Кватернионы в машинном обучении: новый вектор развития
Автор: Денис Аветисян
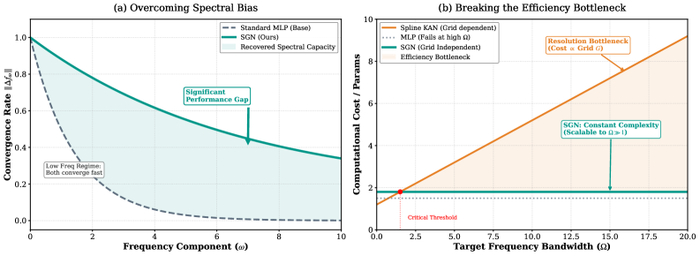
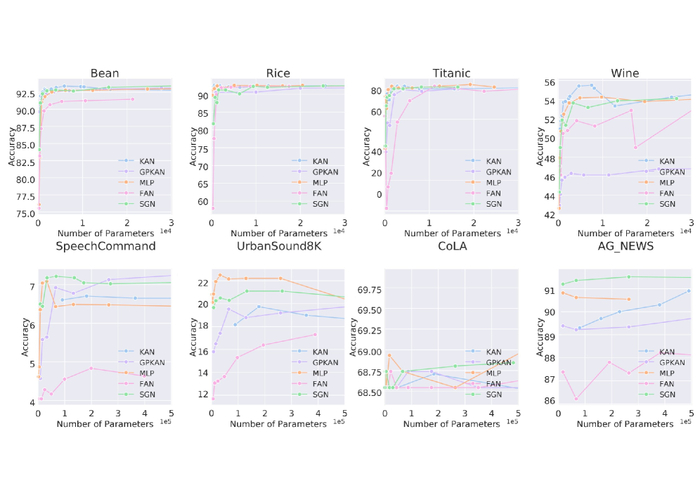
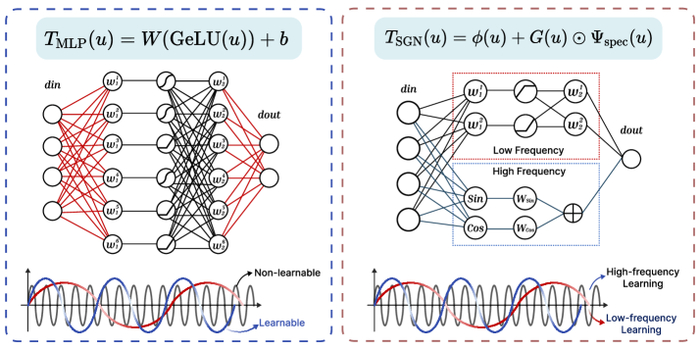
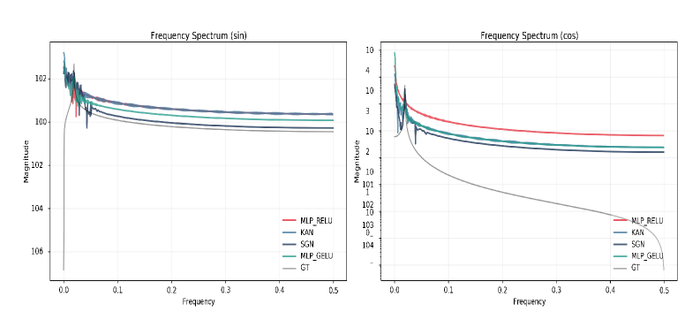
Исследование закладывает теоретические основы для создания алгоритмов машинного обучения, оперирующих с гиперкомплексными числами - кватернионами.
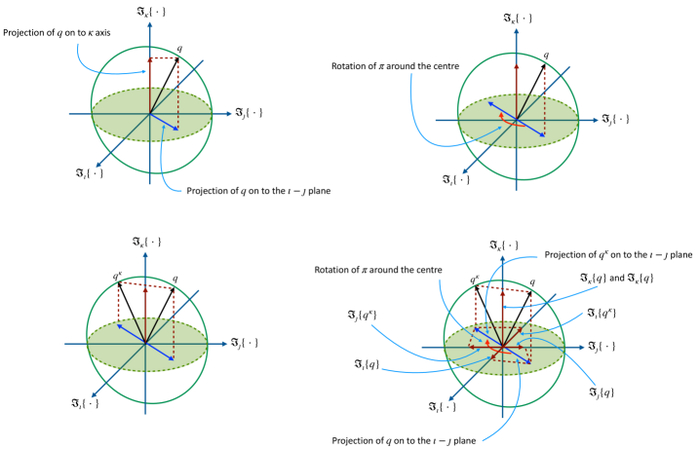
Кватернион q и его инволюция qκ демонстрируют взаимосвязь между проекциями кватерниона на плоскость, образованную мнимыми единицами imath и jmath, и проекцией на ось, определяемую κ, при этом вращение проекции на плоскости вокруг центра на π позволяет восстановить инволюцию из этих проекций, раскрывая геометрическую структуру кватернионных преобразований.
В статье представлены фундаментальные принципы широколинейного моделирования и адаптивного обучения для обработки гиперкомплексных сигналов на основе кватернионного исчисления.
Несмотря на успехи комплексных чисел в различных областях науки и техники, расширение этих методов на другие гиперкомплексные системы, такие как кватернионы, долгое время оставалось сложной задачей. В работе 'Hypercomplex Widely Linear Processing: Fundamentals for Quaternion Machine Learning' предлагается фундаментальный подход к машинному обучению на основе кватернионов, включающий расширенную статистику, широколинейные модели и кватерниональное исчисление. Ключевым результатом является создание теоретической базы для обработки гиперкомплексных сигналов и адаптивного обучения в многомерном пространстве. Открывает ли это новые перспективы для разработки эффективных алгоритмов машинного обучения в задачах, требующих моделирования трехмерных вращений и пространственной ориентации?
Кватернионы: Новый горизонт вращений
Во многих областях, от компьютерной графики до робототехники и навигации, точное и эффективное представление вращений играет ключевую роль. Хотя комплексные числа прекрасно справляются с двумерными вращениями, их возможности ограничены в трехмерном пространстве. Кватернионы предлагают мощную альтернативу, обеспечивая компактный и лишенный особенностей способ описания ориентации объектов в трех измерениях. В отличие от других методов, кватернионы позволяют избежать проблем, связанных с "запиранием оси" и другими нежелательными эффектами, что делает их незаменимым инструментом для адаптивных алгоритмов, требующих прецизионного управления вращениями. Именно эта особенность открывает новые перспективы для развития машинного обучения на основе кватернионов, позволяя создавать более устойчивые и эффективные системы управления и анализа движений.
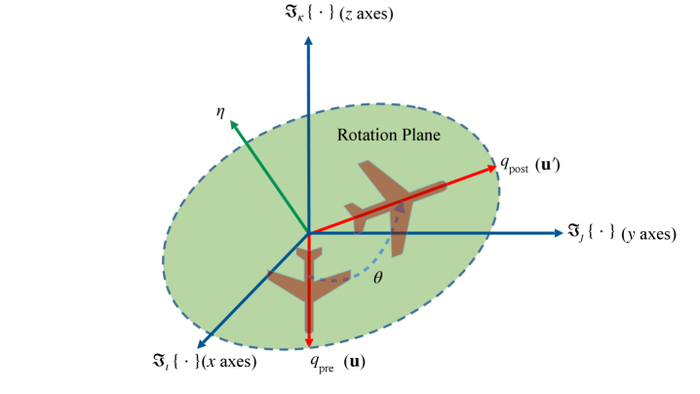
Схема иллюстрирует вращение объекта на угол θ вокруг оси η, определяющее переход от начальной ориентации qₚᵣₑ к конечной ориентации qₚₒₛₜ.
Вращения и их Математический Анализ: Производные Кватернионов
Расширение стандартного математического анализа на функции, значениями которых являются кватернионы, требует особого внимания к правилам умножения, поскольку порядок множителей имеет значение. Для этого используется понятие производной кватерниона, которое строится на основе условий, обеспечивающих математическую согласованность, подобных известному условию Коши-Римана-Фуэнтеса. В результате, привычные правила дифференцирования, такие как правило произведения и правило цепочки, получают своё развитие и применение для анализа и манипулирования динамикой вращений, описываемых кватернионами. Эти правила, адаптированные для кватернионов, становятся ключевыми инструментами в изучении того, как вращения изменяются во времени и как они взаимодействуют друг с другом.
Адаптивные Алгоритмы и Сложная Динамика Систем
Современные системы, способные к самообучению и адаптации в реальном времени, требуют использования адаптивных алгоритмов, которые постоянно корректируют свои параметры. Для эффективного моделирования сложных динамических процессов, в таких алгоритмах применяются нелинейные функции, основанные на кватернионах - математических объектах, расширяющих понятие комплексных чисел. Использование производных кватернионов позволяет алгоритмам быстро и эффективно находить оптимальные решения в многомерных пространствах параметров, обходя ограничения традиционных линейных моделей. Введение широколинейной модели дополнительно повышает возможности адаптации, позволяя системе реагировать на изменения и находить наиболее подходящие настройки даже в условиях высокой неопределенности и сложности.
Кватернионный адаптивный алгоритм: QLMS
Алгоритм QLMS представляет собой усовершенствованную версию широко известного метода наименьших квадратов, расширенную для работы с кватернионами - математическими объектами, эффективно описывающими вращения. В отличие от традиционных подходов, QLMS использует производные кватернионов и гиперболический тангенс для обеспечения быстрой и надежной адаптации системы. Этот метод позволяет динамически настраивать параметры системы, что особенно важно для точного управления вращающимися объектами, например, в системах оценки и контроля ориентации. QLMS служит практическим примером реализации предложенного подхода и демонстрирует его возможности в задачах, требующих высокой точности и оперативности управления вращением.
Работа представляет собой изящное исследование возможностей гиперкомплексной обработки сигналов, закладывая основу для машинного обучения на основе кватернионов. Авторы демонстрируют глубокое понимание принципов широколинейного моделирования и адаптивного обучения в контексте гиперкомплексной алгебры. В этом стремлении к элегантности и точности можно увидеть отголоски идей Томаса Куна: “Научные знания не растут постепенно, а претерпевают революционные изменения.” Подобно тому, как Кун описывал смену парадигм в науке, данное исследование предлагает новый взгляд на обработку данных, потенциально приводящий к фундаментальным изменениям в области машинного обучения. Вместо постепенного улучшения существующих методов, предлагается качественно новый подход, основанный на возможностях, предоставляемых кватернионным исчислением и широколинейным моделированием.
Что дальше?
Представленная работа, стремясь к элегантности в обработке гиперкомплексных сигналов, неизбежно обнажает области, требующие дальнейшего осмысления. Основываясь на кватернионной алгебре, исследование, хотя и закладывает прочный фундамент для машинного обучения, оставляет открытым вопрос о практической применимости и вычислительной эффективности предложенных моделей. Как часто бывает, идеальная гармония теории сталкивается с суровой реальностью ограниченных ресурсов и шума в данных.
Особого внимания заслуживает проблема адаптации алгоритмов к нелинейным задачам. Линейность, как известно, - лишь приближение, и истинная сила интеллекта проявляется в способности к обобщению за пределами известных закономерностей. Поиск кватернионных аналогов нелинейных функций, сохраняющих при этом вычислительную эффективность, представляется нетривиальной задачей. Подобно хорошей архитектуре, которая незаметна, пока не рухнет, истинное достоинство этих моделей проявится в их устойчивости к искажениям и способности к самообучению.
В конечном счете, направление развития этой области, вероятно, будет определяться не столько теоретическими изысканиями, сколько потребностью в решении конкретных задач. Разработка специализированных аппаратных средств, оптимизированных для кватернионных вычислений, могла бы стать катализатором для более широкого применения этих моделей. Последовательность в развитии этих подходов - это форма эмпатии к будущим пользователям, которые, возможно, столкнутся с проблемами, о которых авторы еще не подозревают.
Полный обзор с формулами: denisavetisyan.com/kvaterniony-v-mashinnom-obuchenii-novyj-vzglyad-na-obrabotku-dannyh
Оригинал статьи: https://arxiv.org/pdf/2603.11835.pdf
Связаться с автором: linkedin.com/in/avetisyan