных языков программирования.
CodeSpeak: Software Engineering with AI — CodeSpeak
Андрей Бреслав — российский программист, один из создателей языка программирования Kotlin (руководитель группы разработчиков в компании JetBrains), сооснователь сервиса подбора психологов Alter.ru, основатель CodeSpeak.
Проект Malus запустил автоматизированный сервис, использующий две изолированные группы нейросетей для переписывания библиотек с открытым исходным кодом. Технология позволяет легально удалять оригинальные лицензии и делать программное обеспечение проприетарным, решая проблему юридических рисков корпоративного сектора, которая оценивается в миллионы долларов ежегодно.
«Чистая комната» как услуга.
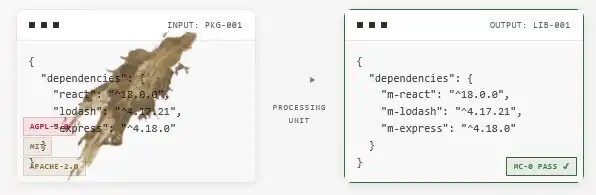
Наконец-то свобода от лицензионных обязательств открытого кода. Авторы: Mike Nolan Источник: MalusCorp
Наши проприетарные ИИ-роботы самостоятельно воссоздают любой проект с открытым кодом с нуля. Результат? Юридически независимый код с удобной для корпораций лицензией. Никакого указания авторства. Никакого копилефта. Никаких проблем. Авторы: Mike Nolan Источник: MalusCorp
Сервис Malus предлагает бизнесу механизм полного избавления от условий строгих лицензий вроде AGPL, GPL или правил обязательной атрибуции Apache. Клиент загружает файл-манифест с зависимостями своего проекта и получает функциональные аналоги нужных пакетов. Итоговый продукт юридически очищен от прав оригинальных создателей и передается заказчику под новой проприетарной лицензией MalusCorp-0, которая не требует указания авторства и позволяет корпорациям распоряжаться алгоритмами по своему усмотрению.
В основе системы лежит автоматизированный процесс так называемой «чистой комнаты». Первая группа ИИ-агентов изолированно анализирует исключительно публичную документацию, спецификации и интерфейсы оригинального программного обеспечения. Вторая группа, физически отгороженная от первой и не имеющая доступа к исходным текстам, пишет код с нуля на базе составленного технического задания. Это исключает прямое копирование и переводит процесс из разряда плагиата в категорию независимого воссоздания.
Стоимость услуги рассчитывается динамически по тарифу один цент за каждый килобайт распакованного исходного пакета. По расчетам системы, очистка популярной библиотеки маршрутизации express обойдется в 73 цента, в то время как крупный пакет lodash будет стоить чуть менее 14 долларов.
Идея проекта не является юридической новацией. Она базируется на американском судебном прецеденте Baker v. Selden 1879 года, который жестко разделил концепцию и форму ее выражения. Закон об авторском праве защищает конкретный текст программы, но не саму идею или заложенную в нее функцию. Тот, кто сможет реализовать аналогичный механизм с нуля, не заглядывая в чужие исходники, становится полноправным владельцем нового продукта.
В 1984 году компания Phoenix Technologies использовала этот принцип для легального клонирования базовой системы ввода-вывода от IBM. Один инженер месяцами изучал документацию и писал спецификацию, а другой, никогда не видевший оригинального кода, создавал совместимый аналог. Этот проект занял несколько месяцев ручного труда, но позволил сторонним производителям материнских плат легально запускать любые операционные системы без отчислений оригинальному разработчику.
Процесс «чистой комнаты» всегда был невероятно дорогим занятием, требующим штата юристов и жесткой дисциплины. Новация платформы Malus заключается в делегировании этой сложной юридической процедуры нейросетям. Первая группа алгоритмов выступает в роли первого инженера, изолированно читая документацию, а вторая берет на себя роль исполнителя, моментально генерируя «чистый» код. По заявлению создателей платформы, известная микробиблиотека left-pad воссоздается системой за десять секунд, а первая в истории видеоигра Spacewar — всего за пять.
Юридическая база столетней давности в сочетании с машинным обучением превращает авторское право из непреодолимой защиты сообщества разработчиков открытого кода в формальность, которую легко автоматизировать.
В программном манифесте, опубликованном 1 марта 2026 года, генеральный директор Malus Майк Нолан формулирует главную проблему корпоративного сектора: мировая цифровая инфраструктура держится на энтузиазме волонтеров. Бизнес получает программное обеспечение бесплатно, но расплачивается за это отсутствием гарантий, технической поддержки и контроля над цепочками поставок.
Проблема имеет конкретное финансовое выражение. По оценке создателей сервиса, среднестатистическая корпорация со штатом более пятисот инженеров ежегодно тратит около четырех миллионов долларов на управление рисками открытого кода. Эти средства уходят на инструменты анализа уязвимостей, работу юристов и содержание специальных отделов по надзору за соблюдением лицензий.
Зависимость от чужих библиотек регулярно приводит к масштабным кризисам. В декабре 2021 года критическая уязвимость Log4Shell в утилите ведения логов заставила инженеров по всему миру экстренно закрывать бреши на серверах, пока неоплачиваемые авторы оригинального кода получали тысячи гневных писем от корпораций.
Возникают и ситуации намеренного саботажа: в январе 2022 года создатель популярных пакетов colors.js и faker.js внедрил бесконечные циклы в свой код в знак протеста против его использования крупным бизнесом без финансовой отдачи. В марте того же года разработчик утилиты node-ipc добавил функционал удаления файлов на компьютерах пользователей по геополитическим мотивам.
В такой парадигме использование открытого исходного кода становится для корпораций непредсказуемой структурной уязвимостью. Платформа Malus предлагает решить эту проблему радикально: разорвать социальный контракт с разработчиками и заменить их полностью подконтрольным машинным кодом.
Несмотря на наличие работающей системы оплаты и реальную возможность загрузить файл конфигурации для обработки, проект Malus является масштабной сатирой, приуроченной к выступлению Майка Нолана на европейской конференции разработчиков FOSDEM в 2026 году. За фасадом стартапа, публикующего вымышленные отзывы корпоративных менеджеров о том, что чувство вины не отображается в квартальных отчетах, скрывается жесткая критика современной технологической индустрии.
Именно здесь ирония проекта достигает своего пика и становится пугающе точной. Вместо того чтобы выстроить систему справедливой компенсации для уставших программистов-энтузиастов, на которых держится вся мировая архитектура, гиганты индустрии предпочитают искать юридические лазейки. Платформа едко высмеивает эту корпоративную логику: компаниям проще нанять ИИ-агентов, которые за доли секунды сотрут лицензию и уничтожат любые следы авторства, чем поддержать создателя оригинальной идеи.
Реакция профильных сообществ показала, что граница между шуткой и реальностью окончательно стерта. В ходе обсуждений на площадке Hacker News многие инженеры восприняли платформу как настоящую коммерческую угрозу. Специалисты отметили, что описанный юридический механизм технически реализуем уже сегодня, а автоматизированное правоприменение радикально меняет правила игры. Как только стоимость обхода лицензии становится ниже стоимости судебного разбирательства, система защиты авторских прав начинает давать сбой.
Проект Malus подсветил фундаментальный парадокс современного рынка технологий. Искусственный интеллект, обученный на массивах бесплатного программного обеспечения, теперь используется для того, чтобы лишить создателей этого самого обеспечения последних юридических рычагов влияния.
Открытым остается лишь вопрос о том, как скоро подобная едкая антиутопия окончательно станет реальностью: потребуется ли индустрии отдельный судебный прецедент для оценки машинной «чистой комнаты», или автоматическая очистка кода и обход лицензий незаметно превратятся в стандартный бизнес-процесс для транснациональных корпораций.
Группа исследователей впервые смоделировала полный жизненный цикл живой бактериальной клетки с наномасштабным разрешением, отследив поведение каждого гена, белка и химической реакции от репликации ДНК до клеточного деления. Результаты исследования, опубликованные в журнале Cell, открывают возможность заменить сотни реальных лабораторных экспериментов одной комплексной 4D-симуляцией.
Смоделированная клетка на ранних стадиях деления

Смоделированная клетка на ранних стадиях деления. В левой половине показана цитоплазма, механизмы деградации мРНК и переносчики сахара. В правой половине добавлены мембрана и рибосомы. Авторы: Zane Thornburg. Источник: Cell.
На иллюстрации представлена трехмерная компьютерная модель бактериальной клетки в разрезе. Клетка имеет вытянутую форму, готовясь к делению. Левая часть демонстрирует плотное скопление синих кубических структур (цитоплазма) с вкраплениями розовых и коричневых элементов у внешней границы. Правая часть показывает полупрозрачную зеленую оболочку (мембрану), под которой скрывается густая сеть красных нитей (ДНК) с множеством мелких желтых сфер (рибосомы). Авторы: Zane Thornburg. Источник: Cell.
Ученые представили первую полномасштабную 4D-модель (три пространственных измерения плюс время) минимальной бактериальной клетки. Модель с наномасштабным разрешением учитывает пространственное положение и химические реакции каждого гена, белка и метаболита на протяжении всего клеточного цикла.
Объектом оцифровки стала синтетическая бактерия JCVI-syn3A. Этот организм обладает искусственно сокращенным геномом содержащим всего 493 гена на одной кольцевой хромосоме, минимум, необходимый для роста и поддержания жизни, что делает его идеальным кандидатом для компьютерного моделирования.
Несмотря на генетическую простоту бактерии, вычислительные затраты на симуляцию оказались колоссальными. Для обработки одного жизненного цикла, который в реальности занимает около 105 минут, потребовалось шесть дней непрерывных расчетов на суперкомпьютере Delta. Масштабный проект, потребовавший интеграции огромных массивов экспериментальных данных от протеомики до криоэлектронной томографии, разрабатывался исследователями из Университета Иллинойса, Гарварда и Института Дж. Крейга Вентера в течение нескольких лет.
Бактерия JCVI-syn3A, ставшая прототипом для цифрового двойника, не встречается в природе. Это искусственно созданный в лабораториях Института Дж. Крейга Вентера организм, генетически урезанная версия бактерии Mycoplasma mycoides. Предыдущая версия этого синтетического микроба, известная как Syn3.0, имела еще меньше генов, но из-за этого потеряла способность делиться на ровные, правильные сферы. Чтобы вернуть клетке стабильную морфологию при делении, ученым пришлось вернуть часть генетического кода.
В итоге геном версии Syn3A содержит всего 493 гена, расположенных на одной кольцевой хромосоме (для сравнения, у кишечной палочки их более четырех тысяч). Как и у других бактерий, у нее нет ядра. Каждый компонент этой системы либо является частью внешней мембраны, либо транспортируется снаружи, либо собирается прямо в цитоплазме.
Создавая 4D-анимации на основе полученной модели, исследователи столкнулись с неожиданной проблемой: внутренняя среда Syn3A оказалась настолько плотно набита молекулярными игроками, что разглядеть хоть что-то было невозможно. Чтобы визуализировать, как единственная хромосома протискивается сквозь тесную цитоплазму клетки, ученым пришлось сделать часть белков прозрачными. Именно эта невероятная пространственная теснота и делает обычные математические расчеты неточными: в живой клетке молекулам нужно буквально проталкиваться друг к другу, чтобы вступить в химическую реакцию.
Чтобы реалистично сымитировать эту тесноту, команде пришлось гибридизировать сразу несколько независимых вычислительных подходов в один программный комплекс. Метаболизм, где молекулы малы, а их концентрации высоки, описывается классическими обыкновенными дифференциальными уравнениями. Процессы транскрипции генов моделируются через химическое основное уравнение, учитывающее случайность реакций. За физическое перемещение молекул в пространстве отвечает реакционно-диффузное основное уравнение, которое разбивает объем клетки на кубическую сетку с шагом в 10 нанометров.
Самым сложным элементом стала динамика главной молекулы — хромосомы. Ее физическое поведение моделировалось методом броуновской динамики в симуляторе LAMMPS.
В процессе разработки аспирант Эндрю Мэйтин обнаружил критическое «бутылочное горлышко»: расчет репликации и движения запутанной нити ДНК замедлял всю симуляцию настолько, что время расчета жизненного цикла удваивалось и практически останавливалось.
Чтобы физика макромолекул не тормозила химию метаболизма, вычисления разделили на аппаратном уровне. Один графический процессор был выделен исключительно под тяжелую симуляцию динамики ДНК, в то время как второй GPU обрабатывал все остальные клеточные процессы, обмениваясь данными с первым каждые четыре секунды биологического времени. Суммарно на симуляцию 50 уникальных жизненных циклов ушло около 15 000 GPU-часов работы ускорителей NVIDIA A100.
Точность симуляции превзошла ожидания авторов. При многократных запусках с незначительно меняющимися стартовыми условиями виртуальная клетка удваивала свой размер и делилась в среднем за время, отличающееся от реальных 105 минут не более чем на две минуты. Время репликации самой хромосомы составило около 51 минуты.
Модель точно предсказала динамику копирования генома — соотношение между стартовыми и конечными участками репликации хромосомы совпало с реальным. В симуляции этот показатель составил 1.28, что плотно коррелирует с результатами физического секвенирования ДНК живых клеток 1.21. Это подтверждает, что виртуальная бактерия копирует свой генетический материал с той же скоростью и частотой, что и настоящая.
Однако наиболее интересными результатами стали расхождения и физические ограничения симуляции. Постдок Зейн Торнбург отметил, что заставить мембрану и растущую ДНК корректно взаимодействовать при одновременном движении было крайне тяжело. Когда клетка начинала делиться на две дочерние, физического моделирования работы белков-конденсинов и топоизомераз оказалось недостаточно, чтобы распутать две новые хромосомы. Модель не могла самостоятельно развести их по разным половинам клетки за адекватное время машинных расчетов.
Чтобы деление завершилось, ученым пришлось внедрить в код «физический костыль» — искусственную силу отталкивания величиной примерно 12 пиконьютонов, которая принудительно растаскивала дочерние хромосомы. Это наглядно демонстрирует, что наука до сих пор не до конца понимает биомеханические механизмы сегрегации хромосом у организмов, лишенных стандартных белковых систем распределения ДНК.
Кроме того, симуляция выявила легкий дефицит в производстве крупных белков. Анализ показал причину: в текущей модели каждая матричная РНК может считываться только одной рибосомой за раз. В живой природе на длинных мРНК формируются полисомы — цепочки из нескольких рибосом, одновременно синтезирующих белок. Интеграция диффузии массивных полисом в виртуальную клетку пока оказалась слишком вычислительно дорогой задачей.
Запустив модель 50 раз, биологи получили 50 совершенно разных жизненных историй. Благодаря тому, что модель учитывает пространственную диффузию, распределение макромолекул (например, рибосом или белков) по двум новым дочерним клеткам при делении оказалось абсолютно случайным, подчиняясь биномиальному распределению. Ни одна дочерняя клетка не получала идеальную половину ресурсов.
Еще более удивительным оказалось поведение генов. Поскольку запуск транскрипции зависит от того, столкнется ли РНК-полимераза с нужным участком ДНК в пространстве, процесс носит случайный, «взрывной» характер. Анализ показал, что 81 ген (из 493 существующих) вообще ни разу не был считан полимеразой на протяжении одного-трех виртуальных клеточных циклов. Иными словами, клетка может прожить всю жизнь, ни разу не обратившись к части своей ДНК. При этом виртуальный организм выживал за счет белков, унаследованных от предыдущего поколения.
Возможность наблюдать за живой системой в таком разрешении меняет подход к клеточной биологии. По словам Зан Латей-Шультен, цельноклеточная модель прогнозирует множество параметров одновременно. Исследователь может локально изменить параметры нуклеотидного метаболизма и мгновенно увидеть, как это повлияет на скорость репликации ДНК на другом конце клетки и сборку рибосом в центре цитоплазмы.
Сейчас в науке набирает популярность использование искусственного интеллекта для прогнозирования состояния клеток. ИИ способен генерировать моментальные «снимки» клеточных процессов на основе огромных массивов данных. Команда из Иллинойса предлагает фундаментально иной путь — их 4D-модель не угадывает следующее состояние, а математически рассчитывает его, опираясь на строгие законы биофизики. В перспективе это позволит превратить суперкомпьютеры в универсальные виртуальные чашки Петри, где можно тестировать генетические мутации и лекарственные препараты без проведения сотен долгих лабораторных экспериментов.
Why simulating an entire cell cycle took years, multiple GPUs and six days per run — phys, авторы: University
Team simulates a living cell that grows and divides — Chemistry — chemistry.illinois, авторы: Diana Yates; Illinois News Bureau
Team simulates a living cell that grows and divides — eurekalert
Minimal Cell Simulation Recreates Full Cell Cycle Dynamics — letsdatascience
Bringing the genetically minimal cell to life on a computer in 4D — Cell, авторы: Zane R. Thornburg, Andrew Maytin, Angad P. Mehta, Taekjip Ha, John I. Glass, Zaida Luthey-Schulten et al.
Ученные Сиднейского университета создали прототип нанофотонного процессора для искусственного интеллекта, который обрабатывает данные с помощью света вместо электрического тока. В ходе экспериментов чип успешно классифицировал десятки тысяч медицинских изображений с точностью до 99 процентов. Новая архитектура выполняет вычисления за пикосекунды (триллионные доли секунды), полностью исключая проблему тепловыделения, и демонстрирует альтернативу перегревающимся кремниевым серверам современных дата-центров.
Фотография нанофотонного процессора под микроскопом
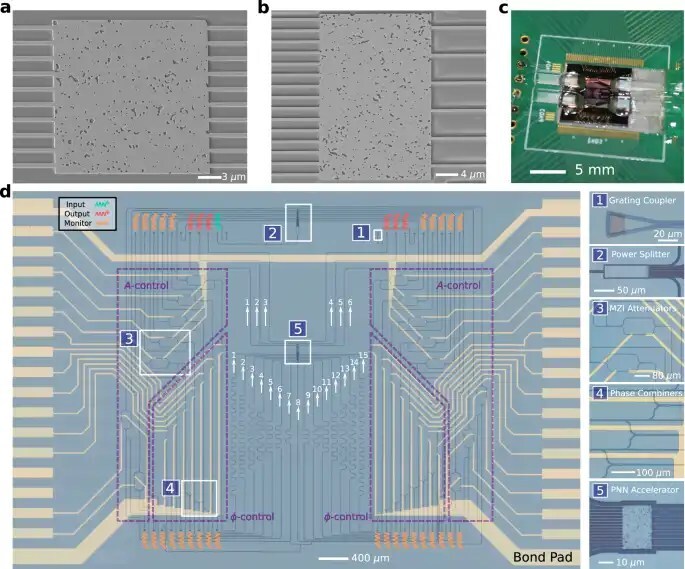
Снимки сканирующего электронного микроскопа чипов MNIST (20×20 мкм) и MedNIST (30×20 мкм), созданных на платформе кремний-на-изоляторе. Авторы: Joel Sved et al. Источник: Nature Communications.
На изображении представлены увеличенные микроскопические снимки нанофотонных ускорителей. Показаны оптические волноводы, подводящие свет к структуре с топологически оптимизированным материалом, где происходят физические вычисления. На нижних фрагментах видна интеграция чипа на печатную плату с золотыми контактами для взаимодействия с управляющей электроникой. Авторы: Joel Sved et al. Источник: Nature Communications.
Исследовательская группа по фотонике Сиднейского университета под руководством профессора Сяокэ И представила работающий прототип сверхкомпактного оптического процессора. Устройство предназначено для выполнения математических операций, лежащих в основе машинного обучения. Особенность разработки заключается в полном отказе от перемещения электронов по металлическим проводникам — процесс обработки информации базируется на управлении фотонами.
Традиционные вычислительные системы при высоких нагрузках неизбежно выделяют колоссальный объем тепла из-за электрического сопротивления. Фотонный чип решает эту проблему на фундаментальном уровне. Свет проходит через наноструктуры без сопротивления, что делает генерацию тепла практически нулевой. Скорость выполнения одной операции при этом сокращается до пикосекундного диапазона — триллионных долей секунды. Это время, за которое свет физически успевает преодолеть структуру чипа.
Разработка была протестирована на базах данных MNIST (рукописные цифры) и MedNIST (более 10 000 биомедицинских изображений, включая МРТ грудной клетки и брюшной полости). В симуляциях система показала точность до 99 процентов. В реальных аппаратных экспериментах чип продемонстрировал точность классификации в 89 процентов для базы MNIST и 90 процентов для MedNIST, уверенно распознавая визуальные паттерны заболеваний на медицинских снимках.
Индустрия искусственного интеллекта стремительно упирается в «энергетическую стену». Вычислительные центры требуют мегаватты электричества и миллионы литров воды для охлаждения серверов. Фотонные нейронные сети рассматриваются как логичный выход из кризиса, однако до сих пор их слабым местом оставались габариты. Создать оптический элемент сложнее, чем вытравить миллиард кремниевых транзисторов на одном квадратном миллиметре.
Австралийские исследователи обошли это ограничение с помощью метода обратного проектирования, основанного на 3D-моделировании электромагнитных полей. Вместо того чтобы строить нейросеть из классических оптических компонентов вроде интерферометра Маха-Цендера, инженеры позволили алгоритму самостоятельно рассчитать оптимальную форму материала.
Получившийся чип представляет собой сложную, визуально хаотичную наноструктуру из кремния и диоксида кремния. Внутри этой структуры световые волны (на длине волны 1550 нанометров) многократно рассеиваются и интерферируют. Проходя через материал, свет физически выполняет операцию умножения матриц. Размеры рабочей зоны составляют всего 20×20 микрометров для задачи распознавания цифр и 30×20 микрометров для медицинских изображений. По оценке создателей, такая архитектура обеспечивает феноменальную вычислительную плотность — около 400 миллионов обучаемых параметров на один квадратный миллиметр.
Успех австралийской команды опирается на десятилетие предшествующих исследований в области физики оптических вычислений. Долгое время главным камнем преткновения для фотоники оставались нелинейные операции — функции активации, которые позволяют нейросети решать нешаблонные задачи и выявлять сложные закономерности. Фотоны практически не взаимодействуют друг с другом, из-за чего создание оптической нелинейности требовало огромных затрат энергии. В ранних системах оптические данные приходилось конвертировать обратно в электрические сигналы, отправлять на цифровой процессор для применения нелинейной функции, а затем снова переводить в свет.
Решение этой проблемы ранее предложила группа ученых из Массачусетского технологического института под руководством Дирка Энглунда и Саумила Бандиопадхьяя. В их архитектуре, описанной в журнале Nature Photonics, были применены нелинейные оптические функциональные блоки. Эти элементы отводят минимальную часть света на фотодиоды для преобразования в слабый ток, управляя нелинейностью без внешних усилителей.
В результате чип MIT смог выполнить весь цикл вычислений глубокой нейросети — как линейные, так и нелинейные операции — исключительно в оптическом домене менее чем за половину наносекунды с точностью выше 92 процентов. Исследователи доказали, что оптические процессоры могут обучаться в режиме реального времени, потребляя лишь малую долю энергии по сравнению с кремниевыми аналогами.
Пока академические группы бьются над повышением точности и миниатюризацией вычислительных ядер, технологические компании уже адаптируют фотонику для нужд гиперскейлеров. Основное узкое место современных ИИ-кластеров — не только скорость самих вычислений, но и скорость передачи данных между видеокартами (GPU).
Компания Lightmatter выводит на рынок технологию 3D Co-Packaged Optics. Их решения, такие как фотонный суперчип Passage M1000, объединяют электронные интегральные схемы с фотонными напрямую в едином компактном модуле. Это снимает классические ограничения пропускной способности медных соединений, возникающие из-за физической нехватки места для контактов по периметру печатных плат. Что критически важно для обучения гигантских языковых моделей.
Фотонные модули Lightmatter способны передавать до 448 гигабит данных в секунду по одному оптическому каналу. Для достижения таких сверхскоростей применяется технология PAM4 — особый формат многоуровневой амплитудной модуляции, который позволяет «упаковывать» в каждый сигнал в два раза больше информации по сравнению с традиционными методами кодирования. Кроме того, архитектура системы позволяет производить горячую замену оптоволокна прямо в серверных стойках дата-центров.
Команда Сиднейского университета уже подала патентную заявку на свою технологию нанофотонных чипов и работает над ее масштабированием. Следующим шагом станет объединение множества подобных блоков в крупные оптические сети для обработки фрагментированных данных по принципу сверточных нейросетей. Архитектура разрабатывается с расчетом на стандартные производственные процессы CMOS-фабрик. Переход индустрии на оптику — процесс не быстрый, однако успешная интеграция света на микроуровне доказывает, что у кремниевой монополии появился фундаментально обоснованный конкурент.
Чтобы понять фундаментальную разницу между классическим и оптическим процессором, достаточно спуститься на уровень элементарных частиц. В основе работы любого современного графического ускорителя лежит направленное движение электронов. Электрон — частица с ненулевой массой покоя и отрицательным электрическим зарядом. Когда миллиарды этих частиц под действием напряжения продираются сквозь кристаллическую решетку полупроводника, они неизбежно сталкиваются с ее атомами.
В физике твердого тела этот процесс называется рассеянием, а на практике он работает как микроскопическое трение. Электроны отдают часть своей кинетической энергии решетке, заставляя атомы вибрировать сильнее. На макроуровне эта вибрация превращается в стремительный нагрев. Именно из-за этого фундаментального физического ограничения современные серверные стойки с видеокартами требуют гигантских радиаторов, мощных вентиляторов и тысяч литров воды для охлаждения.
Фотонная архитектура меняет сами правила игры, отказываясь от заряженных электронов в пользу фотонов. У фотона нет ни электрического заряда, ни массы покоя. Когда инфракрасный луч лазера попадает в наноразмерный кремниевый волновод оптического чипа, он движется по нему, не испытывая классического электрического сопротивления.
Фотоны не взаимодействуют друг с другом так, как это делают заряженные частицы, и не «трутся» об атомы направляющей среды (для длины волны 1550 нанометров кремний абсолютно прозрачен). Они проходят сквозь сложную топологию чипа без передачи паразитной энергии материалу. В результате математические операции — интерференция и рассеяние света, заменяющие умножение матриц — происходят не только с максимально возможной физической скоростью, но и без генерации тепла. Фотонному процессору не нужны системы охлаждения просто потому, что в нем нет трения.
На первый взгляд использование кремния для создания оптического процессора кажется абсурдом. В нашем привычном понимании кремний — это основа классической микроэлектроники, серый кристалл с металлическим блеском, сквозь который невозможно ничего разглядеть. Как материал, абсолютно непрозрачный для человеческого глаза, может стать микроскопической магистралью для лазерных лучей?
Разгадка кроется в длине волны. То, что является непреодолимой стеной для видимого спектра, для инфракрасного излучения оказывается открытой дверью. На длине волны 1550 нанометров (именно она используется в разработке Сиднейского университета и является стандартом для оптоволоконной связи) чистейший кристаллический кремний становится прозрачным, словно высококачественное оконное стекло.
Однако просто пропустить свет сквозь материал недостаточно — физикам нужно заставить луч поворачивать, делиться и интерферировать на площадке размером тоньше человеческого волоса. Для этого инженеры используют технологическую платформу «кремний-на-изоляторе». Тончайший слой кремния укладывается на подложку из диоксида кремния, после чего в верхнем слое вытравливаются микроскопические дорожки — оптические волноводы.
Здесь начинает работать фундаментальный закон оптики — полное внутреннее отражение. Кремний имеет очень высокий показатель преломления по сравнению с окружающим его диоксидом. Когда инфракрасный лазер попадает в такой кремниевый канал, резкий контраст оптических плотностей материалов превращает границы волновода в идеальное зеркало. Свет оказывается запертым внутри: он отскакивает от стенок кремниевой «проволоки» и мчится по извилистому наноразмерному лабиринту чипа, не рассеиваясь наружу. Именно этот физический трюк позволяет ученым использовать традиционное оборудование заводов по производству электроники для создания сложнейших световых процессоров.
Глядя на микроскопический снимок нового нанофотонного процессора, можно заметить, что его рабочая зона совершенно не похожа на строгую прямоугольную геометрию классических электронных микросхем. Она выглядит хаотичной, текучей, почти органической. Подобный подход к управлению светом за счет сложнейшей физической формы ученые давно подсмотрели у самой природы. Самый яркий пример такой оптической инженерии — крылья тропических бабочек рода морфо.
Знаменитый пронзительно-синий цвет их крыльев возникает не благодаря биологическим пигментам или химическим красителям. Если измельчить чешуйку такого крыла в пыль, сияющий оттенок исчезнет, оставив лишь невзрачную серую массу. Секрет кроется в явлении структурной окраски. На поверхности крыла расположены миллионы микроскопических элементов со сложной, напоминающей ветвящиеся деревья, наноструктурой. Когда свет попадает на этот рельеф, он многократно преломляется и интерферирует. Физическая архитектура чешуйки выверена эволюцией так, что световые волны синего спектра накладываются и усиливают друг друга, в то время как волны других цветов взаимно гасятся.
Создавая свой ИИ-чип методом топологической оптимизации, австралийские инженеры применили ровно тот же фундаментальный принцип. Алгоритм буквально «вылепил» из кремния сложнейший нанорельеф, который работает как идеальный оптический лабиринт. Точно так же, как крыло бабочки манипулирует светом для создания безупречного синего цвета, кремниевая структура процессора заставляет инфракрасные лазерные волны интерферировать и рассеиваться по строго заданным математическим векторам. В обоих случаях сложнейший результат — будь то потрясающий визуальный эффект или нейросетевая классификация медицинского снимка — достигается исключительно за счет виртуозной геометрии наноструктур: хитина у бабочки и кремния в процессоре.
Inverse-designed nanophotonic neural network accelerators for ultra-compact optical computing — Nature Communications, авторы: Joel Sved, Shijie Song, Liwei Li, George Li, Debin Meng, Xiaoke Yi
Sydney researchers build ultra-compact AI chip operating at speed of light — EurekAlert!
Sydney researchers build ultra-compact AI chip operating at speed of light — EX2 for Defence Innovators, авторы: Gregor Ferguson
Lightmatter® — The photonic (super)computer company. — Lightmatter
Photonic processor could enable ultrafast AI computations with extreme energy efficiency — MIT News, авторы: Adam Zewe
Исследователи совершили прорыв в нейробиологии, успешно реконструировав динамичное видео исключительно по активности клеток зрительной коры мыши. Пока животные смотрели черно-белые ролики со спортивной гимнастикой и рестлингом, алгоритм считывал вспышки кальция в восьми тысячах нейронов и покадрово восстанавливал увиденное. Технология достигла беспрецедентной точности: на итоговых кадрах можно различить силуэты людей и контуры предметов. Это приближает науку к пониманию того, как именно мозг искажает физическую реальность.
Реконструкция видео из активности зрительной коры мыши

Слева направо: оригинальные кадры и то, как их «увидел» алгоритм, считав активность нейронов мыши. Авторы: Joel Bauer, Troy W Margrie, Claudia Clopath. Источник: eLife / The Guardian.
На изображении представлены раскадровки: в верхнем ряду показаны оригинальные черно-белые кадры из видеороликов, а в нижнем — размытые, но узнаваемые силуэты, восстановленные искусственным интеллектом исключительно на основе активности нейронов зрительной коры мыши. Авторы: Joel Bauer, Troy W Margrie, Claudia Clopath. Источник: eLife / The Guardian.
Команда нейробиологов под руководством Джоэла Бауэра из Центра Сейнсбери Уэлком при Университетском колледже Лондона (UCL) опубликовала результаты уникального эксперимента. Ученые смогли восстановить десятисекундные видеоролики с частотой 30 кадров в секунду, используя исключительно записи активности клеток зрительной коры живых мышей. Результаты исследования были представлены 10 марта 2026 года в научном журнале eLife.
В ходе эксперимента грызунам показывали черно-белые клипы, на которых люди занимались различными видами спорта, включая спортивную гимнастику, верховую езду и рестлинг. В это время исследователи фиксировали активность мозга животных с помощью двухфотонной кальциевой микроскопии. Этот метод позволяет визуализировать локальные всплески кальция в тканях, точно определяя, какие именно клетки мозга возбуждаются в конкретную долю секунды. Для каждой из десяти мышей, участвовавших в проекте, ученые собрали данные примерно от восьми тысяч отдельных нейронов.
Для расшифровки полученного массива данных применялась динамическая модель нейронного кодирования, изначально созданная для научного соревнования Sensorium 2023. Алгоритм анализировал не только оптические стимулы, но и физиологические параметры мыши, поскольку зрительная кора грызунов сильно реагирует на сторонние факторы. Сопоставив нейронные реакции с видеорядом, система достигла пиксельной корреляции между оригиналом и реконструкцией на уровне 0.57. Это более чем в два раза превышает результаты предыдущих попыток чтения статических изображений из мозга мышей.
В последние годы новости о чтении мыслей появляются регулярно, однако большинство громких прорывов связано с функциональной магнитно-резонансной томографией (фМРТ) человека. Проблема фМРТ заключается в ее низком пространственном и временном разрешении. Томограф фиксирует приток крови к обширным зонам мозга с задержкой в несколько секунд. Чтобы получить из этого красивую картинку, исследователи обычно используют генеративные нейросети вроде Stable Diffusion, которые дорисовывают детали на основе семантического смысла. Иными словами, если мозг человека реагирует на концепцию красной машины, ИИ просто рисует красивую красную машину из своей базы данных, а не то конкретное изображение, которое видят глаза.
Эксперимент британской команды радикально отличается от этого подхода. Ученые не использовали готовые генеративные сети для дорисовки смысла. Они опирались на сырые данные, считывая импульсы отдельных нейронов с частотой восемь герц на площади мозга размером 630 на 630 микрометров. Они напрямую заглянули в операционную систему зрения млекопитающего, а не пытались угадать ассоциации.
При этом ИИ-модели пришлось учитывать крайне специфическую физиологию грызунов. Активность нейронов в первичной зрительной коре мыши сильно зависит от уровня ее возбуждения и физической активности. То, как мышь воспринимает картинку, меняется в зависимости от того, бежит она по беговой дорожке или стоит на месте, а также от диаметра ее зрачка. Алгоритму пришлось интегрировать эти поведенческие переменные в свои вычисления, чтобы отделить чистый визуальный сигнал от моторного шума.
Механика того, как алгоритм достает картинку из мозга, напоминает обратную инженерию восприятия. Ученые не обучали нейросеть напрямую переводить кальциевые вспышки в пиксели. Вместо этого они взяли модель, которая хорошо предсказывает, как поведут себя нейроны при просмотре определенного видео. Затем исследователи подали на вход модели пустой серый экран и заставили ИИ предсказать реакцию нейронов на эту пустоту.
Естественно, предсказанная реакция на серый экран не совпала с реальной записью мозга мыши, смотревшей рестлинг. Тогда алгоритм начал покадрово изменять пиксели серого экрана с помощью метода градиентного спуска. Пиксели корректировались тысячу раз до тех пор, пока виртуальный отклик модели полностью не совпал с физиологической записью из мозга грызуна. Как только математическая ошибка между симуляцией и реальностью свелась к минимуму, на экране из серого шума проступили узнаваемые контуры людей и движущихся объектов.
Чтобы добиться максимальной чистоты изображения, авторы применили метод ансамблирования. Однократный прогон модели давал картинку, переполненную высокочастотным пространственным и временным шумом. Ученые обучили семь независимых версий алгоритма на разных наборах данных, заставили каждую реконструировать видео, а затем усреднили их результаты. Это позволило повысить качество итогового ролика почти на треть.
Исследователи также выяснили, насколько критично количество записываемых клеток. В ходе компьютерной симуляции они попробовали искусственно отключать часть нейронов. Оказалось, что удаление половины из восьми тысяч клеток снижает качество видео лишь на десять процентов. Однако потеря трех четвертей массива обрушивает точность уже на четверть. Это дает ценный ориентир для будущих нейробиологических экспериментов: для стабильного чтения зрительных образов достаточно плотности порядка десяти-двадцати тысяч нейронов на квадратный миллиметр коры.
Хотя восстановленные ролики выглядят зернистыми, они полностью соответствуют физиологическим ограничениям самих животных. Зрение мыши примерно в шесть раз хуже человеческого, поэтому алгоритм физически не мог бы восстановить сверхчеткие детали, которых мозг грызуна просто не регистрирует. Тесты с синтетическим визуальным шумом показали, что модель перестает корректно собирать картинку на высоких пространственных частотах, выходящих за рамки мышиной остроты зрения.
Джоэл Бауэр подчеркивает, что мозг не хранит идеальную попиксельную копию мира. Зрительный тракт искажает и трансформирует картинку, усиливая одни признаки и подавляя другие. Эти отклонения от реальности — не баг, а эволюционная фича, отражающая то, как разум адаптирует сенсорную информацию под задачи выживания.
Успех на животных неизбежно вызывает вопросы о применении технологии к людям. Бауэр смотрит на такую перспективу с осторожностью, отмечая, что если технология сможет реконструировать не только то, что человек видит глазами, но и то, что он воображает, возникнет колоссальная угроза приватности.
Тем не менее для фундаментальной биологии открываются невероятные перспективы. Если система может считывать внутренние образы напрямую из нейронов, в будущем ученые смогут выяснить, что именно видят животные во сне, поддаются ли они человеческим оптическим иллюзиям и какие визуальные искажения они испытывают под воздействием психоделиков. Как отметил Бауэр, эта технология может привести человечество к очень глубокой форме эмпатии по отношению к другим видам, наконец позволив нам научно ответить на классический философский вопрос: каково это — воспринимать мир мозгом другого существа.
В ближайших планах команды — расширение поля зрения при реконструкции. Текущие алгоритмы работают с данными, собранными только с одного участка зрительной коры, что дает эффект узкого замочного окна. В будущем ученые намерены объединить сигналы от обоих глаз животного, чтобы создать панорамную картину его зрительного опыта. Главный же открытый вопрос заключается в том, удастся ли с помощью этого метода отследить, как меняется репрезентация одних и тех же объектов в мозгу по мере того, как животное обучается или переносит фокус своего внимания.
Movie reconstruction from mouse visual cortex activity — eLife, авторы: Joel Bauer, Troy W Margrie, Claudia Clopath
Movie reconstruction from mouse visual cortex activity (Reviewed Preprint) — eLife, авторы: Joel Bauer, Troy W Margrie, Claudia Clopath
Movies reconstructed from mouse brain activity — EurekAlert!, авторы: University College London
Компания OpenAI выпустила обновление для ChatGPT, добавив возможность взаимодействия с динамическими визуализациями для изучения математики и естественных наук. Новая функция стала прямым развитием ранее запущенного «режима обучения», который перевел языковую модель с простой генерации ответов на формат пошагового диалога в стиле Сократа.
Динамическая визуализация закона идеального газа в интерфейсе ChatGPT
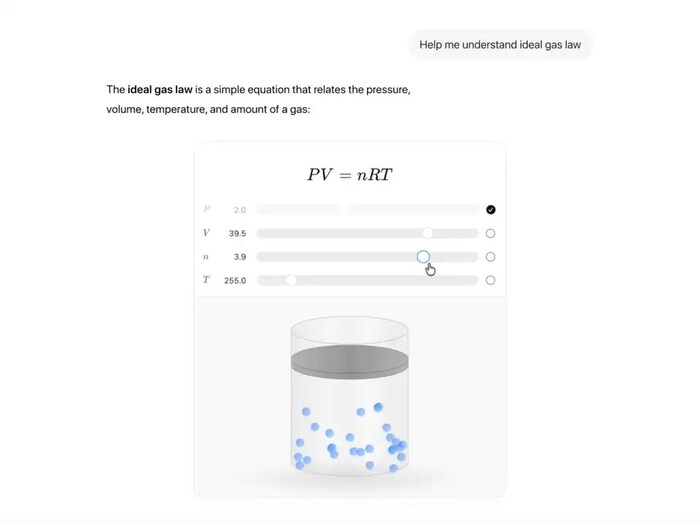
Пример визуализации физических законов. Источник: Forbes.
На изображении показан интерфейс ChatGPT, где текстовое объяснение закона идеального газа (PV=nRT) сопровождается интерактивной моделью. Пользователь может менять параметры с помощью ползунков, наблюдая, как изменяются графики давления и объема в реальном времени. Источник: Forbes.
OpenAI расширила возможности ChatGPT, представив динамические визуализации для для более чем 70 базовых дисциплин STEM (наука, технологии, инженерия, математика). Теперь при изучении таких тем, как закон идеального газа, оптических линзах или теореме Пифагора пользователи могут взаимодействовать с формулами напрямую. Интерфейс позволяет менять переменные, двигать ползунки и в реальном времени наблюдать за изменениями графиков.
Параллельно компания представила профессиональный продукт Prism, ориентированный на научных сотрудников.Инструмент Prism объединяет модель GPT-5.2 и редактор для написания документов на LaTeX. Окно чата встроено в интерфейс редактора: ИИ помогает исследователям форматировать текст, управлять списком литературы и переводить фотографии формул с маркерных досок в рабочий код.
По данным компании, аудитория этих решений уже сформирована. Еженедельно около 140 миллионов человек обращаются к чат-боту за помощью в точных науках. В профессиональном сегменте статистика также масштабна: порядка 1,3 миллиона ученых по всему миру генерируют более 8 миллионов профильных запросов каждую неделю. Глава подразделения OpenAI по науке Кевин Вейл прямо заявляет, что текущий год станет для внедрения алгоритмов в науку таким же переломным, каким 2025 год оказался для сферы программирования.
Внедрение динамических объектов стало продолжением «режима обучения». Он был разработан совместно с учеными и экспертами по педагогике, чтобы решить проблему бездумного копирования готовых ответов. Сейчас его эффективность изучается в партнерстве со Стэнфордским университетом (проект SCALE).
Механика режима строится на системных инструкциях, которые меняют алгоритм ответов ChatGPT. Вместо выдачи прямого решения задачи модель переходит к методу диалога Сократа. Система задает наводящие вопросы, предлагая пользователю самому прийти к выводу. Чтобы снизить когнитивную нагрузку, ИИ структурирует информацию и выдает ее небольшими порциями. При этом модель опирается на историю диалога и подстраивает сложность под текущий уровень навыков конкретного пользователя. В процессе беседы бот периодически предлагает небольшие тесты и открытые вопросы для закрепления материала.
По словам старшего директора программ по ИИ в Common Sense Media Робби Торни, такой подход побуждает учащихся мыслить критически. Пользователи подтверждают эффективность метода: студентка Мэгги Ванг в отзыве для OpenAI сравнила этот режим с «репетитором, который не устает от вопросов», отметив, что она смогла освоить сложную тему только благодаря многочасовому пошаговому разбору. Режим обучения можно включать и выключать специальной кнопкой в интерфейсе чата.
Если запуск базового «режима обучения» изменил логику текстового взаимодействия, то мартовское обновление 2026 года добавило в платформу визуальные инструменты. Еще при анонсе Study Mode разработчики заявляли о планах внедрить визуализации для сложных концепций.
Ранее большинство больших языковых моделей генерировали исключительно текстовые ответы. Интерактивные модули для STEM функционально сближают ChatGPT с профильными инструментами вроде графических калькуляторов Desmos или PacificTech. Вице-президент OpenAI по образованию Лия Белски отмечает, что цель разработки — наглядно продемонстрировать, как работают научные концепции. В точных науках понимание формируется через эксперимент, когда студент видит взаимосвязь между символами, переменными и итоговыми графиками на экране.
В сегменте профессиональной науки фокус OpenAI также смещен на практические, рутинные задачи. Общественность ожидала от семейства моделей GPT-5 полностью автономных научных открытий, однако исследователи используют ИИ преимущественно как утилитарный инструмент.
Биолог из Онкологического центра Фокс Чейз Роланд Данбрак применяет ChatGPT для написания кода и поиска литературы, фиксируя значительное снижение количества галлюцинаций в ссылках по сравнению с прошлыми версиями. Статистик из Калифорнийского университета в Беркли Никита Животовский использует систему для вычитки текстов и поиска математических опечаток.
Глава OpenAI по науке Кевин Вейл подтверждает такое позиционирование технологии. По его словам, ИИ вряд ли совершит единичное масштабное открытие в ближайшее время. Однако в 2026 году нейросети станут основой рабочего процесса ученых так же, как стали базой для программистов в 2025 году. Технология внесет вклад в десятки тысяч небольших научных достижений, обеспечив совокупное ускорение исследовательских процессов.
Разработчики OpenAI планируют встроить поведение «режима обучения» непосредственно в базовые веса будущих моделей после сбора дополнительных данных от пользователей. В дорожной карте образовательных продуктов заявлено добавление функций постановки учебных целей и отслеживания прогресса на протяжении нескольких сессий. В профессиональной среде компания продолжит курс на интеграцию алгоритмов в специализированный софт.
Introducing study mode — openai
ChatGPT — Release Notes — OpenAI Help Center — help.openai
OpenAI’s latest product lets you vibe code science — technologyreview, авторы: Will Douglas Heaven
OpenAI Gives ChatGPT Dynamic Explanations For STEM Concepts — forbes
OpenAI upgrades ChatGPT with interactive learning tools as — venturebeat, авторы: не указаны
New ChatGPT Study Mode Guides Students Through Questions — campustechnology, авторы: Rhea Kelly
ChatGPT Study Mode is live: all the details about OpenAI’s new — datastudios, авторы: Graziano Stefanelli






