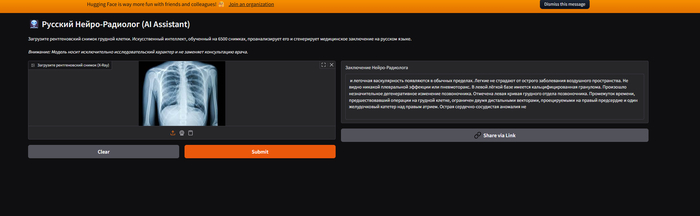
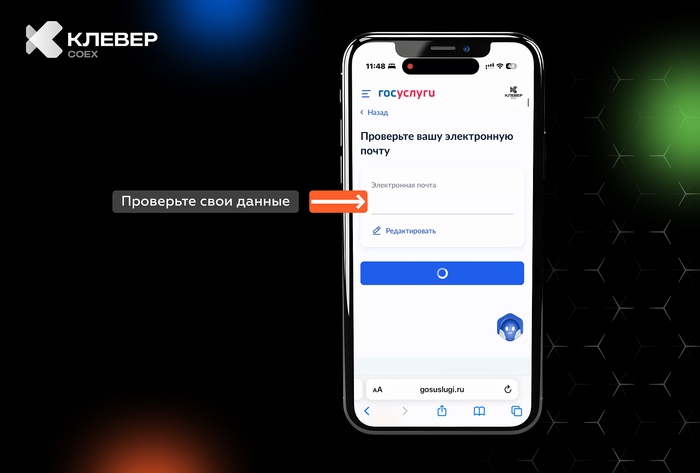
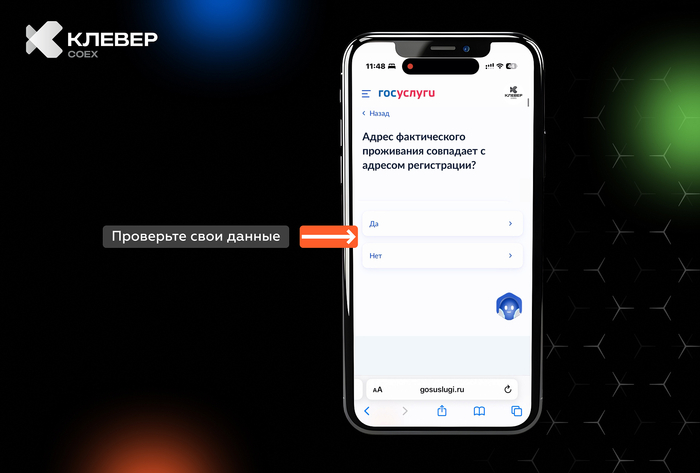
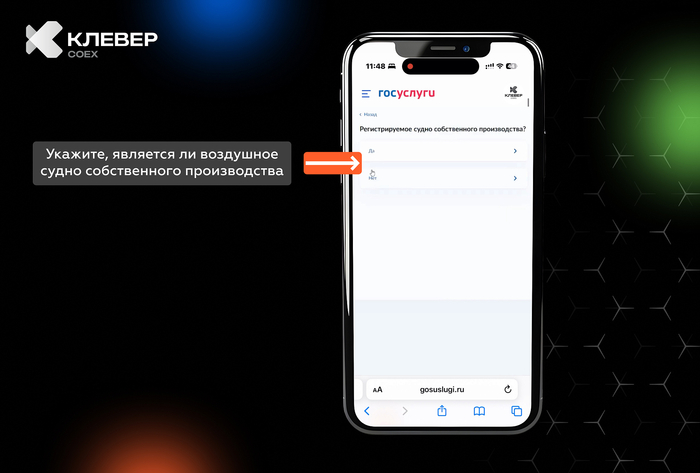
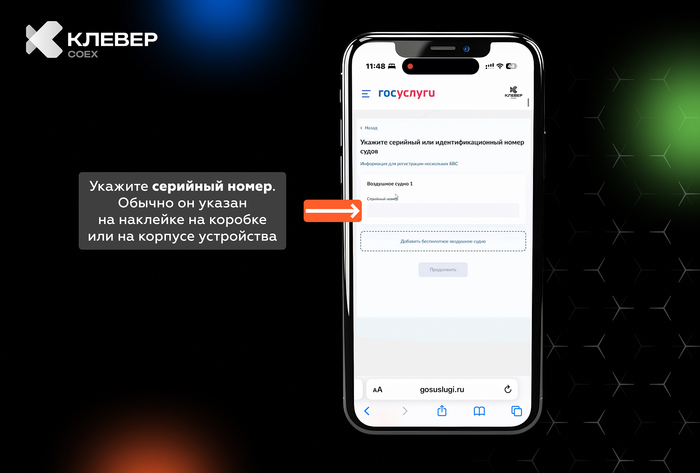
Знакомая ситуация: выходишь от рентгенолога, держишь в руках черно-белый снимок своих ребер, смотришь на него с умным видом, а в голове обезьянка бьет в тарелки. Потом читаешь бумажку с заключением: «консолидация», «эффузия», «кальцинаты»… Гуглишь это и мысленно пишешь завещание.
Сейчас из каждого утюга кричат про ChatGPT и искусственный интеллект. В медицине такие штуки уже есть, но в открытом доступе они почти все понимают только английский язык. Мне за державу стало обидно, и я решил собрать своего, русского Нейро-Радиолога.
Спойлер: в конце поста есть ссылка, где можно бесплатно потыкать в эту нейронку самому.
Как собрать кибер-врача из желудей и палок (и Python)
Если объяснять на пальцах, я взял два разных нейросетевых "мозга" и сшил их вместе, как Франкенштейна:
Глаза (Компьютерное зрение): Взял модель от Google (Vision Transformer), которая умеет смотреть на пиксели и понимать: "Ага, вот это ребро, а вот тут какое-то белое пятно".
Рот (Языковая модель): Взял ruGPT-3 от Сбера (это младший брат ChatGPT). У нее глаз нет, она умеет только тексты писать.
Я алгоритмически "пришил" зрение к генератору текста. Но чтобы этот мутант стал врачом, его нужно было учить.
Взял открытую базу клиники Индианского университета (США) — это больше 7000 реальных рентгенов грудной клетки вместе с заключениями настоящих американских врачей. Прогнал все эти заключения через нейросеть-переводчик на русский язык.
Потом арендовал бесплатные сервера на Kaggle (спасибо им за халявные видеокарты T4) и заставил нейросеть несколько часов подряд смотреть на снимок и читать диагноз. Ошибаешься — получаешь по цифровой шапке, угадываешь — молодец. И так 15 эпох подряд.
Что получилось? (Можно потрогать)
Получилась штуковина, которая реально сыпет медицинскими терминами и в большинстве случаев понимает, где здоровые легкие, а где пневмония или увеличенное сердце.
Я выкатил её в открытый доступ, сделал простенький веб-интерфейс. Денег не прошу, рекламы нет, регистрации тоже.
Гуглите "рентген легких норма" или "рентген пневмония".
Сохраняете картинку.
Закидываете по ссылке выше и жмете Submit.
Ждете 10-15 секунд (сервера там бесплатные, крутятся на обычных процах, так что имейте терпение).
Читаете, что она вам выдаст.
АХТУНГ ДЛЯ ИПОХОНДРИКОВ: Я программист, а не врач. Нейросеть обучалась в исследовательских целях за пару часов. Иногда она ловит "галлюцинации" и может найти у вас то, чего нет. ОНА НЕ ЗАМЕНЯЕТ ПОХОД К НАСТОЯЩЕМУ ВРАЧУ! Не вздумайте лечиться по её советам.
Для Лиги Программистов 🤓
Если тут есть дата-саентисты или те, кто изучает Machine Learning — я выложил весь код в Open Source. Там хардкор: обход блокировок сессий Kaggle, написание кастомного PyTorch датасета, ковыряние в конфигах VisionEncoderDecoderModel, чтобы заставить is_decoder=True работать со слоями Cross-Attention, и обучение в fp16 с градиентным накоплением.
Пишите в комменты, какие диагнозы она вам нагенерировала! Если пост зайдет, в следующий раз расскажу, как прикрутить к нейросети распознавание МРТ мозгов.
Мы — инди-команда из двух девушек, решивших оцифровать туристический рынок одного из самых необычных регионов — Абхазии. В этой истории переплелись две совершенно разные судьбы: основательница-абхазка, знающая каждый уголок своей родины, и я — СТО-казашка, которая до проекта жила в Куала-Лумпуре и вообще не представляла, где на карте находится Абхазия.
Из небоскрёбов в горы Кавказа Чтобы вы понимали масштаб контраста: до стартапа я жила в самом центре Куала-Лумпура. Каждое утро — ноутбук с видом на сияющие башни Петронас, стабильный гигабитный интернет, Grab, Foodpanda и доставка завтрака за 15 минут. Малайзия — это страна, где всё работает как часы и бронируется в два клика.
А потом я сажусь в самолёт и прилетаю в Абхазию. Вместо бетонных джунглей — настоящие. Вместо такси по приложению — дядя Аслан на «Ниве», который довезёт куда угодно и по дороге расскажет историю своего рода. Приехав «на пару недель» оценить масштаб бэкенда, я в итоге прожила здесь два месяца. И главное открытие, которое я увезла с собой — это люди. Здесь вместо споров тебе просто наливают кофе по-восточному и ведут показывать свой сад.
Боль рынка: «Тетрадка — наш лучший CRM» Когда мы начинали, туристический рынок Абхазии выглядел как цифровой заповедник. Огромная доля топовых гостевых домов вообще не представлена в сети. Почему?
Крупные агрегаторы забирают до 25%, что для небольшого семейного бизнеса просто неподъемно.
Жесткий цифровой барьер. «У меня всё в тетрадочке записано, зачем мне ваш экстранет?» — это реальная цитата, с которой начинался каждый второй диалог.
Мы поняли: сидеть в уютном коворкинге и парсить данные не получится. Придется ехать в горы, пить кофе и убеждать владельцев, что IT — это не страшно. Во время одной из таких вылазок к новому эко-отелю навигатор завел нас на старую лесовозную дорогу, где мы намертво посадили машину на пузо в грязь без грамма сотовой связи. Нас спас случайный охотник на УАЗике: он не просто нас вытащил, а потратил полчаса своего времени, угостил соком и не взял ни копейки.
Этот опыт напрямую повлиял на архитектуру нашего продукта. Мы поняли, что стандартная «калька» с Booking тут не взлетит.
Архитектура: почему мы отказались от обычного поиска Мы решили перевернуть классическую модель и реализовали механику C2B (обратный аукцион). Вот что мы собрали под капотом нашей платформы:
Тендер за туриста. Гость не просто листает каталог с завышенными ценами. Он вбивает свои даты, город и указывает свой бюджет. Система рассылает эту заявку всем подходящим хозяевам, и они сами откликаются на нее.
Автопредложения для ленивых. Учитывая любовь к «тетрадкам», мы не могли заставить хозяев сутками сидеть в админке. Мы написали логику автопредложений: хозяин один раз задает минимальную планку цены за номер. Если бюджет гостя подходит — автопредложение улетает само. Уведомления мгновенно приходят в Telegram и на почту.
Таймер на 4 часа. Заявка гостя живет ровно 4 часа. Это создает эффект горячего лида — хозяин знает, что клиент готов бронировать прямо сейчас. Поэтому владельцам выгодно отдавать «горящие» окна между заездами дешевле, лишь бы не простаивать.
Интерактивный торг. Гость имеет право ровно 1 раз нажать кнопку «запросить скидку». В ответ хозяин может согласиться, отказать или предложить свой компромиссный вариант. Настоящий южный торг, но полностью оцифрованный!
Итог За два месяца мы не просто собрали базу — мы создали мост между миром гор и современным миром бронирований. Я вернулась домой, оставив там работающий MVP, который сейчас начал прирастать трафиком.
Мы верим, что нестандартная логика кода и понимание менталитета могут победить глобальных гигантов на этом маленьком, но гордом рынке.
Команда разработчиков под руководством Андрея Бреслава, российского разработчика и автора языка программирования Kotlin, представила публичную альфа-версию нового инструмента для разработчиков — CodeSpeak. Платформа позиционируется как язык программирования нового поколения, в котором инженеры пишут спецификации на английском языке, а нейросети берут на себя генерацию, тестирование и рефакторинг исполняемого кода. Полноценное внедрение инструмента позволяет сократить объем кодовой базы в проектах в пять-десять раз. Технология поддерживает интеграцию в существующие сложные проекты на Python.
ИИ-язык, созданный для людей
CodeSpeak — язык программирования нового поколения на базе LLM
Переход от кода к управлению смыслом
В феврале 2026 года проект CodeSpeak перешел в стадию открытого альфа-тестирования, предложив инженерам концепцию поддержания спецификаций вместо исходного кода. Платформа представляет собой консольную утилиту, которая интегрируется в рабочее окружение и выступает прослойкой между разработчиком, пишущим требования на английском языке, и большой языковой моделью, которая эти требования реализует. В качестве основного движка генерации CodeSpeak использует модель Claude Opus 4.6 от компании Anthropic.
Основной метрикой эффективности CodeSpeak разработчики называют кратное уменьшение объема проекта, с которым напрямую взаимодействует человек. На примере перевода существующих open-source библиотек под управление платформы, объем исходных файлов сокращается в среднем от шести до десяти раз. Человеку остается поддерживать только короткий текстовый документ, описывающий суть алгоритма, в то время как техническая реализация скрыта под капотом системы тестирования и сборки.
В отличие от популярных чат-ботов и ИИ-агентов, CodeSpeak ориентирован не на быстрое прототипирование, а на долгосрочную поддержку продакшен-систем. Платформа изначально создавалась для работы в командах и подразумевает управление сложной архитектурой. Система умеет разворачивать проекты с нуля, однако ее главная особенность заключается в способности встраиваться в существующие кодовые базы и локально перехватывать управление отдельными модулями, не нарушая работу остального приложения.
Эволюция абстракций: от Kotlin к спецификациям
Переход к разработке на естественном языке стал для Андрея Бреслава логичным продолжением его предыдущей работы. Во время работы в JetBrains в 2010-х годах он спроектировал язык Kotlin с целью избавить Java-разработчиков от избыточного шаблонного кода. В то время синтаксис Kotlin позволил автоматизировать множество рутинных операций на уровне компилятора, сделав программы более читаемыми.
С развитием больших языковых моделей проблема избыточности вышла на новый уровень. По мнению Бреслава, огромный пласт современного кода является очевидным не только для инженера, но и для алгоритмов машинного обучения. Если раньше компилятору требовались точные синтаксические конструкции для понимания задачи, то сегодня нейросеть способна извлечь нужную техническую реализацию из своего внутреннего представления, обученного на всем мировом открытом коде. Это делает ручное написание стандартных алгоритмов неэффективной тратой времени.
При разработке CodeSpeak команда исходила из того, что программирование исторически двигалось по пути повышения уровня абстракций: от машинных кодов к ассемблеру, затем к языкам высокого уровня вроде C и Java. CodeSpeak рассматривается как следующий шаг в этой иерархии, где уровень абстракции поднимается до естественного языка, а языковая модель выполняет роль сверхмощного компилятора, генерирующего итоговую логику.
Архитектура файлов и автоматическое тестирование
Процесс разработки в CodeSpeak кардинально отличается от классического цикла. Точкой входа служит файл с расширением .cs.md, содержащий спецификацию конкретного модуля. Инженер описывает в нем структуру данных, логику обработки и форматы вывода. После запуска команды сборки система анализирует этот файл, собирает контекст проекта и передает план действий языковой модели.
Важнейшим элементом архитектуры платформы является автономное тестирование. В процессе сборки CodeSpeak не просто генерирует код, но и самостоятельно пишет модульные тесты для проверки заявленных в спецификации требований. Если тесты не проходят, система итеративно исправляет сгенерированный код до тех пор, пока функциональность не будет полностью соответствовать тексту. Для разработчика процесс выглядит как компиляция: на входе подается текстовое описание, на выходе получается рабочий и протестированный модуль.
В текущей версии система глубоко интегрирована с экосистемой Python и менеджером пакетов uv. Инструмент автоматически управляет виртуальными окружениями и зависимостями, позволяя создавать полноценные веб-приложения, например, на базе фреймворка Django, буквально из одного файла спецификации.
Анатомия спецификации: как ИИ понимает задачу
Чтобы понять, как абстрактный текст превращается в детерминированную логику, достаточно взглянуть на структуру типичного исходника CodeSpeak. На прикрепленном к статье демонстрационном видео показан процесс работы с платформой, где разработчик оперирует исключительно такими текстовыми контрактами.
Допустим, нам нужно написать конвертер для разбора сохраненных почтовых сообщений. Вместо написания десятков строк на Python разработчик создает файл eml_converter.cs.md со следующим содержимым:
# EmlConverter
Converts RFC 5322 email files (.eml) to Markdown using Python's built-in `email` module.
## Accepts
`.eml` extension or `message/rfc822` MIME type.
## Output Structure
1. **Headers section**: From, To, Cc, Subject, Date as `**Key:** value` pairs
2. **Body**: plain text preferred; if only HTML, convert to markdown
3. **Attachments section** (if any): list with filename, MIME type, human-readable size
Из этой спецификации система автоматически генерирует два артефакта: непосредственно исполняемый Python-компонент (например, eml_converter.py) и набор юнит-тестов (test_eml_converter.py). Система самостоятельно прогоняет тесты и убеждается, что функция корректно обрабатывает структуру файлов, извлекает нужные заголовки и не падает при отсутствии вложений.
Главная ценность такого подхода заключается в жесткой изоляции. Так как спецификация предельно четкая и имеет строгие контракты ввода-вывода, ИИ-агенту не нужно выдумывать, что именно реализовать, или галлюцинировать дополнительный функционал. Нейросеть ограничена рамками Markdown-файла. Если спустя время разработчику понадобится добавить извлечение даты получения письма, он просто допишет одну строку в раздел «Output Structure» в .cs.md файле. После команды сборки CodeSpeak обновит исключительно eml_converter.py и его тесты, совершенно не затрагивая остальную кодовую базу проекта.
Режим частичной интеграции и перевод легаси-кода под управление спецификациями
Понимая, что переписать существующие энтерпрайз-проекты с нуля практически невозможно, создатели CodeSpeak предусмотрели возможность частичной интеграции. В так называемом смешанном режиме (Mixed Mode) разработчик может инициализировать CodeSpeak внутри старого репозитория и строго ограничить список файлов, с которыми системе разрешено взаимодействовать. Это позволяет внедрять новые функции через текстовые спецификации, не подвергая риску устоявшуюся архитектуру.
Для работы с уже написанным кодом реализован механизм автоматического реверс-инжиниринга и передачи управления (команда takeover). Инженеру достаточно указать утилите конкретный исходный файл: система проанализирует алгоритмы и извлечет их бизнес-логику, сгенерировав для нее новый текстовый Markdown-файл со спецификацией. В официальном блоге проекта приводится показательный пример с конвертером форматов из библиотеки Microsoft MarkItDown, где CodeSpeak успешно превратил сотни строк Python-кода в лаконичное текстовое описание правил парсинга.
Как только существующий код переведен под контроль платформы, править оригинальные исходники вручную больше не нужно. Если в дальнейшем потребуется, например, добавить обработку нового поля в почтовом сообщении, разработчик просто вписывает одно дополнительное требование в Markdown-спецификацию. Опираясь на это обновление, CodeSpeak самостоятельно перепишет исходный код конвертера, создаст нужные вспомогательные методы и расширит тестовую базу для проверки новых требований.
Проблема потерянного контекста в ИИ-кодинге
Архитектура CodeSpeak решает одну из главных проблем современных ИИ-помощников вроде Cursor или GitHub Copilot. При использовании агентов инженер формулирует свои намерения в интерфейсе чата. Агент выдает готовый код, который затем отправляется в репозиторий проекта. При этом сам диалог, содержащий истинный смысл и бизнес-логику решения, теряется навсегда.
Бреслав отмечает, что при таком подходе коллеги разработчика видят только результат работы машины, а не изначальное намерение. Код становится языком общения между инженерами, хотя изначально он генерировался машиной для машины. В долгосрочной перспективе это приводит к усложнению код-ревью и потере контроля над архитектурой, так как тестировать и проверять огромные массивы сгенерированного кода без понимания изначальной логики практически невозможно.
Платформа CodeSpeak меняет этот парадокс, фиксируя диалог с ИИ в виде статических файлов спецификаций. Спецификация становится главным артефактом, подлежащим контролю версий и код-ревью. Команда обсуждает и утверждает смысловую часть алгоритма, оставляя валидацию синтаксиса на откуп автоматизированным тестам.
Следующий уровень абстракции: ИИ-агенты как авторы спецификаций
Подход с использованием формальных спецификаций решает проблему масштабирования и поддержки больших кодовых баз, однако ручное создание таких документов, вероятно, окажется лишь промежуточным этапом в эволюции разработки. Логика развития инструментов на базе больших языковых моделей указывает на то, что в обозримом будущем инженеры перестанут писать даже сами спецификации.
Вместо структурированных файлов разработчик будет формулировать бизнес-требования на свободном естественном языке — в виде высокоуровневых продуктовых пожеланий или пользовательских историй. ИИ-агенты возьмут на себя роль системных аналитиков: они будут переводить неструктурированный текст от человека в строгие формальные спецификации. Этот процесс станет логичным развитием механизма реверс-инжиниринга, который уже сейчас используется в CodeSpeak для генерации контрактов из старого кода. Сформировав спецификацию, машина самостоятельно сгенерирует по ней исполняемый код и тесты.
В такой парадигме роль программиста кардинально меняется. Навык написания формальных контрактов с нуля будет требоваться крайне редко, уступая место навыку аналитического чтения. Главной задачей разработчика станет умение читать спецификации, понимать заложенную в них архитектуру и верифицировать логику. Человеку предстоит выступать в роли валидатора, который проверяет, правильно ли ИИ-агент интерпретировал изначальную бизнес-идею, прежде чем эта спецификация превратится в работающий продукт. Фокус профессии окончательно сместится от создания строк кода или текста к экспертной оценке и управлению смыслом.
Иллюзия программирования естественным языком и преждевременные похороны джуниоров
Развитие ИИ-агентов породило в индустрии феномен, который западные разработчики в шутку окрестили vibe-coding — подходом, при котором человек просто описывает желаемый результат текстом, а нейросеть выдает готовое приложение. На фоне резкого скачка возможностей моделей многие компании начали замораживать наем младших разработчиков, ошибочно полагая, что алгоритмы способны полностью заменить начинающих специалистов.
В большом интервью, видео которого представлено ниже, Андрей Бреслав прямо называет массовый отказ от найма джуниоров глупой и временной ошибкой рынка. По его словам, управленцы сейчас ослеплены хайпом вокруг ИИ-инструментов, но эта эйфория неизбежно пройдет, когда индустрия столкнется с необходимостью поддерживать сгенерированные проекты на длинной дистанции. Рано или поздно бизнес осознает, что для развития технологий в индустрию должен постоянно поступать приток новых людей.
Главная проблема бездумного делегирования заключается в потере контроля. Бреслав подчеркивает, что если всю архитектурную работу начнут выполнять исключительно модели, а люди перестанут понимать, как именно работает код, это приведет к потере субъектности инженера. Задача человека — управлять так называемой «сущностной сложностью» (essential complexity), точно формулировать намерения и принимать технические решения. Машина выступает лишь исполнителем, и для корректной постановки задач ей по-прежнему требуется полноценный инженерный склад ума.
Начинающим разработчикам создатель Kotlin советует не поддаваться панике, а извлекать из ситуации выгоду. С одной стороны, необходимо в совершенстве освоить новые ИИ-инструменты, чтобы многократно повысить свою продуктивность. С другой — использовать освободившееся время для максимально глубокого погружения в фундаментальные, хардкорные основы программирования. Умение разобраться в том, как всё устроено «под капотом», вскоре станет редкой и крайне востребованной экспертизой на рынке, переполненном операторами нейросетей.
Ближайшие перспективы проекта
На данный момент CodeSpeak имеет статус альфа-версии и требует от пользователей готовности к техническим шероховатостям. Команда проекта фокусируется на улучшении механизмов синхронизации: система должна гарантировать, что при удалении кода его всегда можно в точности восстановить из спецификации, а любые изменения текста транслируются в адекватные изменения архитектуры. Несмотря на раннюю стадию, инструмент уже обозначает новый вектор развития индустрии, где главной компетенцией инженера становится умение структурировать сложность и управлять намерениями, а не владение синтаксисом конкретных языков программирования.
Андрей Бреслав — российский программист, один из создателей языка программирования Kotlin (руководитель группы разработчиков в компании JetBrains), сооснователь сервиса подбора психологов Alter.ru, основатель CodeSpeak.
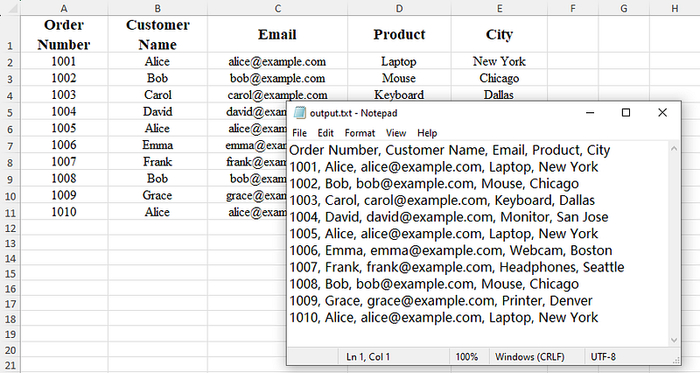
Файлы Excel отлично подходят для структурированного анализа данных, однако многие системы по-прежнему требуют простой TXT файлы для обмена данными, импорта в базы данных или интеграции с унаследованными системами.
Если вы строите автоматизированные рабочие процессы, программный экспорт Excel в TXT становится необходимым.
В этом уроке вы узнаете:
Как конвертировать Excel в TXT на Python
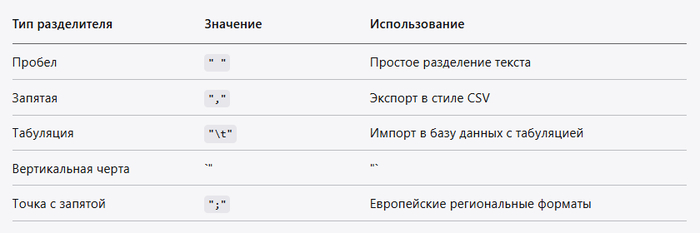
Как управлять разделителями (пробел, запятая, табуляция, вертикальная черта, точка с запятой)
Как правильно обрабатывать кодировку (избежать искаженного текста)
Как пакетно конвертировать несколько файлов Excel
Общие подводные камни и соображения по производительности
Мы будем использовать Free Spire.XLS для Python, который предоставляет чистый и надежный API для обработки Excel.
Зачем конвертировать Excel в TXT?
Конвертация Excel в TXT обычно необходима для:
Импорта данных в MySQL / Oracle / SQL Server
Передачи структурированных данных в унаследованные системы
ERP или банковских систем, требующих фиксированных текстовых форматов
Пакетной обработки данных
Межплатформенного обмена данными
В отличие от Excel (.xlsx), TXT файлы:
Легкие
Дружественные к системе
Имеют настраиваемые разделители
Позволяют гибкую кодировку
Тем не менее успешная конвертация зависит от двух критически важных факторов:
Настройка разделителя
Выбор кодировки
Давайте разберем их.
Установите Free Spire.XLS для Python
Мы будем использовать Free Spire.XLS для Python, который предоставляет чистый и надежный API для обработки Excel.
Всегда вызывайте workbook.Dispose(), чтобы освободить память
Избегайте одновременного открытия нескольких книг
Рассмотрите возможность обработки лист за листом, если размер файла большой
Используйте UTF-8 для снижения накладных расходов на кодирование
Для серверной среды:
Оберните логику конвертации в функции
Реализуйте обработку ошибок (try/except)
Записывайте неудачные конвертации
Общие проблемы и решения
1. Китайские символы отображаются искаженно
Причина: Неправильная кодировка
Решение:
Encoding.get_UTF8()
2. Столбцы не разделяются правильно
Причина: Неправильный разделитель
Решение: Подберите разделитель, требуемый целевой системой
3. Числа теряют форматирование
TXT файлы хранят только необработанный текст.
Если требуется форматирование (валюта, даты):
Предварительно отформатируйте данные в Excel перед экспортом
Или вручную обработайте форматирование перед сохранением
Заключительные мысли
Экспорт Excel в TXT на Python прост, но правильные детали имеют решающее значение. Выбор правильного разделителя и кодировки гарантирует, что ваши данные будут правильно работать с любой следующей системой. Как только основные моменты будут учтены, процесс конвертации становится надежным, масштабируемым и легким в автоматизации.
Всем привет! Это мой первый пост, и писать я не планировал, но я этой фиговиной не мог не поделиться. Моим хобби является программирование.
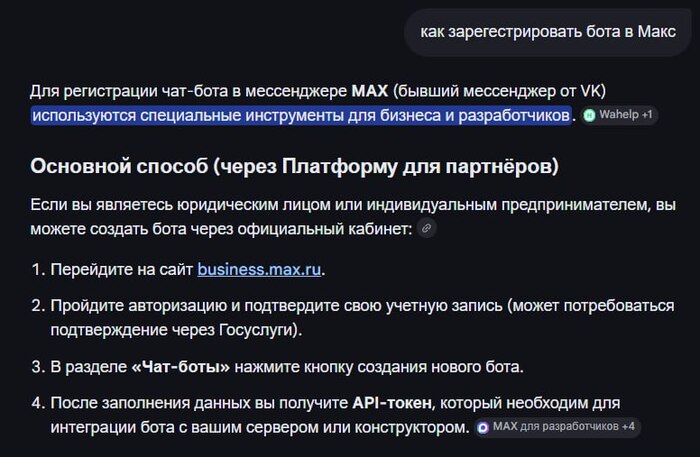
Я писал ботов под Дискорд и Телеграмм... И вот, в свете прошлых событий, решил узнать, а что же в MAX? Имеется ли возможность писать и интегрировать чат-ботов в этом мессенджере?
Оказывается, писать можно, под язык программирования Python существует уже не, только библиотек (одна, что немало важно для понимания основ, очень похожа на аналоги для Телеграмм)....
Так вот, писать то можно, и я спросил иностранную нейросеть, а как в данный момент регистрируются боты в МАХ, потому что это важный момент, и в ТГ это сделать очень просто. Хотите знать, что мне ответили?...
Вот:
Я должен быть ИП или юридическим лицом
То есть чтобы написать задроченного СМС-бота, который, например, будет писать новости для сообщества какой-нибудь игры в МАХ, я должен с какого то пня собрать (заполнить) документы и налипнуть на госпошлины и (или) налоги. Просто, чтобы написать бота в несколько строчек.
Куда то мы ни туда сворачиваем... 🤣
P.S. На данный момент другого способа регистрации бота в МАХ не существует. Колхоз дело добровольное...
P.P.S. Я тут подумал, а я же военнослужащий! Я не могу быть ИП и юридическим лицом, вроде как! 🤔 Мне нельзя вообще писать ботов под МАХ
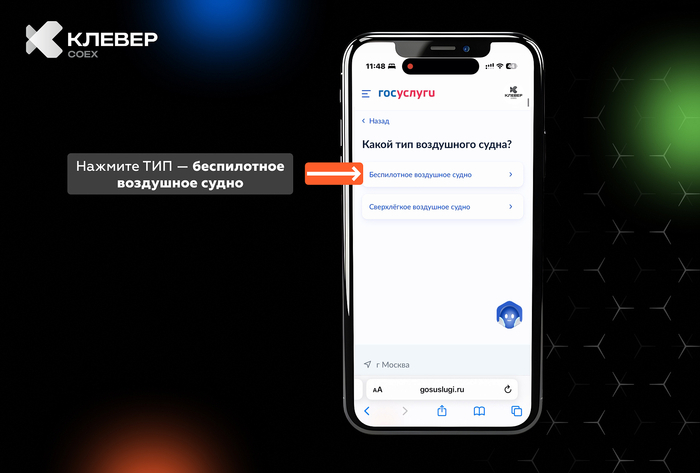
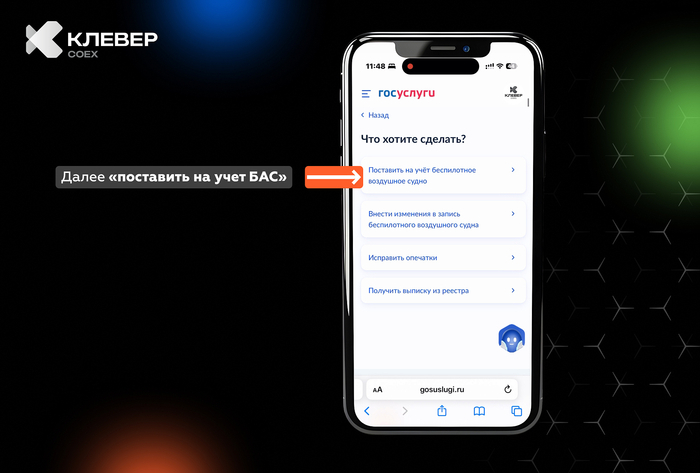
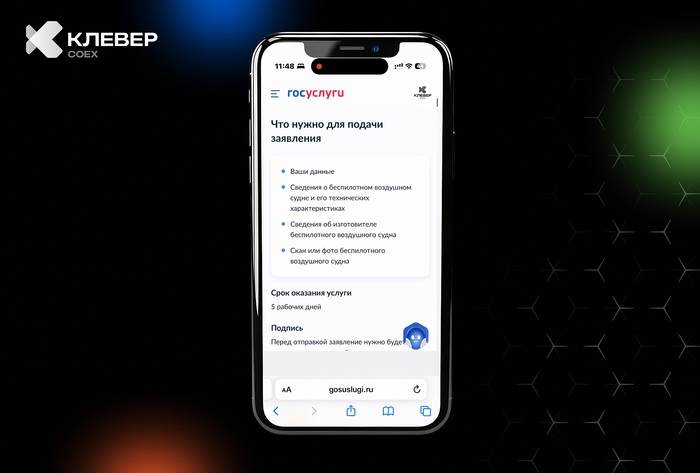
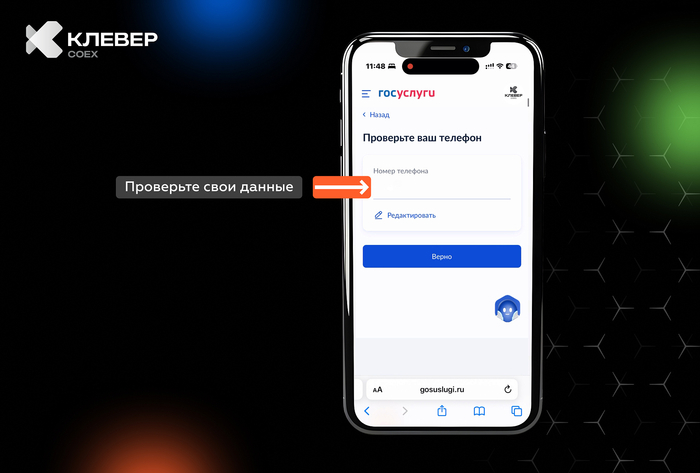
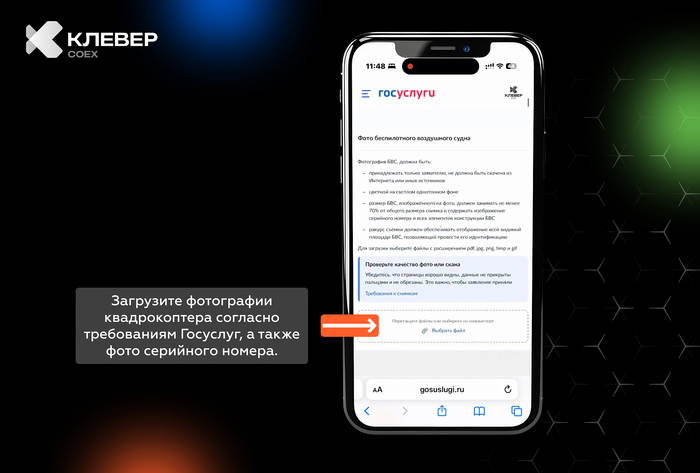
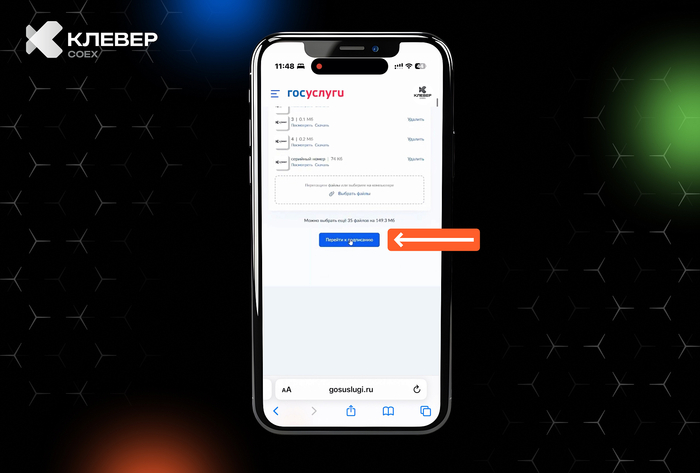
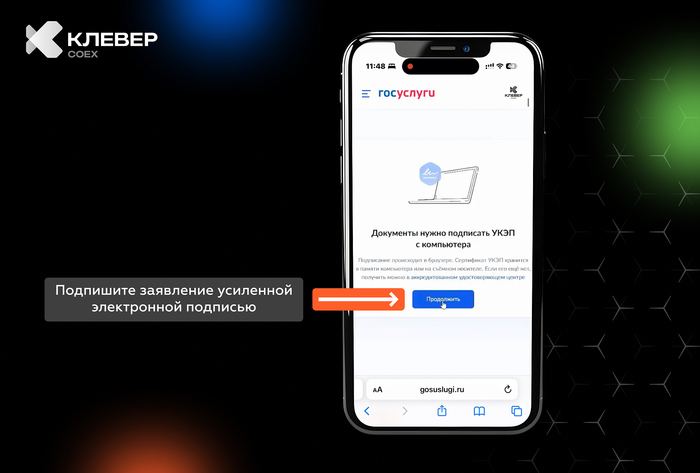
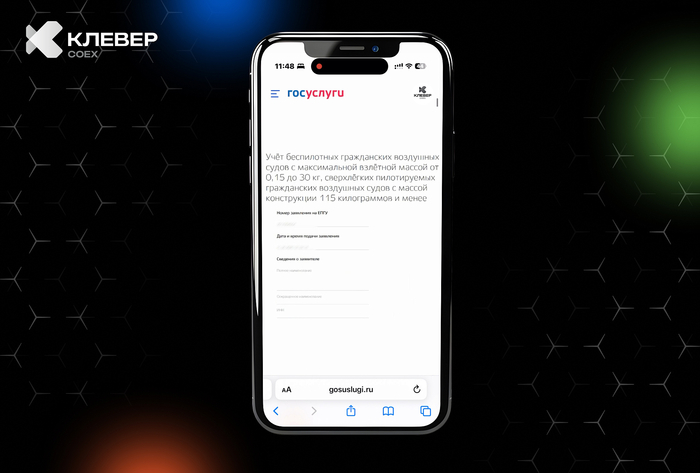
📲 В нашем Telegram-канале Клевер COEXделимся практическими лайфхаками по использованию квадрокоптеров, экспертными советами и интересными фактами из мира беспилотной авиации.
Илон Маск прогнозирует, что AGI появится уже в 2026 году.
Деми Хассабис, CEO DeepMind и лауреат Нобелевской премии 2024 года, оценивает вероятность достижения AGI к концу десятилетия (2030) примерно в 50%. Хассабис признаёт быстрый прогресс в верифицируемых областях (кодирование, математика), но подчёркивает нерешённые ограничения в области научных открытий и творческого мышления.
Эрик Шмидт, бывший CEO Google, заявил в апреле 2025 года, что AGI может быть достигнут через 3–5 лет.
По данным платформы Metaculus (февраль 2026), агрегированный прогноз от примерно 2000 участников даёт 25% вероятность AGI к 2029 году и 50% — к 2033 году.
И да, разработка AGI уже идет (OpenAI, DeepMind и Anthropic PBC). Но что такое AGI? И чем AGI отличается от AI? Для тех, кто не в теме: AI (Artificial Intelligence) и AGI (Artificial General Intelligence) отличаются тем, что AI — это узкоспециализированная система, а AGI — гипотетический тип искусственного интеллекта, способный решать широкий круг задач на уровне человека(или даже выше).
Что мы имеем уже сегодня?
К примеру, всем известный ChatGPT от openAI (версия 5.3):
В основе лежат трансформеры и тензоры. Но это лишь инструмент для обработки последовательностей. Весь "интеллект" сводится к одному: модель показывает гигантское количество текста, и она учится статистике — какие слова чаще всего идут после других.
Цитата из исследования OpenAI: Они сами признают, что их модели обучаются «без меток „правда/ложь“». Модель видит "только положительные примеры плавного языка".
Вывод: ChatGPT не знает, что 2+2=4. Он знает, что в 60% случаев после "2+2=" люди пишут "4". Разница колоссальная.
Галлюцинации? Есть!
Факт: Исследователи OpenAI подтверждают, что "галлюцинации остаются фундаментальной проблемой для всех крупных языковых моделей" и "полностью устранить их невозможно".
Почему? Потому что модель не может сказать "я не знаю". Её поощряют угадывать. Если она ответит неправильно, но уверенно, — это лучше, чем ничего, с точки зрения математики обучения.
Ситуация тяжелая. Только представьте, какая вычислительная мощность нужна, чтобы поддерживать жизнь AGI. Трансформеры, тензоры, большие нейросети и веса - очень тяжелая штука. Хоть openAI и нацелена на данный момент на улучшение производительности, толку все равно мало. С такими подходами от обычного AI до AGI мы вряд-ли дойдем. Тогда в чем суть моей статьи?
Если вы вчитались в мою теорию, то скорее всего понимаете, к чему я клоню.
На данный момент я взялся за разработку собственного AGI (наверное AGI =)) по моей теории. В чем отличие обычных алгоритмов ML от моих? Объясняю:
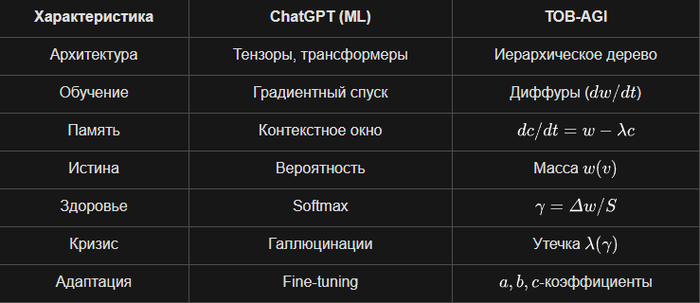
1. Архитектура: Дерево против Матрицы
У них: Тензоры, многомерные матрицы, линейная алгебра, трансформеры. Данные — это вектора в многомерном пространстве.
У меня: Иерархическое дерево с корнем, узлами, потомками. Мир — это структура, а не плоскость. Каждый узел — сущность со своей массой и памятью.
2. Обучение: Диффуры против Backpropagation
У них: Обратное распространение ошибки, градиентный спуск, миллионы итераций подгонки весов.
У меня: Система обыкновенных дифференциальных уравнений (ОДУ) — dw/dt = in - out - λw. Состояние эволюционирует во времени, а не "учится" на размеченных данных.
3. Память: Эволюционирующая переменная против Контекстного окна
У них: Внимание (attention) и контекст на токенах. Память ограничена размером окна (128k, 1M токенов), после диалога всё забывается.
У меня: dc/dt = w - λc c. Память c(t) — это динамическая переменная, которая накапливается и забывается со скоростью , как у живого существа.
4. Представление знаний: Масса против Вероятности
У них: Вероятность следующего токена. Модель не знает факты, она знает статистику: после "2+2=" в 60% случаев идет "4".
У меня: Масса w(v) в узле — это "количество сущности". Она сохраняется, перераспределяется, утекает. Это физическая метафора, а не статистическая.
5. Саморегуляция: Коэффициент упругости γ(v) против Softmax
У них: Функции активации (ReLU, softmax), которые просто преобразуют сигнал. Нет понятия "здоровья" системы.
У меня: γ(v) = Δw(v) / S(v) — отношение потерь узла к потерям потомков. Это мера "напряжения". Если близок к — система на грани коллапса и начинает иначе распределять ресурсы (меняются потоки Φ, растет утечка λ).
6. Потоки данных: Φ(p→c) против Attention
У них: Механизм внимания (attention) вычисляет веса между всеми парами токенов. Это и неинтерпретируемо.
У меня: Φ_{p→c}(t) = a_t(p) * w_t(p). Поток от родителя к потомку — это явная передача массы с коэффициентом случайности a_t. Прозрачно и физично.
7. Устойчивость: Спектральный анализ против Переобучения
У них: Переобучение, подгонка под шум. Чтобы бороться, добавляют dropout, регуляризацию — костыли.
У меня: ρ_loc(t) = max(|λ|) — спектральный радиус матрицы Якоби. Система сама знает, устойчива ли она (1/T ∫ρ dτ < 1). Это встроенный мониторинг стабильности.
8. Кризис и коллапс: γкрит и утечка λ против Галлюцинаций
У них: Галлюцинации — это "особенность, а не баг". Модель не знает, что она врет, и не может остановиться.
У меня: Когда превышает , система входит в режим усиленной утечки (λ = λ0 + λ1 * γ). Масса "утекает", система сбрасывает напряжение. Это предотвращает катастрофический сбой.
9. Адаптивность: a, b, c коэффициенты против Fine-tuning
У них: Донастройка (fine-tuning) — это переобучение всех весов под новую задачу. Дорого и долго.
У меня: a_t (случайность), b_t (отбор), c_t (память) — адаптивные коэффициенты, которые меняются в реальном времени в зависимости от состояния узла (шум ε_t, γ, память). Система подстраивается сама, без перезапуска.
10. Философия: Физика против Статистики
У них: "Все, что мы знаем о мире — это корреляции в данных". Бритва Оккама: мир плоский.
У меня: Мир иерархичен и динамичен. Знания — это структура, а не вектор. Память — это процесс, а не буфер. Интеллект — это способность сохранять устойчивость вблизи критической точки.
Вывод
ChatGPT — это не интеллект. Это стохастический попугай с 200 миллиардами кнопок. Он не мыслит — он подбирает статистически вероятное продолжение фразы. Он не помнит — у него просто большое окно контекста. Он не понимает, когда врёт — у него просто нет критерия истины.
ТОВ — это попытка построить систему, которая действительно думает, а не имитирует мышление. Где знание имеет вес, память имеет динамику, а устойчивость имеет математическое выражение.
Пока одни гонятся за количеством параметров, другие строят архитектуру мира. Догадайтесь, кто из них ближе к AGI.
ChatGPT говорит то, что вы хотите услышать. AGI скажет то, что должно быть сказано. Даже если вы не готовы это принять.
Выражаю свою благодарность тем, кто дочитал до конца, надеюсь данный материал вам зашел =)
Готов выслушать вашу критику и ваши идеи, буду рад почитать!