В потоке визуального контента, которым заполнены соцсети, маркетплейсы и рабочие чаты, ИИ с распознаванием фото стал тихим «фильтром», без которого система просто захлебнулась бы в хаосе. Он умеет видеть не только текст и объекты на картинке, но и контекст: тип товара, сцену, эмоции. Для бизнеса это означает меньше ручной работы, быстрее принятые решения и более точную аналитику по визуальным данным.
Я собрал 8 реально рабочих нейросетей для распознавания изображений: от облачных API до готовых инструментов для разработчиков и маркетологов.
ТОП-8 ИИ с распознаванием фото в 2026 году
MashaGPT — русскоязычный чат-бот на базе продвинутых моделей, который точно распознает текст, объекты и лица на фотографиях.
ChatGPT — ИИ от OpenAI, извлекающий текст, описывающий сцены и отвечающий на вопросы по загруженным изображениям.
Study AI — платформа с ИИ-ботами, где можно загружать скрины, фото заданий и документов, а нейросети распознают изображение, решают задачи и помогают с учебой и работой.
Gemini — мультимодальный ИИ от Google, который распознает изображения, ищет информацию по фото и отличает сгенерированные ИИ картинки от реальных.
SmartBuddy — сервис для OCR-распознавания текста с изображений, документов и сканов.
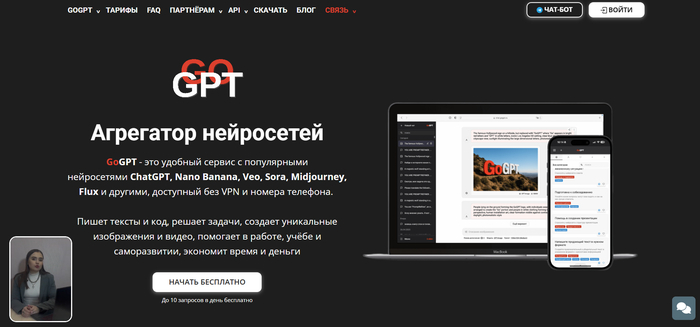
GoGPT — агрегатор нейросетей, которые поддерживают фотоанализ: извлекают текст, описывают содержимое и генерируют идеи на основе загруженных картинок.
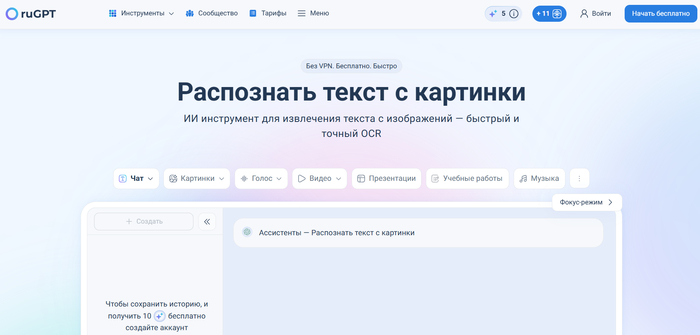
ruGPT — инструмент для распознавания текста с русских изображений, мемов и документов с высокой точностью кириллицы.
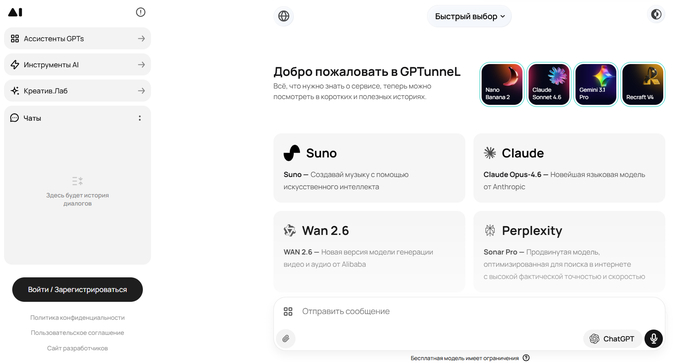
GPTunneL — нейро-офис объединяет сотню+ моделей и позволяет в одном интерфейсе распознавать, анализировать и генерировать изображения для рабочих и креативных задач.
Российский онлайн‑сервис, который дает доступ к моделям GPT (включая GPT‑4o‑mini и более продвинутые варианты) без зарубежных карт. В разделе чата пользователи могут просто начать диалог с ИИ, задавать вопросы, решать задачи, а также загружать файлы и изображения для анализа. Сервис позиционируется как «единое окно» к ИИ‑ассистенту для текста, фото, документов и креатива.
Стоимость: от 990 ₽/мес
Бесплатный доступ: есть бесплатный доступ к облегченной модели GPT‑4o‑mini
Функции: распознавание объектов, OCR-текст, описание сцен, анализ эмоций, распознавание графиков, анализ документов, идентификация растений/животных, мультимодальный диалог с уточнениями по фото, решение задач по изображениям перечислить через запятую именно про распознавание изображений
Плюсы:
Поддержка русского языка «из коробки» и адаптация под российскую аудиторию.
Есть бесплатный порог входа для тестирования.
Умеет работать не только с текстом, но и с изображениями и файлами.
Универсальный ИИ для распознавания изображений и работы с текстом. Пользователь может загрузить фото, скриншот или документ, а модель проанализирует содержимое, опишет картинку, найдет ошибки, прочитает текст и ответит на вопросы по изображению. Текущие версии (GPT‑4o и GPT‑5.2 в веб‑интерфейсе) поддерживают мультимодальный режим: текст + картинка в одном диалоге.
Стоимость: от $20/мес
Бесплатный доступ: ограничен 10 сообщениями каждые 5 часов
Функции: распознавание текста (OCR), описание сцен и объектов, анализ эмоций/лиц, извлечение данных из графиков/документов, ответы на вопросы по фото, генерация идей/редактирование изображений, интеграция с Sora для видео из фото
Плюсы:
Сильная мультимодальная модель: хорошо понимает как объекты на фото, так и контекст (подписи, интерфейсы, диаграммы).
Удобный и простой интерфейс: достаточно перетащить картинку в чат и задать вопрос.
Работает в браузере и мобильных приложениях, без сложной настройки.
Минусы:
Строгие лимиты на тарифах Free/Go, очереди в пике на Plus.
Платформа с набором ИИ‑ботов, которая закрывает задачи от учебы до контента. Сервис распознает задания по снимкам (рукописный и печатный текст), помогает решать задачи по картинке и работает с документами и тестами по скриншотам. Отдельные боты отвечают за генерацию и обработку изображений: от улучшения качества до оживления фото в короткие видео. Все нейросети собраны в одном интерфейсе, а умный поиск подбирает нужный бот под конкретную задачу.
Стоимость: от 199 ₽/нед
Бесплатный доступ: 50 приветственных токенов после регистрации для 1–3 запросов
Функции: распознавание текста и формул с фото, решение задач по изображениям, анализ скриншотов/рукописных заметок, извлечение данных из графиков/диаграмм, описание учебных материалов
Плюсы:
Один аккаунт дает доступ сразу к множеству ботов: и для учебы, и для работы с изображениями.
Умеет распознавать сложные задания по фото (включая рукописный текст), что удобно для школьных и вузовских задач.
Интерфейс и поддержка заточены под русскоязычную аудиторию.
Минусы:
Лимиты токенов быстро исчерпываются на пробном доступе.
Мультимодальная нейросеть Google, которая в 2026 году лидирует в анализе изображений благодаря моделям Gemini 2.5 Flash и 3 Pro с функцией Agentic Vision. Нейросеть с функцией распознавания фото позволяет загружать изображение для детального распознавания объектов, текста и сцен, а также проверки на AI-генерацию через SynthID. Сервис интегрируется с поиском Google, пдходит для поиска информации по фото и творческих задач.
Стоимость: $20/мес
Бесплатный доступ: неограниченный анализ изображений на Gemini 2.0 Flash
Функции: распознавание объектов и сцен, OCR-текст, анализ эмоций/лиц, проверка AI-генерации (SynthID), выделение элементов по запросу, Agentic Vision для детального зума/поворота фото, извлечение данных из графиков/документов
Плюсы:
Бесплатный мощный Vision без лимитов.
Интеграция с Google Search и высокой точностью SynthID.
Быстрый анализ сложных изображений.
Минусы:
Полноценный доступ к самым мощным моделям и расширенным лимитам требует платной подписки Google One AI / Gemini Advanced.
Российская платформа с 100+ нейросетями, включая Claude, Gemini и GPT для анализа изображений. Она фокусируется на OCR-распознавании текста с фото, сканов и документов, поддерживая русский язык. Сервис подходит для бизнеса, учебы и креатива: извлекает данные из таблиц, схем и графиков. Дополнительно генерирует диаграммы, переводит и анализирует файлы в одном интерфейсе.
Стоимость: привязана к количеству запросов и используемым моделям
Бесплатный доступ: 3 бесплатных запроса без регистрации
Функции: OCR-текст с фото/сканов, распознавание объектов/эмоций, анализ диаграмм/графиков, подсчет предметов, поиск дефектов/различий, извлечение данных из таблиц/документов
Плюсы:
Очень простой вход: можно протестировать сервис без регистрации и с бонусом после создания аккаунта.
Поддерживается работа с множеством форматов файлов (PDF, изображения, офисные документы), что удобно для документооборота.
Нейросеть для OCR встроена в более широкую экосистему: распознанный текст сразу можно перевести, проанализировать или переписать.
Агрегатор нейросетей, предоставляющий доступ к ChatGPT, Claude, Gemini и другим моделям, которые делают анализ изображений: вы загружаете фото, а ИИ делает поиск по фото, распознает текст или дает описание за секунды. Она подходит для повседневных задач, от генерации контента до анализа файлов и ссылок, с удобным чатом и готовыми промптами.
Стоимость: от 699 ₽/мес
Бесплатный доступ: 10–20 запросов в день на базовых моделях
Функции: распознавание объектов и текста на фото, описание сцен, анализ изображений для идей/редактирования, извлечение данных из графиков, поддержка FaceSwap и стилизации
Плюсы:
Доступ к нескольким сильным vision‑моделям и генераторам картинок в одном сервисе.
Гибкая система GoCoin: видно примерную стоимость каждого запроса, неиспользованный баланс переносится при продлении тарифа.
Можно в одном окне и распознавать изображения, и сразу генерировать/дорабатывать новые.
Минусы:
Лимиты на бесплатном быстро исчерпываются при частом использовании.
Платформа на русском языке, через которую каждый месяц проходит свыше 200 000 изображений. Сервис использует передовые алгоритмы ИИ для точного распознавания содержимого фотографий: сервис извлекает текст со сканов и снимков, анализирует визуальный контент и мгновенно преобразует информацию с картинок в цифровой формат — от рукописных заметок до сложных документов и инфографик. Простой и понятный интерфейс разработан с учётом потребностей аудитории из России и стран СНГ.
Стоимость: от 165 ₽/мес
Бесплатный доступ: бесплатный тариф с 10 стартовыми запросами
Функции: OCR-текст с фото/сканов, распознавание объектов/сцен, анализ задач/формул, извлечение данных из документов/графиков, ответы на вопросы по изображениям
Агрегатор более 100 нейросетей (ChatGPT, Claude, Midjourney, Gemini), предоставляющий туннельный доступ для создания контента. Платформа поддерживает Vision-функции для поиска по фото с помощью ИИ: от OCR и описания сцен до генерации/редактирования фото и видео. Подходит для бизнеса и креатива с удобным интерфейсом, загрузкой файлов (PDF, изображения) и корпоративными аккаунтами.
Стоимость: оплата по факту за количество генераций
Бесплатный доступ: есть бесплатный доступ к ChatGPT
Функции: OCR-текст/объекты с фото, описание сцен/эмоций, анализ документов/графиков, редактирование изображений, FaceSwap, стилизация/генерация из фото
Плюсы:
100+ ИИ‑моделей в одном месте: можно комбинировать распознавание, генерацию и видео без переключения сервисов.
Бонусы/промокоды, низкие цены для РФ.
Поддерживает локальные способы оплаты: СБП, карты, SberPay.
1. Чем ИИ с распознаванием фото отличается от обычного «поиска по картинке» в браузере?
«Поиск по картинке» обычно ищет похожие изображения в интернете и страницы, где они встречаются. ИИ с распознаванием фото сначала «понимает» само изображение: что на нем находится, какой текст, какой контекст сцены, а уже потом может по запросу описать картинку, выделить нужные элементы, решить задачу, переписать текст, найти ошибки в верстке и т.д. Проще говоря, браузер ищет картинку в сети, а нейросеть анализирует ее содержимое и работает с ним как с данными.
2. Можно ли загружать в такие сервисы фотографии людей и документы с личными данными — что с безопасностью и приватностью?
Технически — да, большинство сервисов это позволяют, но с точки зрения безопасности это всегда риск. Часть платформ хранит загруженные данные для дообучения моделей или внутренней аналитики, пусть и в обезличенном виде; другие (обычно платные бизнес‑тарифы) обещают не использовать ваши данные для обучения. В идеале в публичные ИИ‑сервисы не стоит загружать паспорта, банковские карты, меддокументы и чужие лица без согласия — для таких задач лучше использовать локальные решения или корпоративные продукты с формальными договорами и DPA.
3. Насколько точно ИИ распознает текст на фото (сканы, рукописные конспекты, скриншоты тестов)?
С печатным текстом на качественных сканах и скриншотах современные OCR‑модели дают точность, близкую к «человеческой» — отдельные ошибки чаще всего в мелочах (символы, знаки, редкие шрифты). Со сканами плохого качества, перекошенными фотографиями страниц и особенно с рукописными конспектами точность резко падает: часть текста может искажаться или пропадать. Скриншоты тестов и интерфейсов в целом распознаются хорошо, но разметку (варианты ответов, таблицы, сложную верстку) иногда приходится вручную поправлять.
4. Можно ли с помощью этих нейросетей решать задачи по фото (математика, тесты, техдокументация) и не будет ли это считаться «списыванием»?
Да, многие модели уверенно распознают условие по фото и выдают готовое решение или даже пошаговое объяснение. Вопрос «списывания» — это уже не про технологии, а про правила конкретной школы, вуза или экзамена: где‑то ИИ прямо запрещен, где‑то допускается как «калькулятор на стероидах», а для домашних заданий учителя все чаще сами рекомендуют использовать ИИ как помощника. Безопасный подход — использовать нейросеть как объяснитель и проверяющий: попросить разобрать решение, подсказать ход мысли, а не просто выдавать ответ и сдавать его как свой.
5. Как ИИ справляется с «сложными» картинками — плохо освещенными фото, маленьким шрифтом, рукописным текстом, коллажами?
Плохое освещение, шум, размытие. Модели могут «дотянуть» до читабельного уровня, но ошибки резко растут: буквы путаются, мелкий текст теряется, куски пропадают.
Маленький шрифт. Если его сложно прочитать глазами, нейросеть почти наверняка тоже будет ошибаться; помогает переснять ближе или увеличить картинку.
Рукописный текст. Здесь все сильно зависит от почерка: аккуратная «школьная» печатная рукопись распознается терпимо, быстрые записи с кривым почерком — плохо.
Коллажи и «захламленные» изображения. ИИ может понимать общую сцену, но при большом количестве мелких элементов, наложенного текста и графики растет шанс перепутать структуру (что к чему относится, где подпись, где часть картинки). В таких случаях лучше либо упростить изображение, либо загружать его частями.
Мы живем в момент, когда «понимание картинок» больше не привилегия человека — его уверенно перенимают нейросети. Обозрев восемь разных ИИ с распознаванием фото, можно увидеть общую тенденцию: распознавание изображений становится не отдельным продуктом, а встроенной функцией во все — от учебных помощников до комплексных ИИ‑платформ. Это открывает простор для автоматизации: задания по фото, сканы документов, каталоги товаров, визуальная аналитика — все это можно обрабатывать быстрее и точнее.
Подошел я к этому новому «чуду» от Сбера и сразу понял: это не банкомат, это высокотехнологичный надгробный памятник моим финансам. Дизайнеры называют это «галькой», но на деле это полированный обмылок, созданный для того, чтобы намылить шею каждому клиенту.
Первым делом эта железка сканирует мою рожу. Чёлка с камерами, как у Айфона, но вместо разблокировки она занимается фейс-контролем на нищету. Стоишь, лыбишься в объектив, а нейросеть в это время прикидывает, сколько из тебя еще можно выжать, прежде чем ты окончательно сдохнешь.
Кстати, о смерти. Они впихнули туда датчик пульса. Гениально! Сбер хочет знать точный момент, когда у тебя случится инфаркт от вида ипотечной ставки или баланса. Приложил пальчики — и банкомат такой: «О, пульс зашкаливает! Вижу, вы оценили нашу новую комиссию. Хотите заказать гроб со скидкой по подписке СберПрайм?»
А этот проектор? Нахрена он нужен, кроме как для публичного унижения? Теперь мой позорный остаток в 150 рублей транслируется на огромную белую доску. Спасибо, бл*ть, теперь не только я, но и вся очередь в курсе, что я — финансовый труп. Это не приватность, это широкоформатное шоу «Посмотрите на этого лоха».
Купюроприемник они засунули в самый низ. Чтобы забрать свои жалкие копейки, ты обязан отвесить этой зеленой херне низкий поклон. Сбер буквально ставит тебя на колени: «Кланяйся, смерд, забирай свои пятьсот рублей и проваливай».
На десерт — крючок для пакета. Выдерживает 5 килограмм. Как раз под объем макарон по акции, на которые тебе хватит денег после общения с этим «космическим кораблем».
Итог: киберпанк, который мы заслужили. Дорогущая светящаяся галька, которая измеряет твою агонию в 4K и заставляет кланяться за собственные деньги. Идеальный инструмент, чтобы вежливо и технологично пустить тебя по миру.
Технологии наблюдения становятся всё более распространёнными, и это касается не только нас, но и наших детей.
Распознавание лиц используется повсеместно - от аэропортов до банков и розничных магазинов - и позиционируется как удобная и безопасная система идентификации.
Технология позиционируется как быстрая, удобная и безопасная. Однако в то же время вызывают опасения нарушения конфиденциальности, как это было в Австралии с крупными ритейлерами, использующими эту технологию без согласия покупателей.
Что нас в итоге ждёт: опасный тотальный технологический контроль или надежное безопасное будущее? И что это значит для семей, особенно когда даже от детей требуют подтверждения личности с помощью одного лишь фото?
Две стороны распознавания лиц
Технология распознавания лиц преподносится как верх удобства. Это особенно продвигается в сфере туризма, где такие авиакомпании, как Qantas, рекламируют распознавание лиц как залог комфортного путешествия. Забудьте о том, чтобы искать паспорт и посадочный талон, - просто отсканируйте своё лицо, и всё готово.
Напротив, когда выяснилось, что крупные розничные сети, такие как Kmart и Bunnings, сканируют лица покупателей без их согласия, в дело вмешались регулирующие органы, и негативная реакция не заставила себя ждать. Здесь эта же технология воспринимается не как удобство, а как серьёзное злоупотребление доверием.
Ситуация становится ещё более запутанной, когда речь заходит о детях. В соответствии с новым законодательством Австралии платформы социальных сетей могут внедрить технологию проверки возраста по лицу, позиционируя её как способ обеспечить безопасность детей в интернете.
В то же время школы тестируют систему распознавания лиц для самых разных целей: от входа в класс до оплаты в столовой. Однако опасения по поводу неправомерного использования данных сохраняются. В одном из инцидентов Microsoft была обвинена в ненадлежащем обращении с биометрическими данными детей.
Для детей технология распознавания лиц постепенно становится стандартной, несмотря на вполне реальные риски.
Распознавания лиц и идентификации личности по камерам уличного наблюдения
Технология распознавания лиц становится всё более распространённой. Она работает путем сопоставления уникальных черт лица с базой данных сохранённых лиц. В отличие от пассивных камер видеонаблюдения, она не просто записывает, а активно идентифицирует и классифицирует людей.
Это чем-то похоже на идентификацию людей по QR-кодам во время пандемии COVID. Однако есть одно важное отличие: QR-код можно удалить или изменить, а аккаунт с лицом - нет.
После того, как снимок вашего лица или вашего ребенка сохранен, он может оставаться в базе данных вечно. Если база данных взломана, то параметры лица станут известны злоумышленникам. В мире, где банки и технологические платформы всё больше используют распознавание лиц для доступа, ставки очень высоки.
Более того, эта технология не является безотказной. Ошибочная идентификация это настоящая проблема для людей.
Системы определения возраста также часто неточны. Одного 17-летнего подростка легко можно отнести к детям, а другого - к взрослым. Это может ограничить их доступ к информации или, наоборот, разрешить то, что доступно лишь для взрослых.
Последствия
Эти риски уже влияют на жизнь людей. Представьте, что вас ошибочно внесли в список наблюдения из-за ошибки распознавания лиц, что приводит к задержкам и допросам при каждой вашей поездке.
Также украденные параметры лиц могут быть использованы для кражи личных данных.
В будущем ваше лицо может даже влиять на страхование или выдачу кредитов, а алгоритмы будут делать выводы о вашем здоровье или благонадёжности на основе фотографий или видео.
У технологии распознавания лиц есть очевидные преимущества, например, она помогает правоохранительным органам быстро идентифицировать подозреваемых в людных местах и обеспечивает удобный доступ в охраняемые зоны.
Но для детей риск неправильного использования и ошибок сохраняется на протяжении всей жизни.
Итак, хорошо или плохо?
На данный момент технология распознавания лиц, похоже, несёт больше рисков, чем преимуществ. В мире, полном мошенников и хакеров, мы можем заменить украденный паспорт или водительские права, но не можем изменить своё лицо.
Главная проблема в установлении границы между безрассудным внедрением и обязательным использованием.
Безопасность и удобство важны, но это не единственные ценности, которые стоят на кону. Пока не будут установлены надёжные и обязательные к исполнению правила, касающиеся безопасности, конфиденциальности и справедливости, нам следует действовать осторожно.
Поэтому в следующий раз, когда вас попросят отсканировать ваше лицо, не соглашайтесь сразу. Спросите: зачем это нужно? И действительно ли польза перевешивает риски - для меня и для всех остальных?
Фанаты группы Massive Attack рассказали, что во время шоу технология «real-time facial recognition» — она в реальном времени фиксировала лица зрителей и тут же выводила их изображения вместе с именами на огромный экран.
Каждый день мимо двери моего подъезда проходят десятки людей. Иногда это знакомые соседи, но чаще - курьеры или случайные гости.
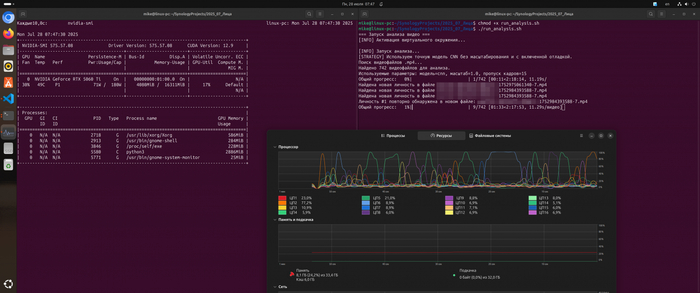
Домофонная камера всё записывает, но вручную пересматривать часы видео бессмысленно. Мне стало интересно: можно ли разово прогнать архив записей через алгоритмы компьютерного зрения и посмотреть, как быстро GPU справится с такой задачей.
Это был чисто экспериментальный проект: не «система слежки», а тест производительности и возможностей CUDA в связке с dlib и face_recognition.
На словах всё выглядело просто, а на деле пришлось пройти целый квест из несовместимых программ, капризных драйверов и упрямой библиотеки распознавания лиц. Но в итоге я собрал рабочее окружение и хочу поделиться опытом - возможно, это поможет тем, кто столкнётся с похожими проблемами.
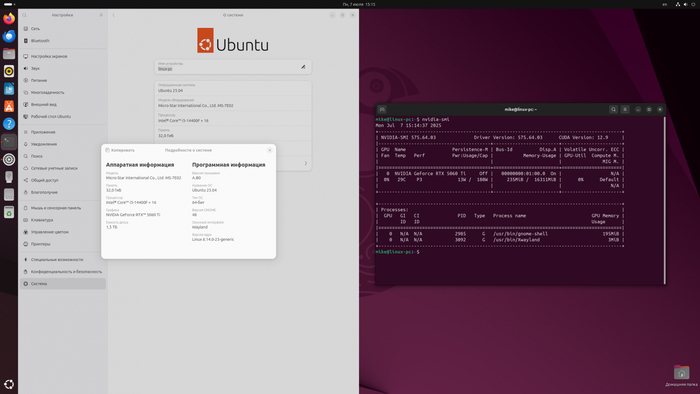
Часть 1: Битва за dlib с CUDA-ускорением на Ubuntu
dlib - это популярная библиотека на Python для компьютерного зрения и машинного обучения, особенно известная своим модулем распознавания лиц. Она умеет искать и сравнивать лица. Однако «из коробки» через pip она работает только на CPU, что для задач с большим объёмом данных ужасно медленно.
У меня видеокарта NVIDIA GeForce RTX 5060 Ti 16 ГБ и здесь на помощь приходит CUDA-ускорение - технология NVIDIA, позволяющая выполнять вычисления на графическом процессоре видеокарты. Для распознавания лиц это критично: обработка видео с несколькими тысячами кадров на CPU может занять часы, тогда как с GPU - минуты. CUDA задействует сотни параллельных потоков, что особенно эффективно для матричных операций и свёрточных сетей, лежащих в основе face_recognition.
Именно поэтому моя цель была не просто «запустить dlib», а сделать это с полной поддержкой GPU.
Эта часть рассказывает о том, как простая, на первый взгляд, задача превратилась в двухдневную борьбу с зависимостями, компиляторами и версиями ПО.
Расписываю по шагам - может быть кто-то найдёт эту статью через поиск и ему пригодится.
1. Исходная точка и первая проблема: неподходящая версия Python
Задача: установить face_recognition и его зависимость dlib на свежую Ubuntu 25.04.
Предпринятый шаг: попытка установки в системный Python 3.13.
Результат: ошибка импорта face_recognition_models. Стало ясно, что самые свежие версии Python часто несовместимы с библиотеками для Data Science, которые обновляются медленнее.
Решение: переход на pyenv для установки более стабильной и проверенной версии Python 3.11.9. Это был первый правильный шаг, решивший проблему с совместимостью на уровне Python.
2. Вторая проблема: dlib работает, но только на CPU
Предпринятый шаг: после настройки pyenv и установки зависимостей (numpy, opencv-python и т.д.), dlib и face_recognition успешно установились через pip.
Результат: скрипт анализа видео работал ужасно медленно (несколько минут на одно видео). Мониторинг через nvidia-smi показал 0% загрузки GPU.
Диагноз: стандартная установка dlib через pip скачивает готовый бинарный пакет ("wheel"), который собран без поддержки CUDA для максимальной совместимости. Чтобы задействовать GPU, dlib нужно компилировать из исходного кода прямо на моей машине.
3. Третья, главная проблема: конфликт компиляторов CUDA и GCC
Предпринятый шаг: попытка скомпилировать dlib из исходников с флагом -DDLIB_USE_CUDA=1.
Результат: сборка провалилась с ошибкой. Анализ логов показал, что cmake находит CUDA Toolkit 12.6, но не может скомпилировать тестовый CUDA-проект. Ключевая ошибка: error: exception specification is incompatible with that of previous function "cospi"
Диагноз: мой системный компилятор GCC 13.3.0 (стандартный для Ubuntu 25.04) был несовместим с CUDA Toolkit 12.6. Новые версии GCC вносят изменения, которые ломают сборку с более старыми версиями CUDA.
4. Попытки решения конфликта компиляторов
Шаг №1: установка совместимого компилятора. Я установил gcc-12 и g++-12, которые гарантированно работают с CUDA 12.x.
Шаг №2: ручная сборка с указанием компилятора. Я пытался собрать dlib вручную, явно указав cmake использовать gcc-12:
Результат: та же ошибка компиляции. cmake, несмотря на флаги, по какой-то причине продолжал использовать системные заголовочные файлы, конфликтующие с CUDA.
Шаг №3: продвинутый обходной маневр (wrapper). Я создал специальный скрипт-обертку nvcc_wrapper.sh, который должен был принудительно "подсовывать" nvcc (компилятору NVIDIA) нужные флаги и использовать gcc-12. Результат: снова неудача. Ошибка 4 errors detected in the compilation... осталась, что указывало на фундаментальную несовместимость окружения.
Капитуляция перед реальностью Несмотря на все предпринятые шаги - использование pyenv, установку совместимого компилятора GCC-12 и даже создание wrapper-скриптов - dlib так и не удалось скомпилировать с поддержкой CUDA на Ubuntu 25.04.
Похоже проблема была не в моих действиях, а в самой операционной системе. Использование не-LTS релиза Ubuntu для серьезной разработки с проприетарными драйверами и библиотеками (как CUDA) - это путь, полный боли и страданий.
Принял решение установить Ubuntu 24.04 LTS, для которой NVIDIA предоставляет официальную поддержку CUDA Toolkit 12.9 Update 1.
Часть 2: чистый лист и работающий рецепт
Установил Ubuntu 24.04 LTS - систему с долгосрочной поддержкой, для которой NVIDIA предоставляет официальный CUDA Toolkit и драйверы. Это был шаг назад, чтобы сделать два вперёд.
Но даже на чистой системе путь не был устлан розами. Первые попытки установки нужной версии Python через apt провалились (в репозиториях Noble Numbat её просто не оказалось), что вернуло меня к использованию pyenv. После нескольких итераций, проб и ошибок, включая установку CUDA Toolkit и отдельно cuDNN (библиотеки для нейросетей, без которой dlib не видит CUDA), родился финальный, работающий рецепт.
Проверка pyenv. Скрипт начинается с проверки наличия pyenv. Это позволяет использовать нужную версию Python (3.11.9), а не системную, избегая конфликтов.
Установка системных библиотек. Для компиляции dlib из исходного кода необходимы инструменты сборки (build-essential, cmake) и библиотеки для работы с математикой и изображениями (libopenblas-dev, libjpeg-dev). Скрипт автоматически их устанавливает.
Важно: скрипт предполагает, что CUDA Toolkit и отдельно cuDNN уже установлены по официальным инструкциям NVIDIA для вашей системы - они по ссылкам.
Создание чистого venv. Создаем изолированное виртуальное окружение, чтобы зависимости нашего проекта не конфликтовали с системными. Скрипт удаляет старое окружение, если оно существует, для гарантированно чистой установки.
Ключевой момент: установка dlib. Это сердце всего процесса. Команда pip install dlib с особыми флагами:
--no-binary :all: — этот флаг принудительно запрещает pip скачивать готовый, заранее скомпилированный пакет (wheel). Он заставляет pip скачать исходный код dlib и начать компиляцию прямо на вашей машине.
--config-settings="cmake.args=-DDLIB_USE_CUDA=1" — а это инструкция для компилятора cmake. Мы передаем ему флаг, который говорит: «При сборке, пожалуйста, включи поддержку CUDA».
Именно эта комбинация заставляет dlib собраться с поддержкой GPU на Ubuntu 24.04 LTS чтобы использовать видеокарту, а не в стандартном CPU-only варианте.
# --- Проверка наличия pyenv --- if ! command -v pyenv &> /dev/null; then echo -e "\n\033[1;31m[ERROR] pyenv не найден. Установи pyenv перед запуском.\033[0m" exit 1 fi
echo -e "\n[INFO] Выбор версии Python $PYTHON_VERSION_TARGET через pyenv..." pyenv local $PYTHON_VERSION_TARGET echo "[INFO] Текущая версия Python: $(python --version)"
# --- Проверка системных библиотек --- echo -e "\n[INFO] Проверка и установка системных библиотек для dlib..." sudo apt update sudo apt install -y build-essential cmake libopenblas-dev liblapack-dev libjpeg-dev git
# --- Очистка и создание виртуального окружения --- if [ -d "$VENV_DIR" ]; then echo "[INFO] Удаление старого виртуального окружения '$VENV_DIR'..." rm -rf "$VENV_DIR" fi
echo "[INFO] Создание виртуального окружения '$VENV_DIR'..." python -m venv "$VENV_DIR"
Камера, смотрящая на лифтовой холл. Фото из интернета
После победы над зависимостями у меня есть полностью рабочее окружение с CUDA-ускорением. Настало время применить его к реальным данным. Мои исходные данные - это архив видеозаписей с двух IP-камер, которые пишут видео на сетевой накопитель Synology Surveillance Station (есть аналоги). Для приватности я заменю реальные имена камер на условные:
podiezd_obshiy\ - камера, смотрящая на лифтовой холл.
dver_v_podiezd\ - камера из домофона, направленная на улицу.
Внутри каждой папки видео отсортированы по каталогам с датами в формате ГГГГММДД с суффиксом AM или PM. Сами файлы имеют информативные имена, из которых легко извлечь дату и время записи: podiezd_obshiy-20250817-160150-....mp4.
Камера из домофона, направленная на улицу. Здесь качество гораздо лучше потому что камера цифровая, а не аналоговая как у меня из квартирного домофона. Это фото из интернета
Я использовал стандартную библиотеку argparse. Она позволяет задавать ключевые параметры прямо из командной строки:
--model: выбор детектора лиц (hog или cnn).
--scale: коэффициент масштабирования кадра. Уменьшение кадра (например, до 0.5) ускоряет обработку, но может пропустить мелкие лица.
--skip-frames: количество пропускаемых кадров. Анализировать каждый кадр избыточно и медленно; достаточно проверять каждый 15-й или 25-й.
Скрипт находит все .mp4 файлы в указанной директории и запускает основной цикл, обрабатывая каждый видеофайл.
1. Детекция лиц: HOG против CNN
face_recognition предлагает два алгоритма детекции: HOG (Histogram of Oriented Gradients) и CNN (Convolutional Neural Network). HOG - классический и очень быстрый метод, отлично работающий на CPU. CNN - это современная нейросетевая модель, гораздо более точная (особенно для лиц в профиль или под углом), но крайне требовательная к ресурсам.
Раз я так боролся за CUDA, выбор очевиден - будем использовать cnn. Это позволит находить лица максимально качественно, не жертвуя скоростью.
2. Уникализация личностей
Как скрипт понимает, что лицо на двух разных видео принадлежит одному и тому же человеку? Он преобразует каждое найденное лицо в face_encoding - вектор из 128 чисел, своего рода уникальный «цифровой отпечаток».
Когда появляется новое лицо, его «отпечаток» сравнивается со всеми ранее сохраненными. Сравнение происходит с определенным допуском (tolerance). Установил его равным 0.6 - это золотая середина, которая позволяет не путать разных людей, но и узнавать одного и того же человека при разном освещении или угле съемки.
3. Умный подсчет: один файл - один голос
Простая логика подсчета привела бы к абсурдным результатам: если курьер провел у двери 30 секунд, его лицо могло бы быть засчитано 50 раз в одном видео. Чтобы этого избежать, я ввел простое, но эффективное правило: считать каждое уникальное лицо только один раз за файл.
4. Создание красивых иконок
Чтобы в кадр попадала вся голова с прической и частью шеи, я добавил в функцию create_thumbnail логику с отступами. Она берет размер найденного лица и увеличивает область кадрирования на 50% по вертикали и горизонтали. Так превью в отчете выглядят гораздо лучше и живее.
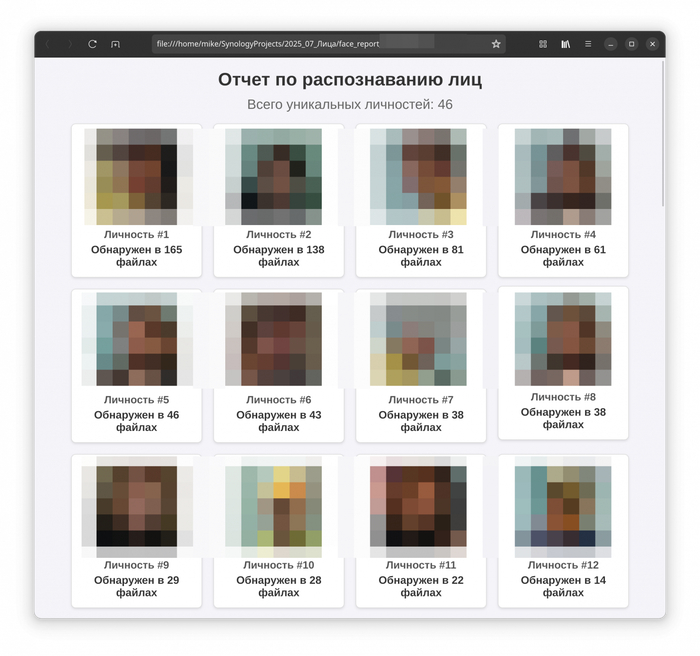
5. Генерация наглядного HTML-отчета
Финальный штрих - вся собранная информация (иконки, количество появлений) упаковывается в красивый и понятный HTML-отчет. Никаких сложных фреймворков: с помощью f-string и небольшого блока CSS генерируется страница, на которой все уникальные личности в этом эксперименте отсортированы по частоте появлений.
Часть 4: результаты и выводы
Для эксперимента я посчитал уникальных людей в выборке. Скрипт я запускал разово, отдельно для каждой камеры - это не постоянно работающий сервис, а скорее любопытная исследовательская игрушка.
Результаты оказались наглядными, но и показали пределы технологии. Качество распознавания напрямую зависит от исходного видео: камера домофона с узким углом и посредственным сенсором даёт мыльную картинку, на которой детали лица часто теряются. Для сравнения, камера 2,8 мм 4 Мп в лифтовом холле (широкоугольный объектив и матрица с разрешением 2560×1440) выдаёт значительно более чёткие кадры - глаза, контуры лица и текстура кожи читаются лучше, а значит, алгоритм реже ошибается.
Но и здесь есть нюанс: один и тот же человек в куртке и без неё, в кепке или с распущенными волосами, зачастую определяется как разные личности - видимо надо где-то крутить настройки. Поэтому цифры в отчёте стоит воспринимать не как абсолютную истину, а как любопытную статистику, показывающую общее движение людей, а не точный учёт.
Заключение
От простой идеи - «разово прогнать архив записей через алгоритмы компьютерного зрения и посмотреть, как быстро GPU справится с такой задачей» - я прошёл путь через череду технических ловушек: несовместимые версии Python, упёртый dlib, капризы CUDA и GCC.
К тому же это не сервис, а исследовательская проверка возможностей GPU.