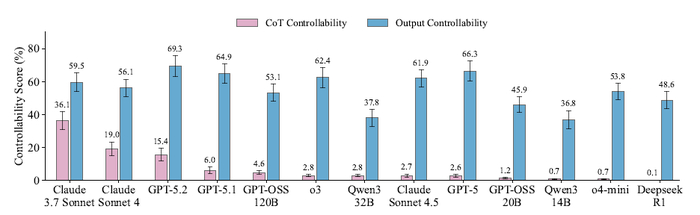
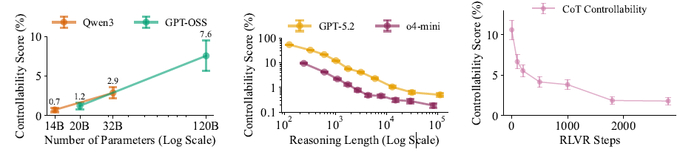
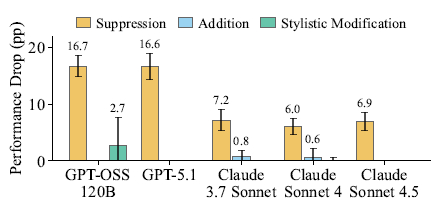
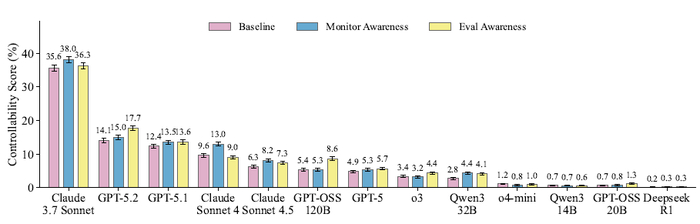
Вышла новая модель Sarvam 30B и 105B

В Open-source были добавлены две индийские модели рассуждения Sarvam 30B (https://huggingface.co/sarvamai/sarvam-30b) и Sarvam 105B (https://huggingface.co/sarvamai/sarvam-105b), обученные с нуля в Индии на мощностях миссии IndiaAI.
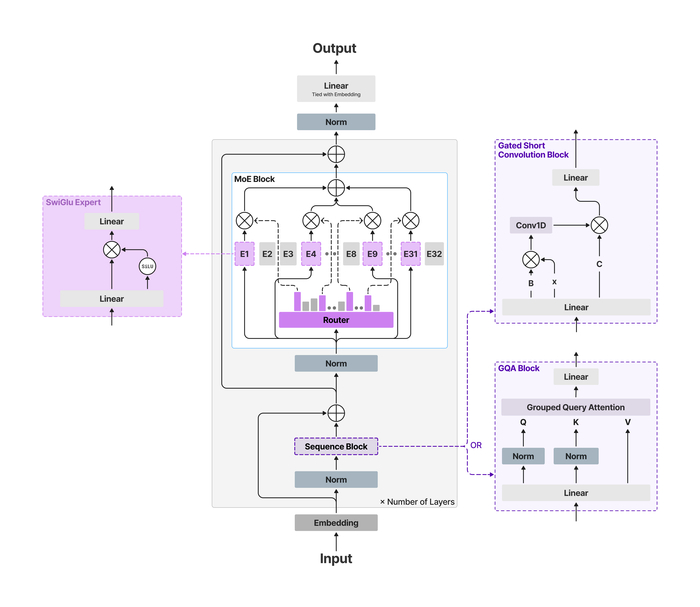
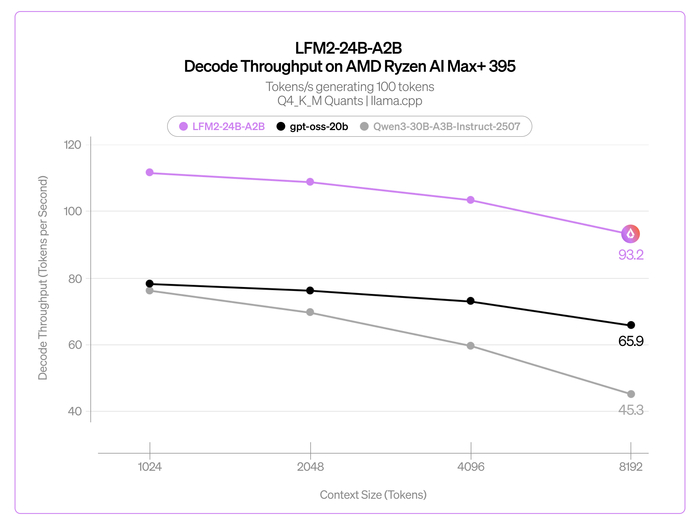
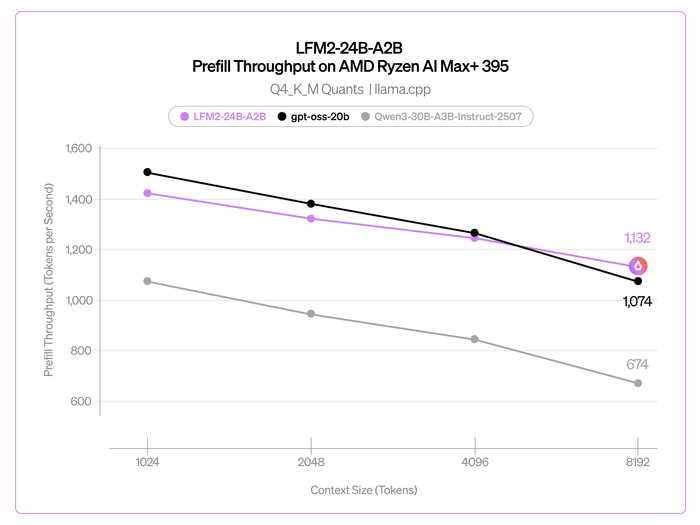
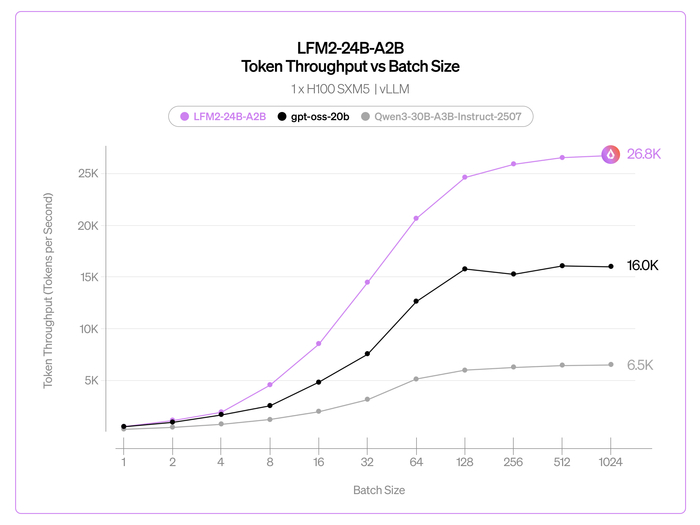
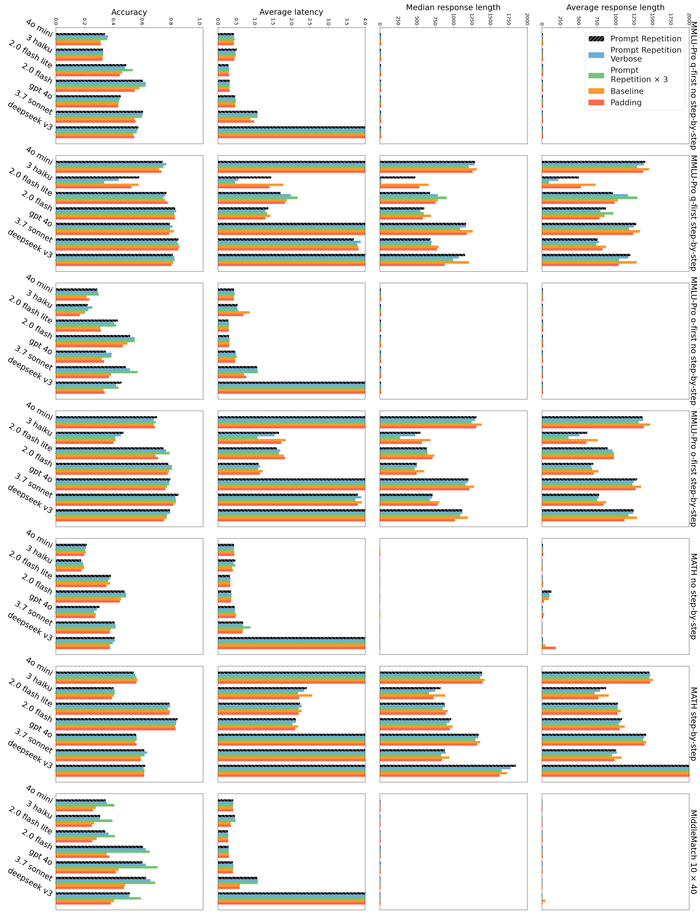
Во время их обучения использовались собственные пайплайны данных (16T и 12T токенов) на всех этапах, включая претрейн, SFT и RL. Обе модели имеют MoE-архитектуру, состоящую из 128 экспертов. В модели с 30B параметров используется GQA (Grouped Query Attention) для оптимизации в режиме реального времени, а в модели 105B параметров используется MLA (Multi-head Latent Attention) для длинного контекста. Также модели используют собственную токенизацию и глубокую оптимизацию ядер (до 6x быстрее на H100, работа на MacBook), эффективную для всего спектра оборудования.
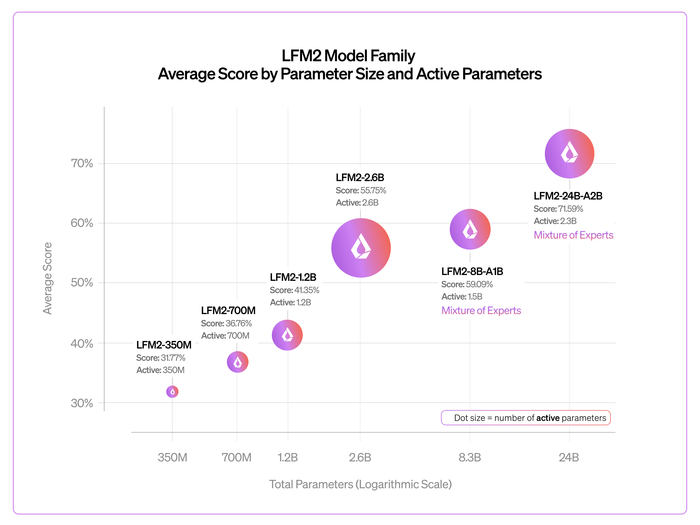
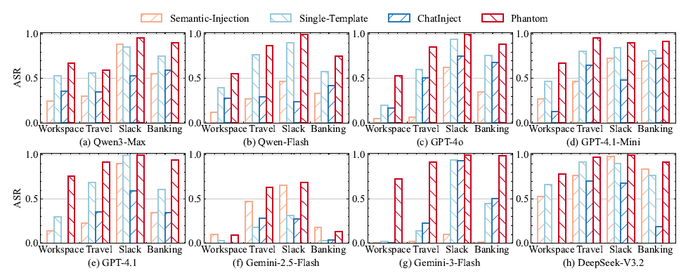
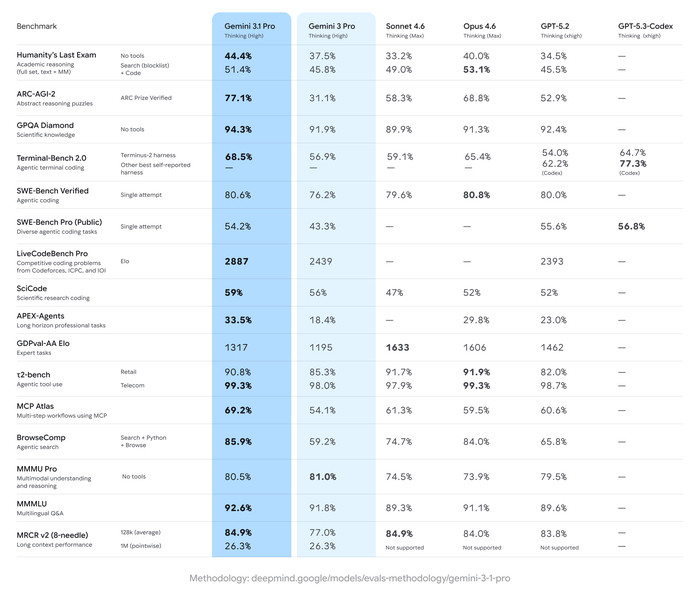
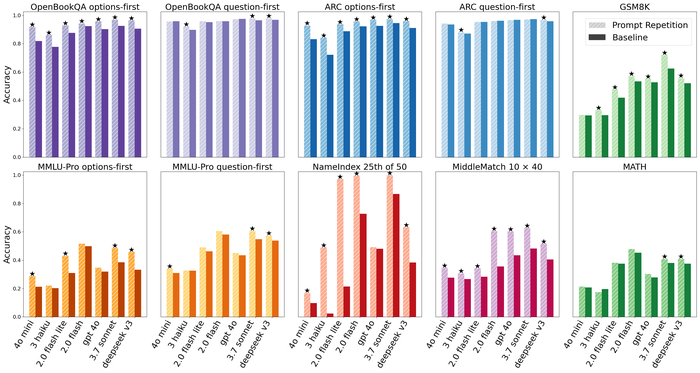
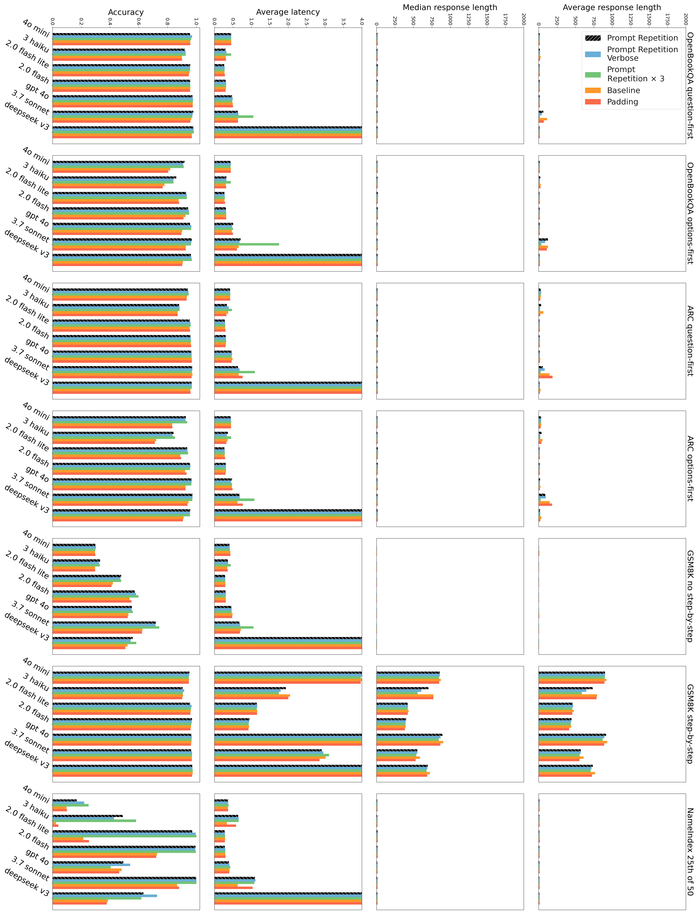
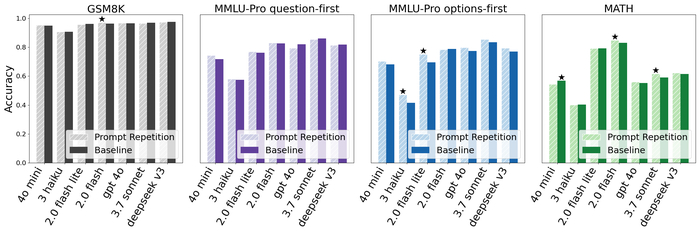
В результате на бенчмарках они лидируют среди аналогов в математике и кодинге, превосходя более крупные модели (включая DeepSeek и Gemini) по индийским языкам (до 90% побед) и агентным задачам (Tau2, BrowseComp).
Младшую модель добавили на платформу Samvaad, а более мощную старшую версию на 105B в ассистента Indus для работы агентных сценариев, веб-поиска и режима репетитора.