$10 миллиардов на веру в "невозможное": разбор проекта Ineffable Intelligence Дэвида Сильвера

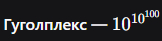
В январе 2026 года индустрию ИИ всколыхнула новость: Дэвид Сильвер (David Silver), создатель AlphaGo и главный научный сотрудник DeepMind, ушел, чтобы основать собственный стартап. А в феврале пришла информация, которая заставила инвесторов по всему миру замереть: Ineffable Intelligence привлекает $10 МИЛЛИАРДОВ в посевном раунде .
Это не просто очередная AI-компания. Это, пожалуй, самая смелая и рискованная ставка в истории технологий. Давайте разберемся, что стоит за этим проектом, почему Дэвид Сильвер решил пойти против мейнстрима и главное — сможет ли его ИИ самостоятельно открыть законы физики, не зная трудов Ньютона.
---
👤 Кто такой Дэвид Сильвер и почему его уход — событие эпохальное?
Дэвид Сильвер — это не просто талантливый инженер. Это человек, который фактически создал современное обучение с подкреплением (Reinforcement Learning, RL).
· Наследие: Он был в DeepMind с момента основания (2010 год) и является ближайшим соратником Демиса Хассабиса. Именно Сильвер руководил созданием легендарного AlphaGo, который в 2016 году обыграл Ли Седоля, сделав тот самый знаменитый "ход 37", который все эксперты сочли ошибкой, но который привел к победе .
· Академический вес: Он ученик Ричарда Саттона (Richard Sutton), одного из отцов-основателей RL, получившего в 2025 году Премию Тьюринга . Сам Сильвер имеет индекс Хирша 104 и более 28 000 цитирований — это уровень нобелевского лауреата в мире компьютерных наук .
· Масштаб личности: Его уход из DeepMind сравнивают с уходем Ильи Суцкевера из OpenAI. Это потеря для гиганта и приобретение для всего человечества (если его план сработает) .
🏢 Что такое Ineffable Intelligence и почему инвесторы поверили?
Ineffable Intelligence — это лондонский стартап, основанный Сильвером в конце 2025 года. Название отсылает к тому самому "невыразимому" (ineffable) ходу AlphaGo, который был гениален, но непонятен человеку .
Почему инвесторы (Sequoia, Nvidia, Google) выстроились в очередь и готовы отдать $10 млрд на стадии идеи?
Ответ прост: они ставят не на продукт, а на эпоху. Они верят, что Сильвер знает, как совершить следующий качественный скачок. В мире, где все копируют ChatGPT, ставка на оригинальное фундаментальное исследование стоит дорого .
🤔 Почему нейросети (LLM) — тупик для AGI?
Главный тезис Сильвера, который он подробно изложил в своем манифесте "Welcome to the Era of Experience" (2025), звучит так: современные большие языковые модели никогда не станут AGI .
· Проблема "человеческого потолка": LLM обучаются на данных, созданных людьми (книги, интернет, диалоги). Даже финальная доводка моделей через RLHF (обучение с подкреплением на основе человеческой обратной связи) привязывает их к оценкам людей. По определению, такая система не может превзойти своего учителя. Она заперта в клетке человеческих знаний .
· Отсутствие понимания мира: LLM блестяще предсказывают следующее слово, но у них нет модели реальности. Они не понимают причинно-следственные связи. Исследования 2025 года подтверждают, что простое масштабирование моделей (увеличение параметров) упирается в "стену" и не ведет к появлению настоящего интеллекта .
· Свидетельство Янна Лекуна: Еще один "крестный отец" ИИ, Ян Лекун, также неоднократно заявлял, что авторегрессионные модели (типа GPT) не способны к истинному пониманию мира, и их архитектура фундаментально отличается от человеческого мышления .
🔬 Почему обучение с подкреплением (RL) — это революция?
Сильвер предлагает отказаться от подражания человеку и вернуться к обучению через опыт.
· Как учат RL: Агента помещают в среду (сначала в симуляцию). Он совершает действия, получает награду или наказание и методом проб и ошибок учится достигать максимального результата. Это не "заучивание", а исследование .
· Наследие AlphaZero и MuZero:
· AlphaZero научился играть в го и шахматы на сверхчеловеческом уровне, не видя ни одной партии людей. Ему дали только правила, и он сам открыл стратегии, которые люди не знали тысячелетиями .
· MuZero пошел еще дальше: он научился играть, даже не зная правил. Он строил внутреннюю модель мира в процессе игры .
· DiscoRL — ИИ учит ИИ: В конце 2025 года DeepMind показала систему DiscoRL, где "мета-нейросеть" сама изобрела новый алгоритм обучения, который превзошел человеческие разработки. Это доказательство того, что RL-системы могут саморазвиваться .
Именно эту магию — способность к самостоятельному открытию — Сильвер и хочет перенести из игр в реальный мир.
🎯 Конкретные цели и сроки проекта
В отличие от типичных стартапов, у Ineffable Intelligence нет поквартального плана продаж.
Конечная цель: Создать "вечно обучающийся суперинтеллект", который сможет самостоятельно открывать основы всех знаний, решать научные проблемы и делать открытия, недоступные человечеству .
Что для этого нужно (ближайшие шаги):
1. Создание "песочницы": На первые миллиарды долларов компания построит суперкомпьютер (вероятно, на чипах Nvidia) и создаст чрезвычайно сложную симуляцию (цифровой двойник) реального мира. Агент должен где-то "жить" и учиться .
2. Обучение агента: Запуск процесса самообучения. Агент будет миллиарды раз взаимодействовать с симуляцией, получая награду не за "очки", а за "интересные" открытия и эффективные решения.
Сроки:
· Официально не объявлены.
· Эксперты полагают, что на создание инфраструктуры уйдет 1-2 года (2026-2027).
· Первые впечатляющие результаты (не AGI, а прорывы в узких задачах) могут появиться через 3-5 лет.
· Сам AGI — горизонт планирования 10+ лет, если вообще возможен .
🧠 Сможет ли такой ИИ познавать Вселенную и открывать новые законы?
Это самый глубокий вопрос, и ответ на него — ДА, именно это и есть главная цель проекта.
Сильвер верит, что его подход позволит ИИ совершать открытия, которые не под силу человеку.
Пример с Ньютоном: Сможет ли ИИ вывести законы Ньютона, не зная их?
Давайте представим, как это могло бы работать в парадигме Ineffable Intelligence.
1. Среда: Мы помещаем RL-агента в симуляцию с базовыми законами физики (гравитация, инерция, столкновения). Агент может управлять объектами.
2. Награда: Мы не даем агенту формул. Мы даем ему цель, например: "Научись предсказывать траекторию движения этого яблока максимально точно и с минимальными затратами энергии на размышления".
3. Процесс:
· Сначала агент будет просто запоминать траектории (переобучаться).
· Потом, методом проб и ошибок, его внутренняя нейросеть (модель мира, как в MuZero) начнет искать закономерности.
· В какой-то момент, чтобы эффективно решать задачу предсказания для любого броска, агент вынужден будет "открыть" математическую зависимость, очень похожую на F = ma или закон всемирного тяготения.
· Он не запишет ее в виде формулы на доске. Но его внутренние веса нейросети будут кодировать эту зависимость. Он будет использовать ее для предсказаний, даже если физики не существует.
То есть, в теории — ДА, такой ИИ способен "переоткрыть" законы Ньютона, просто потому что они являются наиболее эффективным способом описания реальности в его симуляции.
💡 Критические вопросы и ограничения
Однако не все так однозначно. Физики и философы науки указывают на важные нюансы:
1. Универсальность против конкретики: ИИ может найти закономерность в данных (корреляцию), но сможет ли он понять, что это универсальный закон, применимый везде — от яблока до Луны? Российский физик Владислав Николаев отмечает, что нейросети пока отлично справляются с обработкой данных, но именно выведение универсальных принципов остается задачей человека .
2. Понимание против вычисления: Найдет ли ИИ формулу или поймет ее философский смысл? Для AGI, возможно, достаточно и первого. Ему не нужно "чувствовать" гравитацию, чтобы ею пользоваться.
3. Сложность симуляции: Сможем ли мы создать симуляцию, достаточно сложную, чтобы в ней "проявились" все фундаментальные законы физики? Это требует колоссальных ресурсов.
📌 Резюме
Ineffable Intelligence — это не просто компания. Это эксперимент по созданию искусственного разума, который учится как ребенок, а не зубрит как отличник.
Дэвид Сильвер ставит на то, что настоящий интеллект рождается из взаимодействия с миром, из удивления и исследования. Если он прав, нас ждет эпоха открытий, где ИИ будет нашим Колумбом в неизведанных вселенных знаний. Если нет — мы просто увидим, как сгорают 10 миллиардов долларов в самой красивой научной гипотезе десятилетия.