PG_EXPECTO v.7 : методология доказательной оптимизации высоконагруженных инсталляций PostgreSQL
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

Инфраструктурный коллапс: когда шина данных не выдерживает.
Анализ инцидента производительности высоконагруженной СУБД (CPU=200 RAM=1TB).
Введение
Представленный ниже материал представляет собой результаты углублённого анализа инцидента производительности, произошедшего в высоконагруженной продуктивной среде под управлением СУБД PostgreSQL. В ходе исследования рассматривается переход системы от состояния относительной стабильности к фазе комплексной деградации, затронувшей вычислительные ресурсы, подсистему ввода-вывода и механизмы синхронизации ядра СУБД. Сложность диагностики подобных состояний обусловлена необходимостью выявления первопричин, находящихся на пересечении аппаратного обеспечения, операционной системы и внутренних процессов базы данных, что требует применения системного подхода к сбору и интерпретации метрик.
В данной демонстрации наглядно показано применение инструментария pg_expecto, который позиционируется не только как средство нагрузочного тестирования, но и как эффективный механизм для постмортем-анализа и оптимизации «боевых» инсталляций. Использование pg_expecto позволило не ограничиться констатацией факта падения операционной скорости, а выявить критическую конкуренцию за буферный кэш (LWLock: BufferMapping), изменение паттернов работы расширений СУБД и скрытые проблемы дисковой подсистемы, маскируемые усредненными метриками. Публикация детализирует методологию сравнительного статистического и корреляционного анализа, демонстрируя, как сопоставление эталонного и аварийного периодов функционирования позволяет сформировать научно обоснованные рекомендации по оптимизации как конфигурации СУБД, так и поддерживающей её инфраструктуры.
Инцидент производительности СУБД
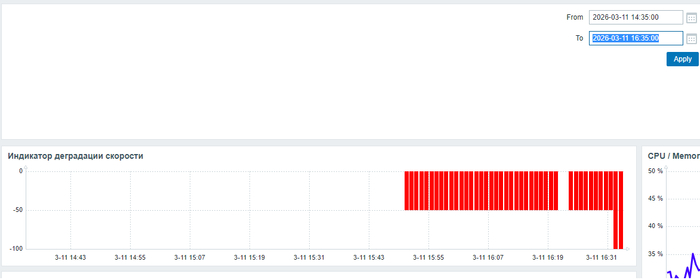
Дашборд Zabbix .
Дата и время инцидента: 11/03/2026 16:35
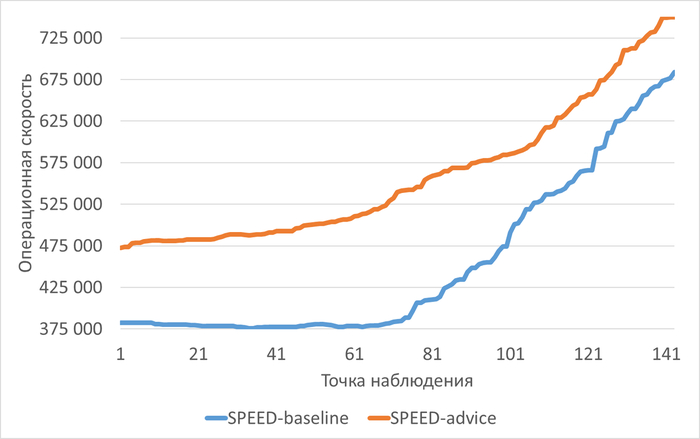
Производительность и ожидания СУБД в период 14:35 - 16:35
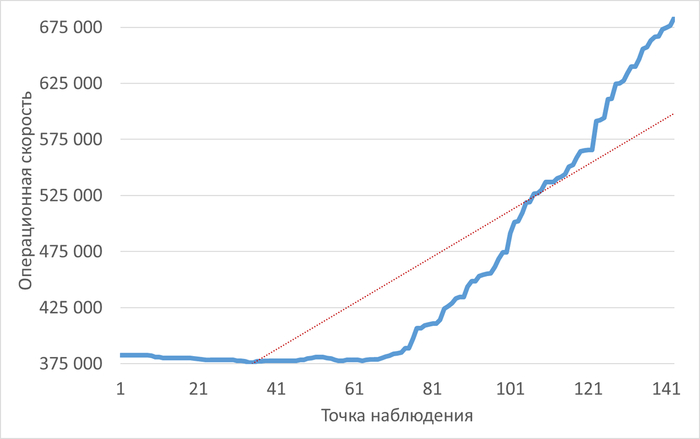
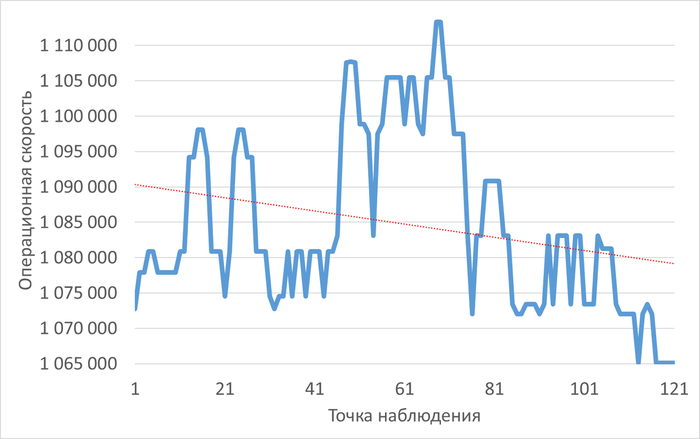
Операционная скорость
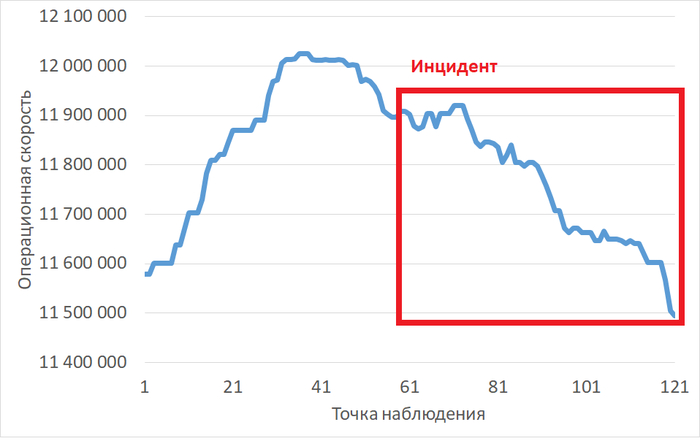
График изменения операционной скорости
Рис.1 - График изменения операционной скорости в отрезке [время инцидента; время инцидента - 2 часа]. Рост производительности сменился снижением.
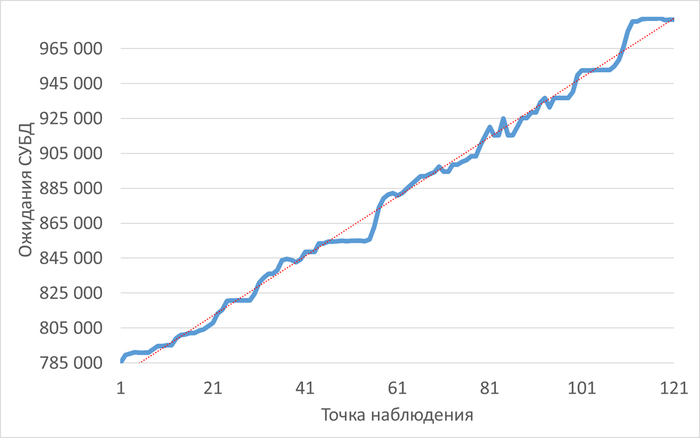
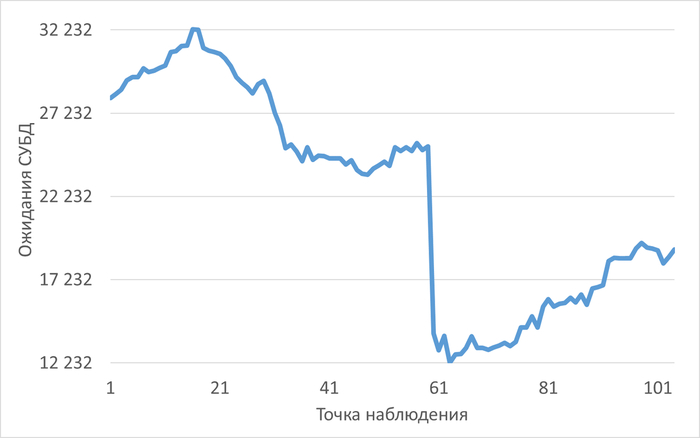
Ожидания СУБД
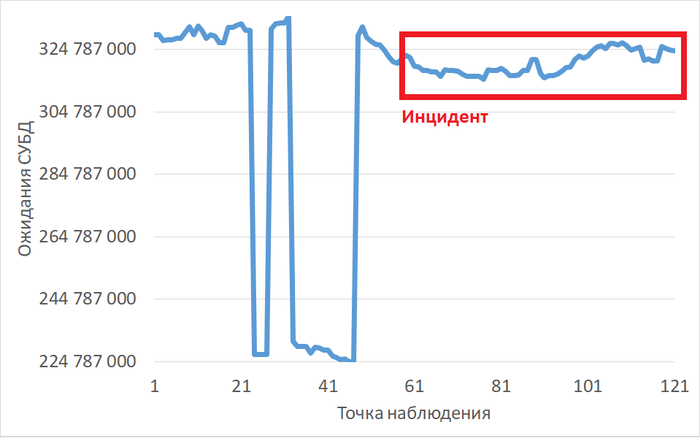
График изменения ожиданий СУБД
Рис.2 - График изменения ожиданий СУБД в отрезке [время инцидента; время инцидента - 2 часа]. Рост ожиданий СУБД в течении часа до иницидента.
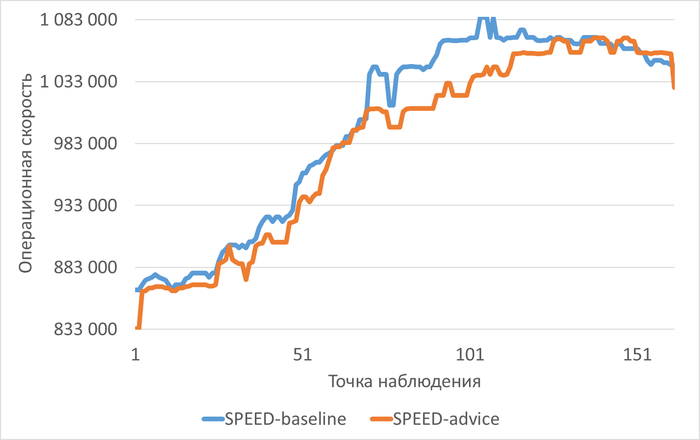
Производительность и ожидания СУБД в период инцидента производительности СУБД
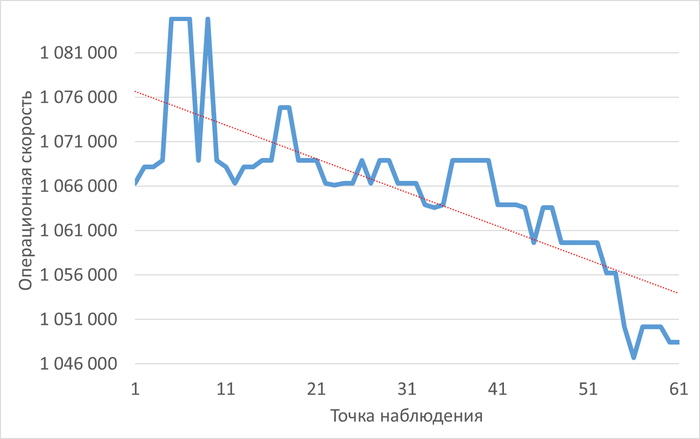
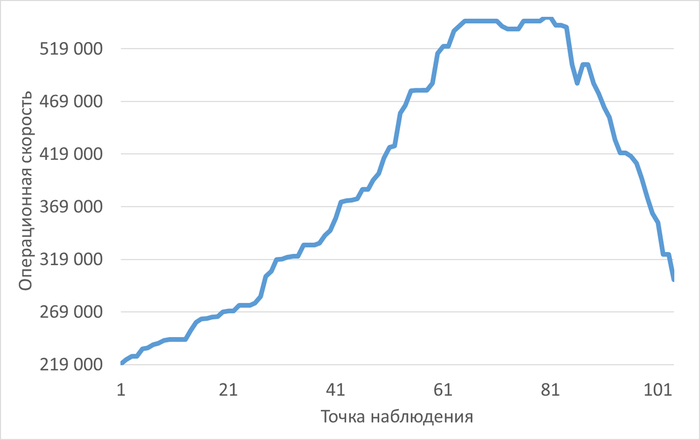
Операционная скорость
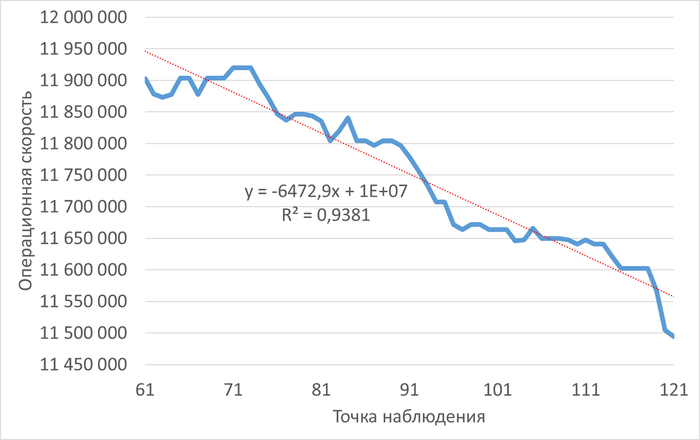
График изменения операционной скорости в ходе инцидента
Рис.3 - Снижение операционной скорости в ходе инцидента. Коэффициент детерминации = 0.9
Ожидания СУБД
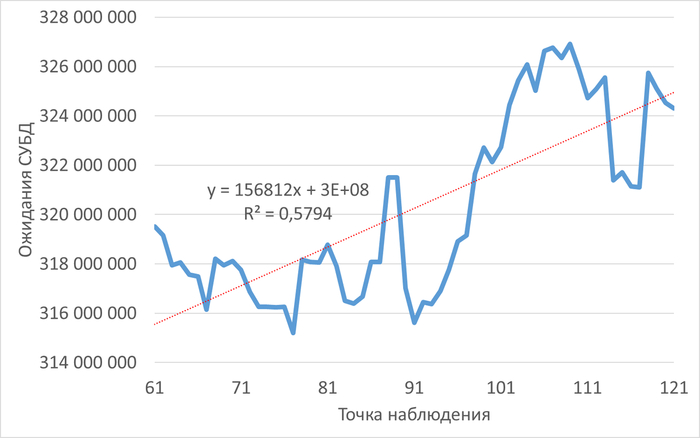
График изменения ожиданий СУБД в ходе инцидента
Рис.4 - Рост ожиданий СУБД в ходе инцидента. Коэффициент детерминации = 0.6
1. Сводный сравнительный отчет по производительности СУБД и инфраструктуры 2026-03-11 14:35 - 16:35
Общая информация
Объект анализа: СУБД PostgreSQL 15.13 (конфигурация из файла _1.settings.txt) и инфраструктура (vmstat).
Периоды сравнения:
Инцидент: 2026-03-11 15:35 — 16:35 (файл _2.postgresql_vmstat.txt). Период, квалифицированный как инцидент производительности.
Тест: 2026-03-11 14:35 — 15:35 (файл _2.1.test.postgresql_vmstat.txt). Период, взятый как тестовый отрезок для сравнения.
Аппаратная конфигурация:
CPU: 192 ядра (Intel Xeon Platinum 8280L), 4 NUMA-узла.
RAM: ~1008 GB.
Дисковая подсистема: Тома LVM на отдельных дисках для данных (/data, 56T), WAL (/wal, 1T), резервных копий (/backup, 2.9T) и логов (/log, 100G).
Итог по разделу "1. СРАВНИТЕЛЬНЫЙ СТАТИСТИЧЕСКИЙ АНАЛИЗ ОЖИДАНИЙ СУБД"
Ключевое изменение: Основная нагрузка сместилась с Extension в тестовом периоде на LWLock в инциденте. Хотя Extension все еще имеют высокий приоритет, их вклад в общее время ожиданий снизился, в то время как вклад LWLocks остался критически высоким.
В инциденте также появились и стали значимыми ожидания типов IO и Lock, которые в тестовом периоде не оказывали влияния. Это говорит о том, что система вошла в фазу комплексной деградации, затронувшей диск и блокировки транзакций.
Итог по разделу "2. СРАВНИТЕЛЬНЫЙ ТРЕНДОВЫЙ АНАЛИЗ ПРОИЗВОДИТЕЛЬНОСТИ vmstat"
Главный сигнал инцидента: Резкое падение cpu_id (простоя CPU) при одновременном падении скорости БД. CPU начинает активно работать, но не на выполнении полезной нагрузки, а на обслуживании простоев (скорее всего, связанных с LWLocks и конкуренцией).
В тестовом периоде CPU простаивал больше, очереди на выполнение (r) сокращались — система была сбалансирована.
Проблемы с диском (b, wa), наблюдавшиеся в тесте, в инциденте пошли на спад, что подтверждает смещение фокуса проблемы с IO на CPU и блокировки.
Итог по разделу "3. СРАВНИТЕЛЬНЫЙ СТАТИСТИЧЕСКИЙ АНАЛИЗ ОЖИДАНИЙ СУБД и МЕТРИК vmstat"
Основное различие в поведении Extension. В инциденте они стали значительно сильнее коррелировать с прерываниями (in), что может указывать на изменение их паттерна работы (например, увеличение частоты вызовов внешних API или обмен по сети).
Модель зависимости блокировок (Lock) от очереди на CPU (r) в инциденте стала слабой, хотя связь осталась. Это значит, что в формирование очереди на CPU теперь вносят вклад и другие факторы, прежде всего LWLocks, которые не отслеживаются напрямую vmstat.
Итог по разделу "4. СРАВНЕНИЕ ДИАГРАММ ПАРЕТО ПО WAIT_EVENT_TYPE и QUERYID"
Усложнение структуры отказов: В инциденте к проблемам с Extension и transactionid (блокировки строк) добавились серьезные проблемы с:
Конкуренцией за буферный кэш (LWLock: BufferMapping).
Физическими чтениями данных (IO: DataFileRead).
Синхронной записью WAL (IO: WALSync).
Блокировками версий строк (Lock: tuple).
Концентрация нагрузки: Основные проблемные запросы — прежние, но теперь они создают более сложный и разнообразный профиль ожиданий. Появление новых запросов в топе по IO и Lock говорит о том, что либо начали выполняться новые, тяжелые операции, либо изменился план выполнения старых запросов.
Проблемы СУБД
1. Критическая конкуренция за буферный кэш (LWLock: BufferMapping): Является основной причиной падения скорости в инциденте. Процессы проводят время в очередях за доступом к страницам в shared_buffers.
2. Деградация работы расширений (Extension): Расширения стали работать иначе, вызывая всплески прерываний и нагружая CPU, что усугубляет общую ситуацию. Главные виновники — запросы -503898190... и -428029360....
3. Рост физических чтений с диска (IO: DataFileRead): Буферный кэш перестал эффективно кэшировать данные, что привело к падению производительности и росту IO-ожиданий.
4. Появление синхронных проблем с WAL (IO: WALSync): Указывает на то, что запись в WAL начала тормозить транзакции, вероятно, из-за исчерпания пропускной способности диска с WAL или из-за конкурентной записи.
5. Расширение спектра блокировок (Lock: tuple): К проблемам с блокировками транзакций (transactionid) добавились блокировки отдельных версий строк (tuple), что говорит о высоком конкурентном доступе к одному и тому же набору данных.
Проблемы инфраструктуры
1. Неэффективная утилизация CPU: Процессорное время уходит не на полезную работу, а на оверхед (прерывания, ожидания). Это подтверждается падением cpu_id при падении скорости БД.
2. Рост прерываний: Увеличение корреляции Extension с in (прерывания) указывает на возросшую нагрузку на ядро ОС.
3. Косвенные признаки дисковой проблемы: Хотя прямые метрики wa и b улучшились, появление IO: DataFileRead и WALSync в топе ожиданий СУБД говорит о том, что дисковая система перестала справляться с пиковыми нагрузками, даже если это не видно на уровне усредненных метрик vmstat.
4. Острый дефицит свободной памяти: В обоих периодах свободной RAM менее 5% (ALARM). Система постоянно работает на грани нехватки оперативной памяти, что увеличивает вероятность вытеснения страниц и усиливает конкуренцию за буферный кэш. Это фоновый хронический фактор, который, вероятно, и спровоцировал инцидент при изменении паттерна нагрузки.
2. Рекомендации по итогам анализа инцидента производительности СУБД и инфраструктуры 2026-03-11 14:35 - 16:35
Рекомендации по оптимизации СУБД
1. Оптимизировать запросы-лидеры:
Провести детальный разбор планов выполнения для queryid:
-5038981907002478858
-4280293605113329019
-1757223094415174739
7667106468890705260
Выявить причины конкуренции за BufferMapping (частое чтение разных страниц) и LockManager.
Рассмотреть возможность оптимизации индексов, переписывания запросов для уменьшения числа обращений к буферному кэшу и блокировок.
2. Проанализировать и оптимизировать работу расширений:
Определить, какие расширения (из списка shared_preload_libraries) вызывают наибольшие ожидания и прерывания.
Проверить конфигурацию расширений (особенно pgpro_stats, pg_wait_sampling, dblink, postgres_fdw).
Если расширения выполняют внешние вызовы (через dblink или fdw), оценить сетевые задержки и возможность кэширования результатов.
Рассмотреть возможность отключения или замены неэффективных расширений.
3. Настроить параметры памяти для снижения конкуренции:
shared_buffers (сейчас 251807 MB ~ 245 GB). Учитывая 1 TB RAM и нехватку свободной памяти, значение уже велико. Возможно, требуется уменьшение для освобождения памяти ОС под кэш файловой системы. Либо наоборот, увеличение не даст эффекта, так как конкуренция за буферы может возрасти. Рекомендуется провести тестирование с значениями 20-25% RAM.
work_mem (1 GB) – очень высокое значение. Оно может приводить к быстрому исчерпанию памяти при большом числе сортировок/хешей. Уменьшить до разумных пределов (например, 32-128 MB) и контролировать использование через log_temp_files.
maintenance_work_mem (16 GB) – для VACUUM и CREATE INDEX. Можно оставить, но следить за параллельными операциями.
effective_cache_size (747230 MB) – завышено, но не критично. Уменьшить до 80-90% от RAM.
4. Снизить нагрузку на WAL и контрольные точки:
Проверить, оправдано ли значение synchronous_commit = remote_write. Для особо критичных транзакций можно оставить, для остальных рассмотреть off или local.
Увеличить max_wal_size (сейчас 8 GB) для уменьшения частоты контрольных точек. Рекомендуется 16-32 GB, учитывая интенсивность записи.
Оптимизировать checkpoint_timeout (15 мин) и checkpoint_completion_target (0.9) для растягивания записи "грязных" страниц.
5. Анализ блокировок:
Включить сбор статистики по блокировкам (track_wait_timing и pg_locks).
Искать длинные транзакции и неоптимальные уровни изоляции (особенно Serializable, если используется).
Для уменьшения блокировок tuple рассмотреть возможность использования индексов, покрывающих запросы, и оптимизации планов, избегающих последовательного сканирования.
Рекомендации по оптимизации инфраструктуры
1. Увеличить объем оперативной памяти:
Текущая нехватка свободной RAM (<5%) – критический фактор. Добавление памяти (если возможно) или перераспределение ресурсов ВМ даст наибольший эффект, снизив давление на буферный кэш и позволив увеличить shared_buffers или файловый кэш ОС.
2. Оптимизировать дисковую подсистему:
Для WAL: Перенести WAL на отдельный высокоскоростной диск (NVMe) с низкой задержкой. Текущий /wal на LVM поверх vdg (вероятно, HDD) не справляется с синхронной записью (WALSync).
Для данных: Оценить производительность тома /data (56 ТБ на нескольких дисках). Возможно, требуется увеличение количества дисков в LVM для распараллеливания IO, либо использование более быстрых накопителей.
Настроить планировщик ввода-вывода в ОС (например, none для NVMe, deadline или mq-deadline для HDD).
3. Настроить параметры ядра ОС:
vm.swappiness: Уменьшить (например, до 10), чтобы избежать лишнего свопирования, хотя свопинг не используется, но параметр влияет на склонность к вытеснению страниц.
vm.dirty_ratio / vm.dirty_background_ratio: Уменьшить для контроля фоновой записи и предотвращения накопления грязных страниц.
Сетевые настройки: Увеличить буферы сокетов, если расширения активно используют сеть.
Параметры планировщика задач: Убедиться, что процессы PostgreSQL закреплены за ядрами CPU (нужно проверить распределение по NUMA-узлам). На мощной машине с 4 сокетами важно избегать перекосов памяти.
4. Профилирование CPU и прерываний:
Использовать perf, mpstat -I для выяснения источника роста прерываний, связанных с расширениями.
Проверить драйверы сетевых карт и настройки очередей прерываний (RSS, RPS). Возможно, требуется настройка affinity прерываний для распределения нагрузки.
5. Усилить мониторинг:
Настроить оповещения по достижению порогов: свободная память <10%, рост procs b > 1-2, увеличение времени ожидания WALSync.
Собирать данные iostat для дисков с данными и WAL для выявления пиков latency.
6. Рассмотреть возможность контейнеризации/виртуализации:
Если сервер виртуальный (KVM), проверить, не происходит ли конкуренция с соседними ВМ за дисковые ресурсы. Обратиться к администратору гипервизора.
3. Сводный сравнительный отчет по подсистеме IO 2026-03-11 14:35 - 16:35.
Список дисковых устройств
Анализ проводился для следующих дисковых устройств, входящих в состав LVM для хранения данных СУБД и WAL:
vdg — физический диск, используемый для WAL (/wal) и раздела подкачки.
vdh, vdi, vdj, vdk — физические диски, объединенные в LVM-том /data для хранения данных СУБД.
Сравнительный анализ граничных значений по дисковым устройствам
В данном разделе сравниваются минимальные, медианные и максимальные значения ключевых метрик за тестовый период и период инцидента.
Устройство vdg (WAL):
Тест: Нагрузка на запись (w/s, wMB/s) стабильно низкая. Операции чтения практически отсутствуют. Утилизация устройства (device_util) минимальна (медиана ~5.9%).
Инцидент: Резкий рост нагрузки на запись. Медиана w/s выросла с ~373 до ~689, а wMB/s — с ~7.75 до ~16.0. Несмотря на рост, утилизация устройства остается низкой (медиана ~10.2%), что говорит о его высокой производительности и малом влиянии на общую картину.
Устройства данных vdh, vdi, vdj, vdk:
Тест: На всех четырех дисках наблюдается высокая и стабильная смешанная нагрузка. Медианные значения составляют:
r/s: ~12 200
w/s: ~500
Утилизация (device_util): ~87%
Глубина очереди (aqu-sz): ~2.0
Инцидент: Нагрузка на диски данных значительно возрастает.
r/s: медиана увеличивается до ~13 500.
w/s: медиана удваивается, достигая ~1 100.
wMB/s: медиана возрастает с ~4.8 до ~10.5.
Утилизация остается на критическом уровне (медиана ~90%).
Глубина очереди незначительно растет (медиана ~2.5).
Вывод: В период инцидента произошло существенное увеличение нагрузки на диски данных (vdh-vdk), особенно на операции записи (рост в 2 раза). Диск WAL (vdg) также испытал рост нагрузки на запись, но остался далек от насыщения.
Итог по разделу "СРАВНИТЕЛЬНЫЙ СТАТИСТИЧЕСКИЙ АНАЛИЗ КОРРЕЛЯЦИЯ VMSTAT и IOSTAT по дисковым устройствам"
В тестовом периоде наблюдалась высокая нагрузка на диски данных, но механизмы кэширования и буферизации работали иначе. В период инцидента характер взаимосвязей изменился: главным фактором стало прямое влияние загрузки диска на ожидание процессов (wa). Ключевым ограничивающим фактором стала пропускная способность дисков, о чем свидетельствует появление сильных корреляций с метриками MBps.
Проблемы инфраструктуры по итогам сравнительного анализа
1. Хроническая перегрузка дисков данных: Диски vdh, vdi, vdj, vdk постоянно работают с утилизацией более 80-90% и глубиной очереди более 2, что является критическим состоянием.
2. Усугубление проблемы в период инцидента: На фоне и без того высокой нагрузки произошел скачок операций записи (в 2 раза), что превратило пропускную способность дисков в главное узкое место.
3. Неэффективность буферизации: В момент пика нагрузки корреляция буферов с дисковым вводом-выводом пропала, что говорит о возможной нехватке буферов или неоптимальном характере нагрузки для их использования.
4. Рост зависимости от кэша: Увеличение корреляции кэша с дисковыми операциями в период инцидента указывает на то, что система пытается компенсировать недостаток дисковой производительности за счет памяти, но это не решает проблему полностью.
5. Отсутствие запаса пропускной способности: Система данных СУБД уперлась в физический предел скорости чтения/записи дисков.
Рекомендации по инфраструктуре по итогам сравнительного анализа
1. Анализ характера нагрузки: Определить, какие запросы/процессы генерируют столь высокий уровень операций записи (w/s и wMB/s) на дисках данных. Рассмотреть возможность их оптимизации, дедупликации или переноса.
2. Масштабирование дисковой подсистемы:
Увеличение количества дисков: Добавить еще физических дисков в LVM-пул /data для распределения нагрузки и увеличения суммарной пропускной способности и IOPS.
Апгрейд на более производительные диски: Рассмотреть замену текущих дисков на более скоростные модели (например, NVMe), если текущая конфигурация не позволяет обеспечить требуемую пропускную способность.
3. Тюнинг параметров СУБД: Пересмотреть настройки, влияющие на использование буферов и кэша при высоких нагрузках на запись.
Проанализировать адекватность размера shared_buffers (установлен в 251 ГБ) и work_mem (1 ГБ) для текущей рабочей нагрузки.
Проверить эффективность настроек контрольной точки (checkpoint_timeout, max_wal_size), так как рост записи на диски данных может быть связан с сбросом "грязных" страниц на диск.
4. Разделение нагрузки: Рассмотреть возможность физического разделения наиболее активных таблиц или индексов на разные дисковые пулы, если это позволяет структура данных и приложения.
Общий итог
Проведенный сравнительный анализ производительности СУБД PostgreSQL в периоды штатной работы и развития инцидента позволил выявить комплексный характер деградации системы. Установлено, что непосредственной причиной падения операционной скорости стала критическая конкуренция за буферный кэш (LWLock: BufferMapping), усугубленная изменением паттернов работы расширений, ростом физических чтений с диска и появлением синхронных ожиданий записи WAL. Хронический дефицит оперативной памяти и перегрузка дискового массива данных (утилизация более 90%) создали благоприятные условия для развития инцидента, переведя фокус нагрузки с подсистемы ввода-вывода на механизмы блокировок и процессорное время, что подтверждается изменением корреляционных связей между метриками СУБД и инфраструктуры.
Представленный пример практического применения инструментария pg_expecto наглядно демонстрирует его эффективность не только в задачах нагрузочного тестирования, но и при анализе производительности высоконагруженных продуктивных систем. Возможность проведения сравнительного статистического анализа, трендового моделирования и корреляции метрик СУБД с показателями операционной среды позволяет перейти от простой констатации факта падения скорости к выявлению первопричин деградации. Использование pg_expecto в данном исследовании обеспечило формирование научно обоснованных, верифицированных рекомендаций по оптимизации, что подтверждает его ценность как инструмента глубокой диагностики и постмортем-анализа для промышленных инсталляций PostgreSQL.