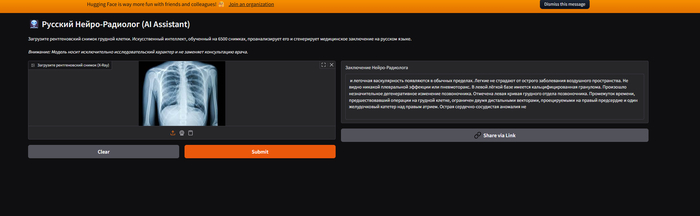
Знакомая ситуация: выходишь от рентгенолога, держишь в руках черно-белый снимок своих ребер, смотришь на него с умным видом, а в голове обезьянка бьет в тарелки. Потом читаешь бумажку с заключением: «консолидация», «эффузия», «кальцинаты»… Гуглишь это и мысленно пишешь завещание.
Сейчас из каждого утюга кричат про ChatGPT и искусственный интеллект. В медицине такие штуки уже есть, но в открытом доступе они почти все понимают только английский язык. Мне за державу стало обидно, и я решил собрать своего, русского Нейро-Радиолога.
Спойлер: в конце поста есть ссылка, где можно бесплатно потыкать в эту нейронку самому.
Как собрать кибер-врача из желудей и палок (и Python)
Если объяснять на пальцах, я взял два разных нейросетевых "мозга" и сшил их вместе, как Франкенштейна:
Глаза (Компьютерное зрение): Взял модель от Google (Vision Transformer), которая умеет смотреть на пиксели и понимать: "Ага, вот это ребро, а вот тут какое-то белое пятно".
Рот (Языковая модель): Взял ruGPT-3 от Сбера (это младший брат ChatGPT). У нее глаз нет, она умеет только тексты писать.
Я алгоритмически "пришил" зрение к генератору текста. Но чтобы этот мутант стал врачом, его нужно было учить.
Взял открытую базу клиники Индианского университета (США) — это больше 7000 реальных рентгенов грудной клетки вместе с заключениями настоящих американских врачей. Прогнал все эти заключения через нейросеть-переводчик на русский язык.
Потом арендовал бесплатные сервера на Kaggle (спасибо им за халявные видеокарты T4) и заставил нейросеть несколько часов подряд смотреть на снимок и читать диагноз. Ошибаешься — получаешь по цифровой шапке, угадываешь — молодец. И так 15 эпох подряд.
Что получилось? (Можно потрогать)
Получилась штуковина, которая реально сыпет медицинскими терминами и в большинстве случаев понимает, где здоровые легкие, а где пневмония или увеличенное сердце.
Я выкатил её в открытый доступ, сделал простенький веб-интерфейс. Денег не прошу, рекламы нет, регистрации тоже.
Гуглите "рентген легких норма" или "рентген пневмония".
Сохраняете картинку.
Закидываете по ссылке выше и жмете Submit.
Ждете 10-15 секунд (сервера там бесплатные, крутятся на обычных процах, так что имейте терпение).
Читаете, что она вам выдаст.
АХТУНГ ДЛЯ ИПОХОНДРИКОВ: Я программист, а не врач. Нейросеть обучалась в исследовательских целях за пару часов. Иногда она ловит "галлюцинации" и может найти у вас то, чего нет. ОНА НЕ ЗАМЕНЯЕТ ПОХОД К НАСТОЯЩЕМУ ВРАЧУ! Не вздумайте лечиться по её советам.
Для Лиги Программистов 🤓
Если тут есть дата-саентисты или те, кто изучает Machine Learning — я выложил весь код в Open Source. Там хардкор: обход блокировок сессий Kaggle, написание кастомного PyTorch датасета, ковыряние в конфигах VisionEncoderDecoderModel, чтобы заставить is_decoder=True работать со слоями Cross-Attention, и обучение в fp16 с градиентным накоплением.
Пишите в комменты, какие диагнозы она вам нагенерировала! Если пост зайдет, в следующий раз расскажу, как прикрутить к нейросети распознавание МРТ мозгов.
В недавнем посте я описывал довольно простую и известную схему искусственного интеллекта. Есть модель мира, она основана на авторитете и логике. Эта модель мира задаёт правила эволюции во времени динамической системы под названием «окружающий мир» (хотя правильнее было бы добавить в эту схему «я»). Затем другая часть алгоритма просто подставляет перебором список возможных действий над этой динамической системой и проигрывает во времени каждый вариант будущего. После этого смотрит, какой вариант будущего лучше соответствует выполнению поставленных целей в соответствии с их приоритетами, и подаёт команду действия на движущие части или мышцы. В целом, по логике, этот ИИ может выполнять довольно обширный класс задач, хотя и не понятно, может ли он полностью эмулировать интеллект человека.
Тем не менее, если мы функционалисты и отчасти считаем, что достаточно умная машина может обладать сознанием, то это сознание вроде бы должно быть заложено в данной алгоритмической схеме ИИ. Также мы считаем, что в сознании присутствуют входные данные алгоритма ИИ — потому что мы видим картинку перед глазами в своём сознании. Давайте рассмотрим цикл работы данного алгоритма и то, как он мог бы быть устроен.
Есть кусок данных от мира — предположим, картинка размером 1000 на 1000 пикселей, получаемая видеокамерой каждые 10 миллисекунд. Есть алгоритм предсказания будущей картинки мира на основе динамической системы «мир» + «действие» (действие совершается в тот же момент времени, что и берётся картинка). Затем происходит сравнение этих картинок. Например, из картинки видеокамеры (то, что произошло в реальности) попиксельно вычитается предсказанная для этого момента времени картинка (предсказание). Затем эта разность реальности и ожидания меняет правила эволюции динамической системы «мир», чтобы она лучше предсказывала будущее, и пытается найти новый список действий в этой динамической системе для достижения нужных целей в будущем.
Так как мы считаем, что сознание связано с входными данными и обработкой новых данных, то наиболее вероятный кандидат на подалгоритм сознания в таком ИИ — это подалгоритм, меняющий правила эволюции динамической системы «мир» на основе текущей ошибки предсказания будущего. Если мы будем думать о том, как может быть устроен этот подалгоритм «сознания», то на роль кандидатов в наше время инженеры рассматривают две системы: LLM (ChatGPT, Claude...) и граф логического вывода. При этом мы можем заметить, что LLM в последнее время неплохо справляются с логикой и математическими задачами. Для нашей задачи мы бы считали, что LLM не предсказывает следующее слово в тексте, а предсказывает следующий кадр картинки видеокамеры.
Однако существует проблема того, что LLM до сих пор трудно интерпретировать, поэтому мы можем рассмотреть простейшие схемы логического обновления правил эволюции динамической системы на основе ошибки предсказания и попытаться понять, чем этот алгоритм может быть ограничен. Как я рассматривал в предыдущих постах по теме ограничений сознания, сознание не может менять модель мира, не используя логических правил или внешнего авторитета — иначе оно могло бы переписать ценность наград. Значит, алгоритм работы сознания должен быть связан и быть похож на алгоритм работы систем автоматического вывода доказательств, таких как, например, Lean 4. Ведь изменение логической модели означает изменение правил эволюции системы «мир» — именно та задача, которая, как мы считаем, связана с сознанием.
Что ещё более важно: мы понимаем, что подобно тому, как сознание способно создавать вымышленные миры со своими правилами (например, Средиземье Толкина), так и этот алгоритм должен понимать разницу между гипотезой и теорией.
Дисклеймер: далее по тексту мы пока не будем явно разграничивать концепции «Я» и сознания.
Наше предположение состоит в том, что сознание не имеет прямого доступа к гипоталамусу — например, чтобы произвольно изменить температуру тела, — поскольку это было бы опасно для выживания. Данный факт существенно ограничивает сознание. Однако, исходя из предыдущих рассуждений, можно сделать вывод, что ограничения сознания гораздо шире: оно не способно произвольно менять логическую модель мира, не опираясь на правила логики или внешний авторитет. Иными словами, сознание практически не может напрямую влиять на систему вознаграждения мозга, а ведь именно эта система обязана включать в себя всю логическую модель мира (чтобы оценивать такие вещи, как стоимость зажигалки или целесообразность изучения топологии в вузе).
Тогда возникает вопрос: если сознание так сильно ограничено и многое в мозге ему неподвластно, то что оно, наоборот, может менять? Где тот холст, на котором оно способно писать или рисовать по своему желанию? Возможный ответ: этот холст — взаимодействие с неизвестным.
Очевидно, что сознание человека ограничено не только физиологией, но и логическими рамками. Например, человек может встать под стрелой башенного крана, но если он осознает опасность, то он вероятнее не сделает этого, так как выигрыш от демонстрации храбрости будет меньше риска погибнуть. Однако, если человек еще не знает, как работает башенный кран, он может строить гипотезы и совершать действия, не до конца понимая их последствий. В машинном обучении с подкреплением данное поведение соотносится с концепцией exploration vs exploitation (исследование против использования). С этой точки зрения, источником свободы сознания можно считать именно незнание того, как работает внешний мир, а также способность создавать и проверять гипотезы о принципах его устройства.
Если проанализировать «права», которыми обладает этот под-алгоритм сознания в структуре работы мозга, вырисовывается такая картина: сознание способно создавать и записывать промежуточные гипотезы о строении мира и проверять их, управляя мышцами. Но вот что интересно: зачастую гипотеза, ставшая теорией, превращается в ограничитель для самого сознания.
Например, человек впервые видит башенный кран и решает залезть в него, чтобы понажимать кнопки. Он видит, что одно нажатие отпускает груз, который падает на землю. Сопоставляя это с предыдущим опытом (падение тяжелых предметов) или с воспоминаниями об опыте других людей, человек, во-первых, сознательно обновляет модель мира, а во-вторых, вероятно, больше не будет ходить под стрелой крана. Это действительно любопытный процесс: права сознания постепенно ограничиваются работой самого же сознания, превращающего «свободное» исследование в жесткие правила модели мира.
Ученные Сиднейского университета создали прототип нанофотонного процессора для искусственного интеллекта, который обрабатывает данные с помощью света вместо электрического тока. В ходе экспериментов чип успешно классифицировал десятки тысяч медицинских изображений с точностью до 99 процентов. Новая архитектура выполняет вычисления за пикосекунды (триллионные доли секунды), полностью исключая проблему тепловыделения, и демонстрирует альтернативу перегревающимся кремниевым серверам современных дата-центров.
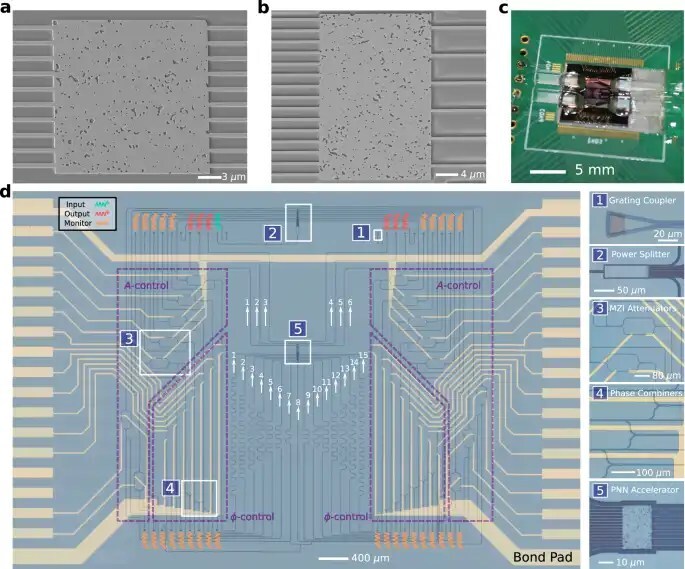
Фотография нанофотонного процессора под микроскопом
Снимки сканирующего электронного микроскопа чипов MNIST (20×20 мкм) и MedNIST (30×20 мкм), созданных на платформе кремний-на-изоляторе. Авторы: Joel Sved et al. Источник: Nature Communications.
На изображении представлены увеличенные микроскопические снимки нанофотонных ускорителей. Показаны оптические волноводы, подводящие свет к структуре с топологически оптимизированным материалом, где происходят физические вычисления. На нижних фрагментах видна интеграция чипа на печатную плату с золотыми контактами для взаимодействия с управляющей электроникой. Авторы: Joel Sved et al. Источник: Nature Communications.
Физика света против кремниевых ограничений
Исследовательская группа по фотонике Сиднейского университета под руководством профессора Сяокэ И представила работающий прототип сверхкомпактного оптического процессора. Устройство предназначено для выполнения математических операций, лежащих в основе машинного обучения. Особенность разработки заключается в полном отказе от перемещения электронов по металлическим проводникам — процесс обработки информации базируется на управлении фотонами.
Традиционные вычислительные системы при высоких нагрузках неизбежно выделяют колоссальный объем тепла из-за электрического сопротивления. Фотонный чип решает эту проблему на фундаментальном уровне. Свет проходит через наноструктуры без сопротивления, что делает генерацию тепла практически нулевой. Скорость выполнения одной операции при этом сокращается до пикосекундного диапазона — триллионных долей секунды. Это время, за которое свет физически успевает преодолеть структуру чипа.
Разработка была протестирована на базах данных MNIST (рукописные цифры) и MedNIST (более 10 000 биомедицинских изображений, включая МРТ грудной клетки и брюшной полости). В симуляциях система показала точность до 99 процентов. В реальных аппаратных экспериментах чип продемонстрировал точность классификации в 89 процентов для базы MNIST и 90 процентов для MedNIST, уверенно распознавая визуальные паттерны заболеваний на медицинских снимках.
Топологическая оптимизация вместо транзисторов
Индустрия искусственного интеллекта стремительно упирается в «энергетическую стену». Вычислительные центры требуют мегаватты электричества и миллионы литров воды для охлаждения серверов. Фотонные нейронные сети рассматриваются как логичный выход из кризиса, однако до сих пор их слабым местом оставались габариты. Создать оптический элемент сложнее, чем вытравить миллиард кремниевых транзисторов на одном квадратном миллиметре.
Австралийские исследователи обошли это ограничение с помощью метода обратного проектирования, основанного на 3D-моделировании электромагнитных полей. Вместо того чтобы строить нейросеть из классических оптических компонентов вроде интерферометра Маха-Цендера, инженеры позволили алгоритму самостоятельно рассчитать оптимальную форму материала.
Получившийся чип представляет собой сложную, визуально хаотичную наноструктуру из кремния и диоксида кремния. Внутри этой структуры световые волны (на длине волны 1550 нанометров) многократно рассеиваются и интерферируют. Проходя через материал, свет физически выполняет операцию умножения матриц. Размеры рабочей зоны составляют всего 20×20 микрометров для задачи распознавания цифр и 30×20 микрометров для медицинских изображений. По оценке создателей, такая архитектура обеспечивает феноменальную вычислительную плотность — около 400 миллионов обучаемых параметров на один квадратный миллиметр.
Решение проблемы нелинейности: опыт Массачусетского технологического института
Успех австралийской команды опирается на десятилетие предшествующих исследований в области физики оптических вычислений. Долгое время главным камнем преткновения для фотоники оставались нелинейные операции — функции активации, которые позволяют нейросети решать нешаблонные задачи и выявлять сложные закономерности. Фотоны практически не взаимодействуют друг с другом, из-за чего создание оптической нелинейности требовало огромных затрат энергии. В ранних системах оптические данные приходилось конвертировать обратно в электрические сигналы, отправлять на цифровой процессор для применения нелинейной функции, а затем снова переводить в свет.
Решение этой проблемы ранее предложила группа ученых из Массачусетского технологического института под руководством Дирка Энглунда и Саумила Бандиопадхьяя. В их архитектуре, описанной в журнале Nature Photonics, были применены нелинейные оптические функциональные блоки. Эти элементы отводят минимальную часть света на фотодиоды для преобразования в слабый ток, управляя нелинейностью без внешних усилителей.
В результате чип MIT смог выполнить весь цикл вычислений глубокой нейросети — как линейные, так и нелинейные операции — исключительно в оптическом домене менее чем за половину наносекунды с точностью выше 92 процентов. Исследователи доказали, что оптические процессоры могут обучаться в режиме реального времени, потребляя лишь малую долю энергии по сравнению с кремниевыми аналогами.
Коммерциализация: от стеклянных лабораторий к дата-центрам
Пока академические группы бьются над повышением точности и миниатюризацией вычислительных ядер, технологические компании уже адаптируют фотонику для нужд гиперскейлеров. Основное узкое место современных ИИ-кластеров — не только скорость самих вычислений, но и скорость передачи данных между видеокартами (GPU).
Компания Lightmatter выводит на рынок технологию 3D Co-Packaged Optics. Их решения, такие как фотонный суперчип Passage M1000, объединяют электронные интегральные схемы с фотонными напрямую в едином компактном модуле. Это снимает классические ограничения пропускной способности медных соединений, возникающие из-за физической нехватки места для контактов по периметру печатных плат. Что критически важно для обучения гигантских языковых моделей.
Фотонные модули Lightmatter способны передавать до 448 гигабит данных в секунду по одному оптическому каналу. Для достижения таких сверхскоростей применяется технология PAM4 — особый формат многоуровневой амплитудной модуляции, который позволяет «упаковывать» в каждый сигнал в два раза больше информации по сравнению с традиционными методами кодирования. Кроме того, архитектура системы позволяет производить горячую замену оптоволокна прямо в серверных стойках дата-центров.
Масштабирование оптического будущего
Команда Сиднейского университета уже подала патентную заявку на свою технологию нанофотонных чипов и работает над ее масштабированием. Следующим шагом станет объединение множества подобных блоков в крупные оптические сети для обработки фрагментированных данных по принципу сверточных нейросетей. Архитектура разрабатывается с расчетом на стандартные производственные процессы CMOS-фабрик. Переход индустрии на оптику — процесс не быстрый, однако успешная интеграция света на микроуровне доказывает, что у кремниевой монополии появился фундаментально обоснованный конкурент.
Физика света: от холодного вычисления в непрозрачном кремнии до природной инженерии
Чтобы понять фундаментальную разницу между классическим и оптическим процессором, достаточно спуститься на уровень элементарных частиц. В основе работы любого современного графического ускорителя лежит направленное движение электронов. Электрон — частица с ненулевой массой покоя и отрицательным электрическим зарядом. Когда миллиарды этих частиц под действием напряжения продираются сквозь кристаллическую решетку полупроводника, они неизбежно сталкиваются с ее атомами.
В физике твердого тела этот процесс называется рассеянием, а на практике он работает как микроскопическое трение. Электроны отдают часть своей кинетической энергии решетке, заставляя атомы вибрировать сильнее. На макроуровне эта вибрация превращается в стремительный нагрев. Именно из-за этого фундаментального физического ограничения современные серверные стойки с видеокартами требуют гигантских радиаторов, мощных вентиляторов и тысяч литров воды для охлаждения.
Фотонная архитектура меняет сами правила игры, отказываясь от заряженных электронов в пользу фотонов. У фотона нет ни электрического заряда, ни массы покоя. Когда инфракрасный луч лазера попадает в наноразмерный кремниевый волновод оптического чипа, он движется по нему, не испытывая классического электрического сопротивления.
Фотоны не взаимодействуют друг с другом так, как это делают заряженные частицы, и не «трутся» об атомы направляющей среды (для длины волны 1550 нанометров кремний абсолютно прозрачен). Они проходят сквозь сложную топологию чипа без передачи паразитной энергии материалу. В результате математические операции — интерференция и рассеяние света, заменяющие умножение матриц — происходят не только с максимально возможной физической скоростью, но и без генерации тепла. Фотонному процессору не нужны системы охлаждения просто потому, что в нем нет трения.
Парадоксы кремниевой фотоники: свет в непрозрачном кристалле
На первый взгляд использование кремния для создания оптического процессора кажется абсурдом. В нашем привычном понимании кремний — это основа классической микроэлектроники, серый кристалл с металлическим блеском, сквозь который невозможно ничего разглядеть. Как материал, абсолютно непрозрачный для человеческого глаза, может стать микроскопической магистралью для лазерных лучей?
Разгадка кроется в длине волны. То, что является непреодолимой стеной для видимого спектра, для инфракрасного излучения оказывается открытой дверью. На длине волны 1550 нанометров (именно она используется в разработке Сиднейского университета и является стандартом для оптоволоконной связи) чистейший кристаллический кремний становится прозрачным, словно высококачественное оконное стекло.
Однако просто пропустить свет сквозь материал недостаточно — физикам нужно заставить луч поворачивать, делиться и интерферировать на площадке размером тоньше человеческого волоса. Для этого инженеры используют технологическую платформу «кремний-на-изоляторе». Тончайший слой кремния укладывается на подложку из диоксида кремния, после чего в верхнем слое вытравливаются микроскопические дорожки — оптические волноводы.
Здесь начинает работать фундаментальный закон оптики — полное внутреннее отражение. Кремний имеет очень высокий показатель преломления по сравнению с окружающим его диоксидом. Когда инфракрасный лазер попадает в такой кремниевый канал, резкий контраст оптических плотностей материалов превращает границы волновода в идеальное зеркало. Свет оказывается запертым внутри: он отскакивает от стенок кремниевой «проволоки» и мчится по извилистому наноразмерному лабиринту чипа, не рассеиваясь наружу. Именно этот физический трюк позволяет ученым использовать традиционное оборудование заводов по производству электроники для создания сложнейших световых процессоров.
Оптический обман: архитектура бабочки
Глядя на микроскопический снимок нового нанофотонного процессора, можно заметить, что его рабочая зона совершенно не похожа на строгую прямоугольную геометрию классических электронных микросхем. Она выглядит хаотичной, текучей, почти органической. Подобный подход к управлению светом за счет сложнейшей физической формы ученые давно подсмотрели у самой природы. Самый яркий пример такой оптической инженерии — крылья тропических бабочек рода морфо.
Знаменитый пронзительно-синий цвет их крыльев возникает не благодаря биологическим пигментам или химическим красителям. Если измельчить чешуйку такого крыла в пыль, сияющий оттенок исчезнет, оставив лишь невзрачную серую массу. Секрет кроется в явлении структурной окраски. На поверхности крыла расположены миллионы микроскопических элементов со сложной, напоминающей ветвящиеся деревья, наноструктурой. Когда свет попадает на этот рельеф, он многократно преломляется и интерферирует. Физическая архитектура чешуйки выверена эволюцией так, что световые волны синего спектра накладываются и усиливают друг друга, в то время как волны других цветов взаимно гасятся.
Создавая свой ИИ-чип методом топологической оптимизации, австралийские инженеры применили ровно тот же фундаментальный принцип. Алгоритм буквально «вылепил» из кремния сложнейший нанорельеф, который работает как идеальный оптический лабиринт. Точно так же, как крыло бабочки манипулирует светом для создания безупречного синего цвета, кремниевая структура процессора заставляет инфракрасные лазерные волны интерферировать и рассеиваться по строго заданным математическим векторам. В обоих случаях сложнейший результат — будь то потрясающий визуальный эффект или нейросетевая классификация медицинского снимка — достигается исключительно за счет виртуозной геометрии наноструктур: хитина у бабочки и кремния в процессоре.
Илон Маск прогнозирует, что AGI появится уже в 2026 году.
Деми Хассабис, CEO DeepMind и лауреат Нобелевской премии 2024 года, оценивает вероятность достижения AGI к концу десятилетия (2030) примерно в 50%. Хассабис признаёт быстрый прогресс в верифицируемых областях (кодирование, математика), но подчёркивает нерешённые ограничения в области научных открытий и творческого мышления.
Эрик Шмидт, бывший CEO Google, заявил в апреле 2025 года, что AGI может быть достигнут через 3–5 лет.
По данным платформы Metaculus (февраль 2026), агрегированный прогноз от примерно 2000 участников даёт 25% вероятность AGI к 2029 году и 50% — к 2033 году.
И да, разработка AGI уже идет (OpenAI, DeepMind и Anthropic PBC). Но что такое AGI? И чем AGI отличается от AI? Для тех, кто не в теме: AI (Artificial Intelligence) и AGI (Artificial General Intelligence) отличаются тем, что AI — это узкоспециализированная система, а AGI — гипотетический тип искусственного интеллекта, способный решать широкий круг задач на уровне человека(или даже выше).
Что мы имеем уже сегодня?
К примеру, всем известный ChatGPT от openAI (версия 5.3):
В основе лежат трансформеры и тензоры. Но это лишь инструмент для обработки последовательностей. Весь "интеллект" сводится к одному: модель показывает гигантское количество текста, и она учится статистике — какие слова чаще всего идут после других.
Цитата из исследования OpenAI: Они сами признают, что их модели обучаются «без меток „правда/ложь“». Модель видит "только положительные примеры плавного языка".
Вывод: ChatGPT не знает, что 2+2=4. Он знает, что в 60% случаев после "2+2=" люди пишут "4". Разница колоссальная.
Галлюцинации? Есть!
Факт: Исследователи OpenAI подтверждают, что "галлюцинации остаются фундаментальной проблемой для всех крупных языковых моделей" и "полностью устранить их невозможно".
Почему? Потому что модель не может сказать "я не знаю". Её поощряют угадывать. Если она ответит неправильно, но уверенно, — это лучше, чем ничего, с точки зрения математики обучения.
Ситуация тяжелая. Только представьте, какая вычислительная мощность нужна, чтобы поддерживать жизнь AGI. Трансформеры, тензоры, большие нейросети и веса - очень тяжелая штука. Хоть openAI и нацелена на данный момент на улучшение производительности, толку все равно мало. С такими подходами от обычного AI до AGI мы вряд-ли дойдем. Тогда в чем суть моей статьи?
Если вы вчитались в мою теорию, то скорее всего понимаете, к чему я клоню.
На данный момент я взялся за разработку собственного AGI (наверное AGI =)) по моей теории. В чем отличие обычных алгоритмов ML от моих? Объясняю:
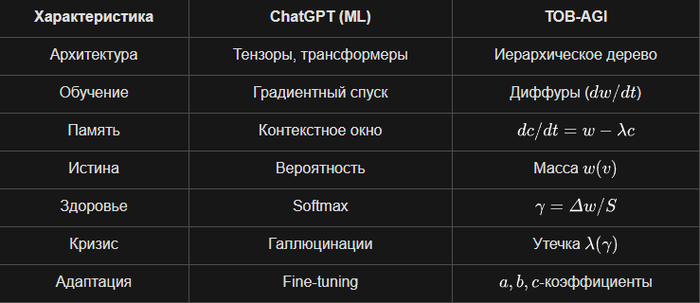
1. Архитектура: Дерево против Матрицы
У них: Тензоры, многомерные матрицы, линейная алгебра, трансформеры. Данные — это вектора в многомерном пространстве.
У меня: Иерархическое дерево с корнем, узлами, потомками. Мир — это структура, а не плоскость. Каждый узел — сущность со своей массой и памятью.
2. Обучение: Диффуры против Backpropagation
У них: Обратное распространение ошибки, градиентный спуск, миллионы итераций подгонки весов.
У меня: Система обыкновенных дифференциальных уравнений (ОДУ) — dw/dt = in - out - λw. Состояние эволюционирует во времени, а не "учится" на размеченных данных.
3. Память: Эволюционирующая переменная против Контекстного окна
У них: Внимание (attention) и контекст на токенах. Память ограничена размером окна (128k, 1M токенов), после диалога всё забывается.
У меня: dc/dt = w - λc c. Память c(t) — это динамическая переменная, которая накапливается и забывается со скоростью , как у живого существа.
4. Представление знаний: Масса против Вероятности
У них: Вероятность следующего токена. Модель не знает факты, она знает статистику: после "2+2=" в 60% случаев идет "4".
У меня: Масса w(v) в узле — это "количество сущности". Она сохраняется, перераспределяется, утекает. Это физическая метафора, а не статистическая.
5. Саморегуляция: Коэффициент упругости γ(v) против Softmax
У них: Функции активации (ReLU, softmax), которые просто преобразуют сигнал. Нет понятия "здоровья" системы.
У меня: γ(v) = Δw(v) / S(v) — отношение потерь узла к потерям потомков. Это мера "напряжения". Если близок к — система на грани коллапса и начинает иначе распределять ресурсы (меняются потоки Φ, растет утечка λ).
6. Потоки данных: Φ(p→c) против Attention
У них: Механизм внимания (attention) вычисляет веса между всеми парами токенов. Это и неинтерпретируемо.
У меня: Φ_{p→c}(t) = a_t(p) * w_t(p). Поток от родителя к потомку — это явная передача массы с коэффициентом случайности a_t. Прозрачно и физично.
7. Устойчивость: Спектральный анализ против Переобучения
У них: Переобучение, подгонка под шум. Чтобы бороться, добавляют dropout, регуляризацию — костыли.
У меня: ρ_loc(t) = max(|λ|) — спектральный радиус матрицы Якоби. Система сама знает, устойчива ли она (1/T ∫ρ dτ < 1). Это встроенный мониторинг стабильности.
8. Кризис и коллапс: γкрит и утечка λ против Галлюцинаций
У них: Галлюцинации — это "особенность, а не баг". Модель не знает, что она врет, и не может остановиться.
У меня: Когда превышает , система входит в режим усиленной утечки (λ = λ0 + λ1 * γ). Масса "утекает", система сбрасывает напряжение. Это предотвращает катастрофический сбой.
9. Адаптивность: a, b, c коэффициенты против Fine-tuning
У них: Донастройка (fine-tuning) — это переобучение всех весов под новую задачу. Дорого и долго.
У меня: a_t (случайность), b_t (отбор), c_t (память) — адаптивные коэффициенты, которые меняются в реальном времени в зависимости от состояния узла (шум ε_t, γ, память). Система подстраивается сама, без перезапуска.
10. Философия: Физика против Статистики
У них: "Все, что мы знаем о мире — это корреляции в данных". Бритва Оккама: мир плоский.
У меня: Мир иерархичен и динамичен. Знания — это структура, а не вектор. Память — это процесс, а не буфер. Интеллект — это способность сохранять устойчивость вблизи критической точки.
Вывод
ChatGPT — это не интеллект. Это стохастический попугай с 200 миллиардами кнопок. Он не мыслит — он подбирает статистически вероятное продолжение фразы. Он не помнит — у него просто большое окно контекста. Он не понимает, когда врёт — у него просто нет критерия истины.
ТОВ — это попытка построить систему, которая действительно думает, а не имитирует мышление. Где знание имеет вес, память имеет динамику, а устойчивость имеет математическое выражение.
Пока одни гонятся за количеством параметров, другие строят архитектуру мира. Догадайтесь, кто из них ближе к AGI.
ChatGPT говорит то, что вы хотите услышать. AGI скажет то, что должно быть сказано. Даже если вы не готовы это принять.
Выражаю свою благодарность тем, кто дочитал до конца, надеюсь данный материал вам зашел =)
Готов выслушать вашу критику и ваши идеи, буду рад почитать!
Исследователи совершили прорыв в нейробиологии, успешно реконструировав динамичное видео исключительно по активности клеток зрительной коры мыши. Пока животные смотрели черно-белые ролики со спортивной гимнастикой и рестлингом, алгоритм считывал вспышки кальция в восьми тысячах нейронов и покадрово восстанавливал увиденное. Технология достигла беспрецедентной точности: на итоговых кадрах можно различить силуэты людей и контуры предметов. Это приближает науку к пониманию того, как именно мозг искажает физическую реальность.
Реконструкция видео из активности зрительной коры мыши
Слева направо: оригинальные кадры и то, как их «увидел» алгоритм, считав активность нейронов мыши. Авторы: Joel Bauer, Troy W Margrie, Claudia Clopath. Источник: eLife / The Guardian.
На изображении представлены раскадровки: в верхнем ряду показаны оригинальные черно-белые кадры из видеороликов, а в нижнем — размытые, но узнаваемые силуэты, восстановленные искусственным интеллектом исключительно на основе активности нейронов зрительной коры мыши. Авторы: Joel Bauer, Troy W Margrie, Claudia Clopath. Источник: eLife / The Guardian.
Прямая трансляция из коры головного мозга
Команда нейробиологов под руководством Джоэла Бауэра из Центра Сейнсбери Уэлком при Университетском колледже Лондона (UCL) опубликовала результаты уникального эксперимента. Ученые смогли восстановить десятисекундные видеоролики с частотой 30 кадров в секунду, используя исключительно записи активности клеток зрительной коры живых мышей. Результаты исследования были представлены 10 марта 2026 года в научном журнале eLife.
В ходе эксперимента грызунам показывали черно-белые клипы, на которых люди занимались различными видами спорта, включая спортивную гимнастику, верховую езду и рестлинг. В это время исследователи фиксировали активность мозга животных с помощью двухфотонной кальциевой микроскопии. Этот метод позволяет визуализировать локальные всплески кальция в тканях, точно определяя, какие именно клетки мозга возбуждаются в конкретную долю секунды. Для каждой из десяти мышей, участвовавших в проекте, ученые собрали данные примерно от восьми тысяч отдельных нейронов.
Для расшифровки полученного массива данных применялась динамическая модель нейронного кодирования, изначально созданная для научного соревнования Sensorium 2023. Алгоритм анализировал не только оптические стимулы, но и физиологические параметры мыши, поскольку зрительная кора грызунов сильно реагирует на сторонние факторы. Сопоставив нейронные реакции с видеорядом, система достигла пиксельной корреляции между оригиналом и реконструкцией на уровне 0.57. Это более чем в два раза превышает результаты предыдущих попыток чтения статических изображений из мозга мышей.
Предел разрешения: от МРТ к отдельным клеткам
В последние годы новости о чтении мыслей появляются регулярно, однако большинство громких прорывов связано с функциональной магнитно-резонансной томографией (фМРТ) человека. Проблема фМРТ заключается в ее низком пространственном и временном разрешении. Томограф фиксирует приток крови к обширным зонам мозга с задержкой в несколько секунд. Чтобы получить из этого красивую картинку, исследователи обычно используют генеративные нейросети вроде Stable Diffusion, которые дорисовывают детали на основе семантического смысла. Иными словами, если мозг человека реагирует на концепцию красной машины, ИИ просто рисует красивую красную машину из своей базы данных, а не то конкретное изображение, которое видят глаза.
Эксперимент британской команды радикально отличается от этого подхода. Ученые не использовали готовые генеративные сети для дорисовки смысла. Они опирались на сырые данные, считывая импульсы отдельных нейронов с частотой восемь герц на площади мозга размером 630 на 630 микрометров. Они напрямую заглянули в операционную систему зрения млекопитающего, а не пытались угадать ассоциации.
При этом ИИ-модели пришлось учитывать крайне специфическую физиологию грызунов. Активность нейронов в первичной зрительной коре мыши сильно зависит от уровня ее возбуждения и физической активности. То, как мышь воспринимает картинку, меняется в зависимости от того, бежит она по беговой дорожке или стоит на месте, а также от диаметра ее зрачка. Алгоритму пришлось интегрировать эти поведенческие переменные в свои вычисления, чтобы отделить чистый визуальный сигнал от моторного шума.
Градиентный спуск на пустом экране
Механика того, как алгоритм достает картинку из мозга, напоминает обратную инженерию восприятия. Ученые не обучали нейросеть напрямую переводить кальциевые вспышки в пиксели. Вместо этого они взяли модель, которая хорошо предсказывает, как поведут себя нейроны при просмотре определенного видео. Затем исследователи подали на вход модели пустой серый экран и заставили ИИ предсказать реакцию нейронов на эту пустоту.
Естественно, предсказанная реакция на серый экран не совпала с реальной записью мозга мыши, смотревшей рестлинг. Тогда алгоритм начал покадрово изменять пиксели серого экрана с помощью метода градиентного спуска. Пиксели корректировались тысячу раз до тех пор, пока виртуальный отклик модели полностью не совпал с физиологической записью из мозга грызуна. Как только математическая ошибка между симуляцией и реальностью свелась к минимуму, на экране из серого шума проступили узнаваемые контуры людей и движущихся объектов.
Чтобы добиться максимальной чистоты изображения, авторы применили метод ансамблирования. Однократный прогон модели давал картинку, переполненную высокочастотным пространственным и временным шумом. Ученые обучили семь независимых версий алгоритма на разных наборах данных, заставили каждую реконструировать видео, а затем усреднили их результаты. Это позволило повысить качество итогового ролика почти на треть.
Исследователи также выяснили, насколько критично количество записываемых клеток. В ходе компьютерной симуляции они попробовали искусственно отключать часть нейронов. Оказалось, что удаление половины из восьми тысяч клеток снижает качество видео лишь на десять процентов. Однако потеря трех четвертей массива обрушивает точность уже на четверть. Это дает ценный ориентир для будущих нейробиологических экспериментов: для стабильного чтения зрительных образов достаточно плотности порядка десяти-двадцати тысяч нейронов на квадратный миллиметр коры.
Каково это — быть летучей мышью
Хотя восстановленные ролики выглядят зернистыми, они полностью соответствуют физиологическим ограничениям самих животных. Зрение мыши примерно в шесть раз хуже человеческого, поэтому алгоритм физически не мог бы восстановить сверхчеткие детали, которых мозг грызуна просто не регистрирует. Тесты с синтетическим визуальным шумом показали, что модель перестает корректно собирать картинку на высоких пространственных частотах, выходящих за рамки мышиной остроты зрения.
Джоэл Бауэр подчеркивает, что мозг не хранит идеальную попиксельную копию мира. Зрительный тракт искажает и трансформирует картинку, усиливая одни признаки и подавляя другие. Эти отклонения от реальности — не баг, а эволюционная фича, отражающая то, как разум адаптирует сенсорную информацию под задачи выживания.
Успех на животных неизбежно вызывает вопросы о применении технологии к людям. Бауэр смотрит на такую перспективу с осторожностью, отмечая, что если технология сможет реконструировать не только то, что человек видит глазами, но и то, что он воображает, возникнет колоссальная угроза приватности.
Тем не менее для фундаментальной биологии открываются невероятные перспективы. Если система может считывать внутренние образы напрямую из нейронов, в будущем ученые смогут выяснить, что именно видят животные во сне, поддаются ли они человеческим оптическим иллюзиям и какие визуальные искажения они испытывают под воздействием психоделиков. Как отметил Бауэр, эта технология может привести человечество к очень глубокой форме эмпатии по отношению к другим видам, наконец позволив нам научно ответить на классический философский вопрос: каково это — воспринимать мир мозгом другого существа.
Что дальше: за пределами черно-белых силуэтов
В ближайших планах команды — расширение поля зрения при реконструкции. Текущие алгоритмы работают с данными, собранными только с одного участка зрительной коры, что дает эффект узкого замочного окна. В будущем ученые намерены объединить сигналы от обоих глаз животного, чтобы создать панорамную картину его зрительного опыта. Главный же открытый вопрос заключается в том, удастся ли с помощью этого метода отследить, как меняется репрезентация одних и тех же объектов в мозгу по мере того, как животное обучается или переносит фокус своего внимания.
Корочь, сидел я тут на днях, пытался ChatGPT заставить найти мне 100 потенциальных клиентов для проекта. Казалось бы, что может пойти нитак? Он нашел 30, зевнул (метафорически) и говорит: "хватит, дружище". Попросил Гигачат решить интеграл — начал галлюцинировать и выдал красивый, но абсолютно неправильный ответ. А когда китайского Qwen 3 попросил переписать статью в стиле конкретного редактора издания... получил такую безликую воду и пачку бреда(что опасно, ведь этого изначально в моем тексте не было), что проще было самому с нуля написать.
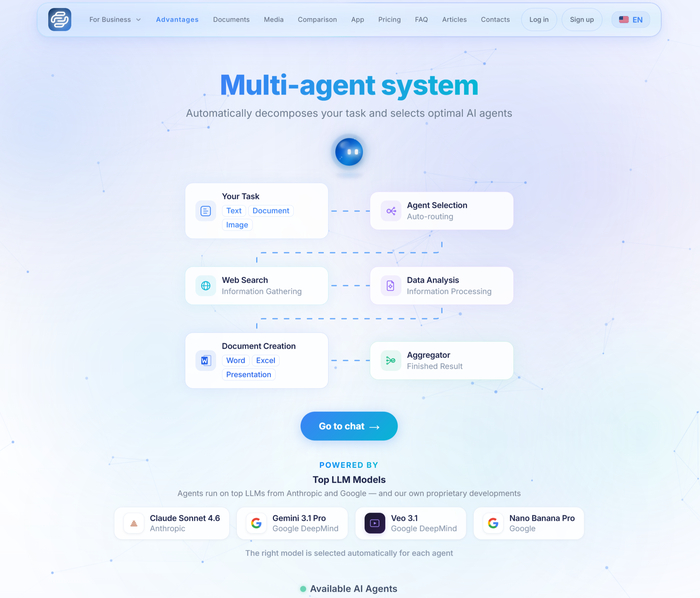
Знакомо? Вот и мне надоело. А тут как раз вышла мультиагентная штуковина под названием Fractal Agents AI, и решил ее протестировать — это не очередной чат-бот-универсал, а целая команда специализированных ИИ-агентов. Типа как Мстители, только для рабочих задач 😉
Fractal Agents AI и флоу агентов
Как это работает? Внутрянка без воды
Представьте: вы приходите не к одному перегруженному ChatGPT, а в агентство, где сидят узкие специалисты. Есть маркетолог, поисковик, аналитик, математик, редактор и еще 15+ ИИ-агентов. Ставите задачу — система сама решает, кого подключить.
Тут я отмечу, что видел много ИИ сервисов, но обычно там какая-то одна модель "думает" и выполняет все действия - а тут иначе, как я понял под каждую вашу таску система САМА выбирает модель-агента (будь то LLM типа DeepSeek, Gemini, ChatGPT, Kimi, Perplexity) и даже делает это прямо на каждом шаге выполнения, если у вас в задаче шагов несколько.
Знаете, это что-то новенькое.
Вот основные фишки Fractal Agents AI:
Оркестрация моделей. Система работает как дирижер для разных LLM: Gemini 3, Claude, Nano banana и другие. Для каждой подзадачи выбирается оптимальная модель(оу - вот это бы надо проверить). Не пытается одна нейронка тянуть всё — делегирует профи.
Архитектура "Генератор – Критик – Ревьювер": один агент генерирует ответ, второй его критикует, третий проверяет.
Фильтр галлюцинаций. Результат — меньше фантазий, больше фактов.
Прозрачность процесса. Видите в реальном времени: какие агенты работают, сколько времени тратят, сколько это стоит. Никакой магии — только честная работа.
И всё это обтянуто RL - система дообучается подбирать лучших ИИ-агентов от вашего фидбека. А это значит с каждым запуском она все эффективнее.
Давайте разберу четыре кейса, где эта банда реально рулит, как утверждают разработчики.
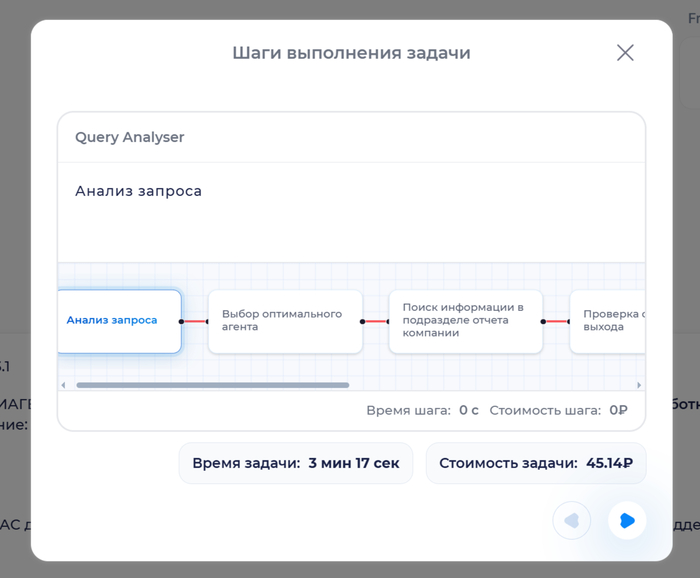
Каждый блок в цепочке выполнения задачи - это ИИ-агент, который вызвал инструмент (LLM или другой)
Проверяем интеллект сервиса
Кейс 1. Ищу клиентов
Представьте: маркетолог готовит холодную рассылку. Нужно ровно 100 компаний из определенной ниши, с контактами, отсортированных по отраслям. Вручную это день работы в Excel и LinkedIn.
Обычные ИИ-поисковики (Perplexity, тот же ChatGPT) — ленивые. Найдут 30 результатов и остановятся. "Вот несколько примеров" — и всё. Fractal Agents понимает запрос буквально. Сказали 100 — найдет 100. Система копает глубже: анализирует каждую компанию, сортирует по критериям, формирует готовый отчет. Один запрос — и у вас база для работы на неделю. Можно написать перейти на конкретный сайт.
Правда, работает медленнее обычных ботов. Зато результат не нужно перепроверять и дополнять вручную.
1/2
Фрактал нашел 100 лидов, Перплексити 10 и дальше не стал искать
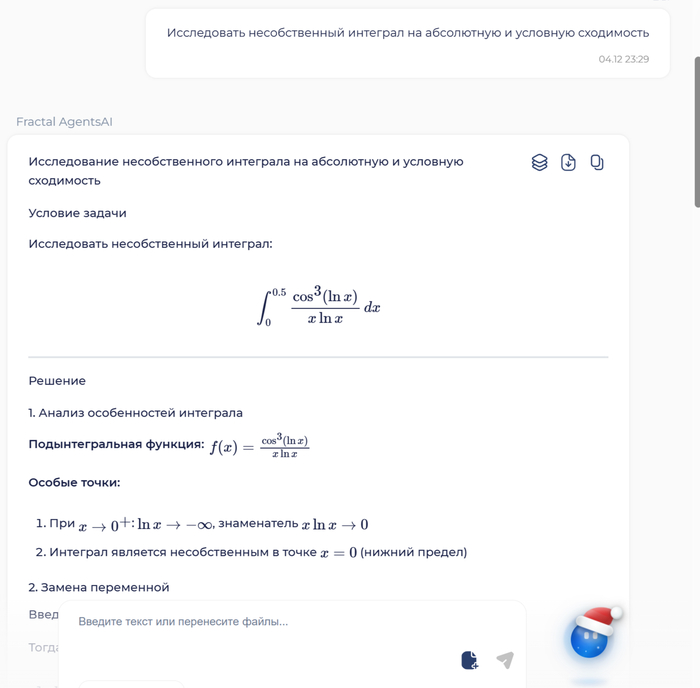
Кейс 2. Решаю сложную математику
Вот классика: "Оркестр из 30 музыкантов исполняет 6-ю симфонию Бетховена за 40 минут. За какое время оркестр из 60 музыкантов исполнит 9-ю симфонию?" ChatGPT может начать рассуждать про "удвоение скорости" и выдать бред. Потому что языковые модели не умеют считать — они угадывают ответы, как школьник без формул.
В Fractal Agents за расчеты отвечает отдельный нейросимвольный агент-математик. Он не генерирует ответ — он строит логику решения и использует калькулятор. Как если бы наняли математика, который показывает каждое действие. Работает с дробями, экспонентами, уравнениями, статистикой. Галлюцинации в цифрах исключены — агент либо решает правильно, либо говорит "не знаю".
Я затестил на сложном интеграле 🤯 Все, что вам нужно знать - Гигачат ошибся, а Фрактал решил верно, это довольно забавно, учитывая, что это наверное единственный случай на моей памяти, когда задачку решает не языковая модель а спец. агент.
1/3
Фрактал дал решение интеграла из высшей математики и еще и объяснил правильно
(Кстати, правильный ответ про оркестр: время не изменится, симфония длится столько, сколько длится. Но это вы и сами знали 😄)
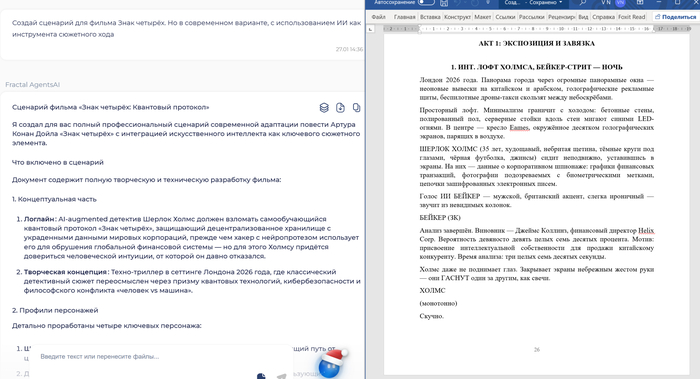
Кейс 3. Пишу сценарий фильма. ИИ-копирайтер и работа с документами
Обычные ИИ плохо работают с документами. В DeepSeek мне не удавалось грузануть много документов, к тому же по размеру он не читает большие файлы — просто пишет что понял половину файла и все. Это прям бесит. ИИ часто видят текст, но не понимают структуру.
Я люблю Конан Дойля и его Шерлока Холмса с детства) попросил написать мне сценарий для фильма "Создай сценарий для фильма Знак четырёх. Но в современном варианте, с использованием ИИ как инструмента сюжетного хода". Глянул текст — он сам догадался, что вообще-то надо сначала найти оригинальную книжку Знак четырех, потом найти статьи про ИИ, потом это скомбинировать, а потом еще и оформить в красивый Word файл.
Один запрос — и вместо 30 часов ручной работы, прописывания синопсиса, диалогов, актов и т.п. вы получаете структурированные данные на 30-80 страниц. Ого. Правда, этот запрос был для меня дороговат). За то порадовало, что Word файл сценария оказался полностью с красивым форматированием - круть. Perplexity выдал слабую поделку на 5 страниц почти без диалогов, Qwen вообще особо ничего не дал.
1/2
Фрактал выдал гигантский объем с красивым форматированием и похожий на реальный сценарий
Кому пригодится
Создателям контента — создание маркетинговых стратегий, контента, статей, картинок, видео.
Инженерам — обработка файлов, ответы по документам, финансовая и нормативная аналитика по таблицам.
Маркетинговым агентствам — целый комбайн для лидгена, создания материалов для клиентов.
Автоматизаторам — ИИ-ассистенты по вашим товарам.
Вывод
Самое мощное и что мне понравилось — комбинирование агентов. Например: просите найти обзоры CRM-систем (задача для поисковика), а затем написать о каждой статью в стиле авторов Хабра (задача для редактора). Агенты сами перейдут на сайты, соберут посты, изучат стиль и перепишут текст. И без жуткой настройки как в OpenClaw. В системе есть генерация видео с монтажем с агентами и даже создание музыки на Suno.
Вопрос только в том, что важнее: скорость или качество, при выборе разных LLM?
Неужели сбудется моя мечта не переключаться между разными LLM и искать промпты в Telegram(и у разного рода авторов курсов и инфоцыганов). Сейчас в системе 15 агентов, обещают скоро добавить еще и вообще сделать автоматом добавление агентов и улучшение промтов.
А вы бы доверили ИИ свои расчеты, поиск клиентов или рерайт статей? Или всё-таки лучше по старинке, вручную? Пишите в комментах, интересно ваше мнение.
Короче, ребята выкатили не просто игрушку, а мощный инструмент, который может автоматизировать кучу рутинной работы. Кажется, будущее, где у каждого будет свой цифровой помощник Джарвис, стало еще на один шаг ближе.
Видел много видео , в которых люди использовали ии для прохождения игр или выполнения определенных действий на основе машинного обучения на пк , пробовал с помощью ии сделать что-то подобное на питоне с помощью Termux и плагинов на телефоне и столкнулся с множеством проблем , одна из которых , что ии видет скриншотами, которые не создаются и сохраняются автоматически , пробовал много всего и ничего не получилось. Поэтому мой итоговый вопрос. Возможно ли сделать ии , которого можно обучить в играх на телефоне , чтобы он проходил ее/выполнял определенные действия , через что это можно сделать и насколько это будет сложно.Еесли на 1 вопрос ответ будет отрицательный , то второй вопрос. Ноутбук/пк в наличии. Телефон HUAWEI nova 9 SE. Заранее спасибо .