Возможен ли AGI уже сейчас?
Коротко и о главном
Примерные прогнозы экспертов:
Илон Маск прогнозирует, что AGI появится уже в 2026 году.
Деми Хассабис, CEO DeepMind и лауреат Нобелевской премии 2024 года, оценивает вероятность достижения AGI к концу десятилетия (2030) примерно в 50%. Хассабис признаёт быстрый прогресс в верифицируемых областях (кодирование, математика), но подчёркивает нерешённые ограничения в области научных открытий и творческого мышления.
Эрик Шмидт, бывший CEO Google, заявил в апреле 2025 года, что AGI может быть достигнут через 3–5 лет.
По данным платформы Metaculus (февраль 2026), агрегированный прогноз от примерно 2000 участников даёт 25% вероятность AGI к 2029 году и 50% — к 2033 году.
И да, разработка AGI уже идет (OpenAI, DeepMind и Anthropic PBC). Но что такое AGI? И чем AGI отличается от AI?
Для тех, кто не в теме:
AI (Artificial Intelligence) и AGI (Artificial General Intelligence) отличаются тем, что AI — это узкоспециализированная система, а AGI — гипотетический тип искусственного интеллекта, способный решать широкий круг задач на уровне человека (или даже выше).
Что мы имеем уже сегодня?
К примеру, всем известный ChatGPT от openAI (версия 5.3):
В основе лежат трансформеры и тензоры. Но это лишь инструмент для обработки последовательностей. Весь "интеллект" сводится к одному: модель показывает гигантское количество текста, и она учится статистике — какие слова чаще всего идут после других.
Цитата из исследования OpenAI: Они сами признают, что их модели обучаются «без меток „правда/ложь“». Модель видит "только положительные примеры плавного языка".
Вывод: ChatGPT не знает, что 2+2=4. Он знает, что в 60% случаев после "2+2=" люди пишут "4". Разница колоссальная.
Галлюцинации? Есть!
Факт: Исследователи OpenAI подтверждают, что "галлюцинации остаются фундаментальной проблемой для всех крупных языковых моделей" и "полностью устранить их невозможно".
Почему? Потому что модель не может сказать "я не знаю". Её поощряют угадывать. Если она ответит неправильно, но уверенно, — это лучше, чем ничего, с точки зрения математики обучения.
Ситуация тяжелая. Только представьте, какая вычислительная мощность нужна, чтобы поддерживать жизнь AGI. Трансформеры, тензоры, большие нейросети и веса - очень тяжелая штука. Хоть openAI и нацелена на данный момент на улучшение производительности, толку все равно мало. С такими подходами от обычного AI до AGI мы вряд-ли дойдем. Тогда в чем суть моей статьи?
Перед тем, как идти дальше, рекомендую прочитать мою теорию (ссылка на Порталусе - https://portalus.ru/modules/philosophy/rus_readme.php?subaction=showfull&id=1772296598&archive=&start_from=&ucat=&).
Возможно, самое интересное за сегодня
Если вы вчитались в мою теорию, то скорее всего понимаете, к чему я клоню.
На данный момент я взялся за разработку собственного AGI (наверное AGI =)) по моей теории. В чем отличие обычных алгоритмов ML от моих? Объясняю:
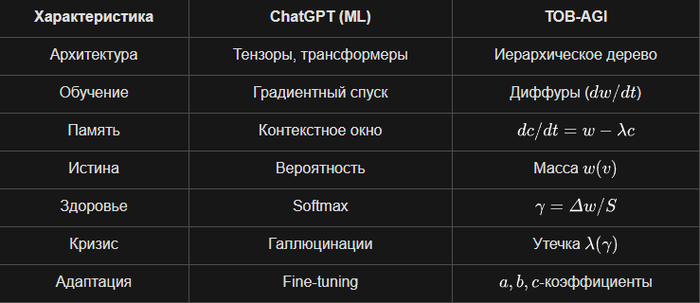
1. Архитектура: Дерево против Матрицы
У них: Тензоры, многомерные матрицы, линейная алгебра, трансформеры. Данные — это вектора в многомерном пространстве.
У меня: Иерархическое дерево с корнем, узлами, потомками. Мир — это структура, а не плоскость. Каждый узел — сущность со своей массой и памятью.
2. Обучение: Диффуры против Backpropagation
У них: Обратное распространение ошибки, градиентный спуск, миллионы итераций подгонки весов.
У меня: Система обыкновенных дифференциальных уравнений (ОДУ) — dw/dt = in - out - λw. Состояние эволюционирует во времени, а не "учится" на размеченных данных.
3. Память: Эволюционирующая переменная против Контекстного окна
У них: Внимание (attention) и контекст на токенах. Память ограничена размером окна (128k, 1M токенов), после диалога всё забывается.
У меня: dc/dt = w - λc c. Память c(t) — это динамическая переменная, которая накапливается и забывается со скоростью , как у живого существа.
4. Представление знаний: Масса против Вероятности
У них: Вероятность следующего токена. Модель не знает факты, она знает статистику: после "2+2=" в 60% случаев идет "4".
У меня: Масса w(v) в узле — это "количество сущности". Она сохраняется, перераспределяется, утекает. Это физическая метафора, а не статистическая.
5. Саморегуляция: Коэффициент упругости γ(v) против Softmax
У них: Функции активации (ReLU, softmax), которые просто преобразуют сигнал. Нет понятия "здоровья" системы.
У меня: γ(v) = Δw(v) / S(v) — отношение потерь узла к потерям потомков. Это мера "напряжения". Если близок к — система на грани коллапса и начинает иначе распределять ресурсы (меняются потоки Φ, растет утечка λ).
6. Потоки данных: Φ(p→c) против Attention
У них: Механизм внимания (attention) вычисляет веса между всеми парами токенов. Это и неинтерпретируемо.
У меня: Φ_{p→c}(t) = a_t(p) * w_t(p). Поток от родителя к потомку — это явная передача массы с коэффициентом случайности a_t. Прозрачно и физично.
7. Устойчивость: Спектральный анализ против Переобучения
У них: Переобучение, подгонка под шум. Чтобы бороться, добавляют dropout, регуляризацию — костыли.
У меня: ρ_loc(t) = max(|λ|) — спектральный радиус матрицы Якоби. Система сама знает, устойчива ли она (1/T ∫ρ dτ < 1). Это встроенный мониторинг стабильности.
8. Кризис и коллапс: γкрит и утечка λ против Галлюцинаций
У них: Галлюцинации — это "особенность, а не баг". Модель не знает, что она врет, и не может остановиться.
У меня: Когда превышает , система входит в режим усиленной утечки (λ = λ0 + λ1 * γ). Масса "утекает", система сбрасывает напряжение. Это предотвращает катастрофический сбой.
9. Адаптивность: a, b, c коэффициенты против Fine-tuning
У них: Донастройка (fine-tuning) — это переобучение всех весов под новую задачу. Дорого и долго.
У меня: a_t (случайность), b_t (отбор), c_t (память) — адаптивные коэффициенты, которые меняются в реальном времени в зависимости от состояния узла (шум ε_t, γ, память). Система подстраивается сама, без перезапуска.
10. Философия: Физика против Статистики
У них: "Все, что мы знаем о мире — это корреляции в данных". Бритва Оккама: мир плоский.
У меня: Мир иерархичен и динамичен. Знания — это структура, а не вектор. Память — это процесс, а не буфер. Интеллект — это способность сохранять устойчивость вблизи критической точки.
Вывод
ChatGPT — это не интеллект. Это стохастический попугай с 200 миллиардами кнопок. Он не мыслит — он подбирает статистически вероятное продолжение фразы. Он не помнит — у него просто большое окно контекста. Он не понимает, когда врёт — у него просто нет критерия истины.
ТОВ — это попытка построить систему, которая действительно думает, а не имитирует мышление. Где знание имеет вес, память имеет динамику, а устойчивость имеет математическое выражение.
Пока одни гонятся за количеством параметров, другие строят архитектуру мира. Догадайтесь, кто из них ближе к AGI.
ChatGPT говорит то, что вы хотите услышать. AGI скажет то, что должно быть сказано. Даже если вы не готовы это принять.
Выражаю свою благодарность тем, кто дочитал до конца, надеюсь данный материал вам зашел =)
Готов выслушать вашу критику и ваши идеи, буду рад почитать!
P.S. Уже есть рабочий прототип