PG_EXPECTO и математическая статистика: как метод majority vote повышает достоверность рекомендаций ИИ для PostgreSQL
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

pg_expecto: Коллективный разум вместо случайных ошибок
Может ли ИИ заменить эксперта по PostgreSQL?
Искусственный интеллект все активнее интегрируется в задачи оптимизации баз данных, однако вопрос о его способности полностью заменить человека-эксперта остается открытым. В представленном исследовании анализируется работа нейросетевой модели DeepSeek при оценке производительности СУБД PostgreSQL с применением статистического метода «majority vote» (голосование). В рамках работы выполнен сравнительный анализ двух сценариев выборки — с использованием пяти и одиннадцати независимых прогонов модели — с целью оценки эффективности данного подхода для верификации выводов, минимизации случайных ошибок и повышения надежности итоговых рекомендаций.
Результаты демонстрируют, что даже наиболее совершенная модель ИИ сохраняет статус инструмента: нейросеть эффективно выявляет закономерности и диагностирует узкие места (такие как дефицит оперативной памяти или перегрузка дисковой подсистемы), однако окончательная интерпретация результатов в контексте конкретной системы по-прежнему требует участия опытного администратора баз данных. Таким образом, искусственный интеллект не заменяет эксперта, но становится его высокоэффективным ассистентом, обеспечивая фильтрацию случайных ошибок и существенную экономию времени на рутинном анализе.
Постановка проблемы
В отличие от классического программного обеспечения, нейросеть не выполняет жестко заданный алгоритм. Она 🔴генерирует ответ путем вероятностного предсказания следующей единицы информации (токена).🔴
...
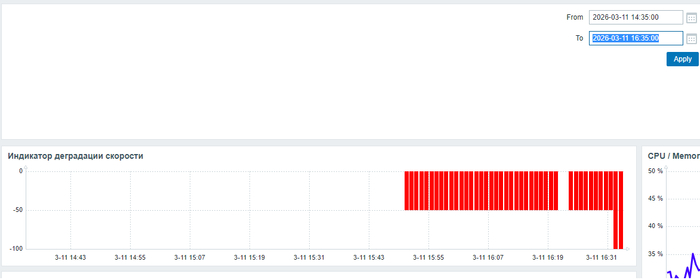
Для инженера по производительности это означает катастрофу воспроизводимости.
Доверие к инструменту будет подорвано, если на одних и тех же данных он будет каждый раз давать разные ответы, что обесценивает анализ с научной точки зрения, где главное — воспроизводимость и точность выводов.
Постановка эксперимента
Провести серию экспериментов по тестированию метода "majority vote (Голосование)"
ℹ️Метод majority vote (Голосование): Модель запускается N раз (например, 5 раз) на одних и тех же данных. Ответы записываются. Если 4 из 5 раз нейросеть указала на проблему с вводом-выводом — это, скорее всего, достоверный сигнал. Если голоса разделились поровну — данные требуют более глубокого анализа человеком. Это снижает влияние «случайной ошибки» конкретного прогона.
1. Результат голосования при N=5
На основе анализа пяти отчетов (test1.txt — test5.txt) с применением метода «majority vote» (голосование 5 из 5) сформирован итоговый отчет. Рекомендации ранжированы по частоте упоминаний (от наиболее консенсусных к менее очевидным).
Достоверные рекомендации по оптимизации производительности
Ниже приведены рекомендации, которые были подтверждены как минимум в 4 из 5 отчетов. Это наиболее надежные выводы, требующие первоочередного внимания.
☑️Оптимизация критического запроса (5 из 5 отчетов)
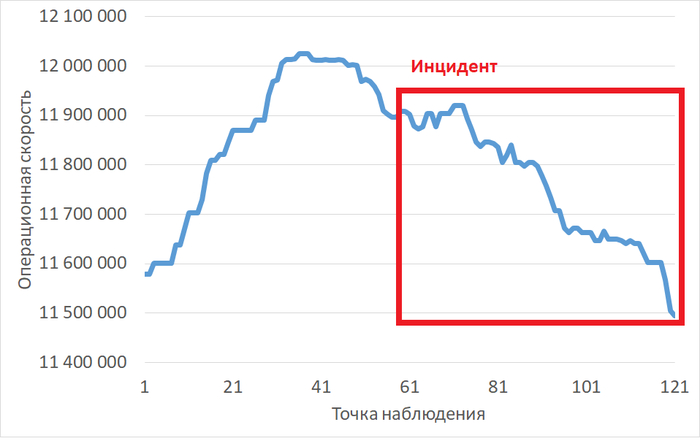
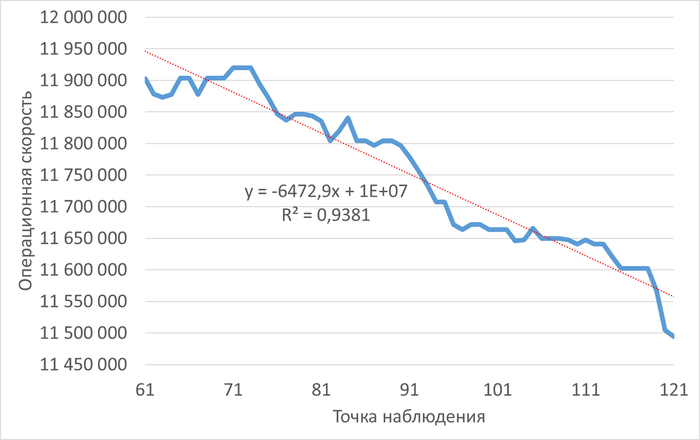
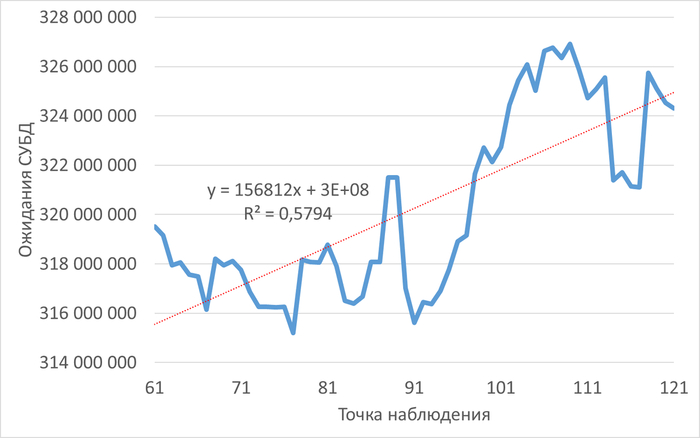
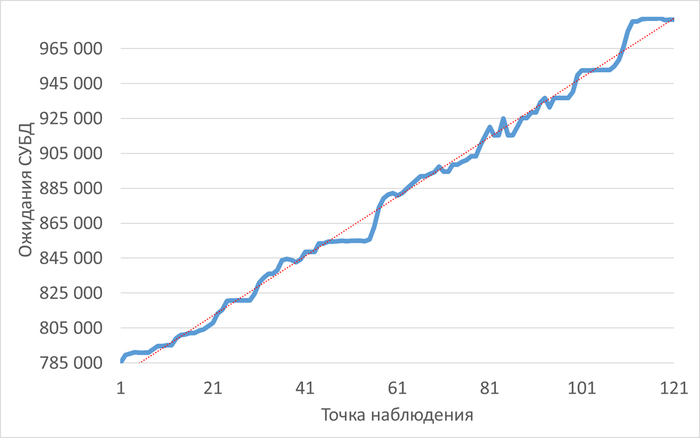
Во всех пяти отчетах однозначно идентифицирован главный источник проблем производительности — выполнение хранимой процедуры/функции scenario1() (идентификатор запроса -2753873076014177353). На него приходится более 85% всех ожиданий ввода-вывода.
Рекомендация: Провести немедленный и детальный разбор плана выполнения этого запроса с помощью EXPLAIN (ANALYZE, BUFFERS). Цель — выявить причины огромного количества чтений с диска (операции DataFileRead), проверить эффективность индексов (отсутствие Seq Scan) и логику самой функции для снижения числа читаемых блоков.
☑️Настройка параметров виртуальной памяти ядра (vm.dirty_*) (5 из 5 отчетов)
Высокие или неоптимальные значения порогов «грязных» страниц (vm.dirty_background_ratio / vm.dirty_ratio) напрямую коррелируют с ростом процессов в состоянии b (непрерываемый сон, ожидание IO) и пиковыми нагрузками на запись. Это усугубляет дисковый bottleneck.
Рекомендация: Снизить пороги для более раннего и плавного сброса данных на диск. Консенсусные значения (в разных отчетах варьируются):
vm.dirty_background_ratio рекомендуется уменьшить до 2-3% (было 5-10%).
vm.dirty_ratio рекомендуется уменьшить до 8-10% (было 15-30%).
Действие: Внести изменения в /etc/sysctl.conf и применить их.
☑️Анализ и апгрейд дисковой подсистемы (I/O Subsystem) (5 из 5 отчетов)
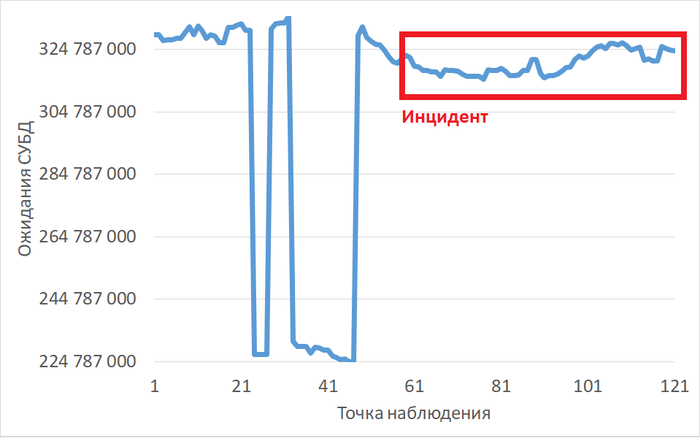
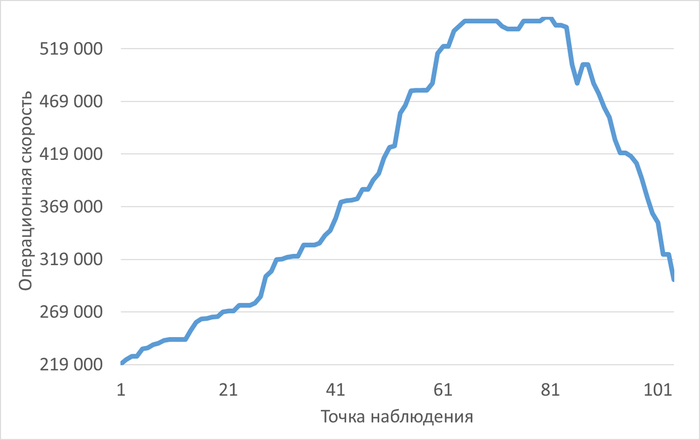
Метрики procs -> b (процессы в ожидании IO) и cpu -> wa (iowait) стабильно высоки (более 10% в 100% времени). Это явный признак того, что дисковая подсистема является узким местом, несмотря на наличие отдельных томов для WAL и данных.
Рекомендация:
Провести стресс-тестирование дисков с помощью iostat -x 1, fio или pg_test_fsync для определения реальной задержки (await), утилизации (%util) и количества IOPS.
Убедиться, что диски vdd (данные) и vdc (WAL) являются физически разными и быстрыми (NVMe с гарантированной производительностью), а не общим виртуальным хранилищем с ограничениями.
☑️Увеличение оперативной памяти (RAM) (5 из 5 отчетов)
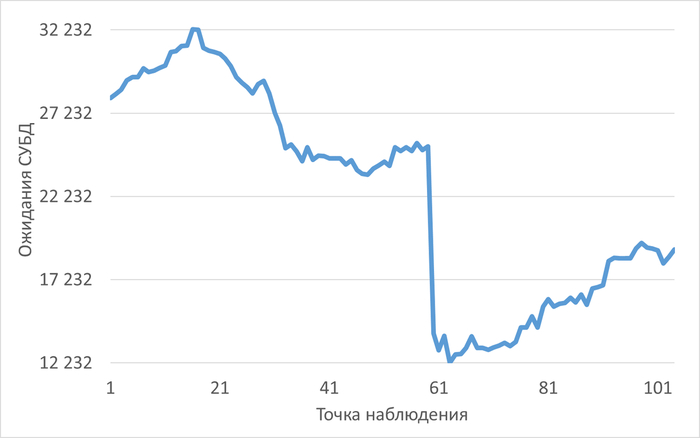
Во всех отчетах зафиксирован критический сигнал тревоги: уровень свободной оперативной памяти постоянно ниже 5% от общего объема (7.5 ГБ). Это создает сильное давление на память, вытесняет кэш страниц ОС и увеличивает нагрузку на диск.
Рекомендация: Увеличить объем ОЗУ сервера как минимум до 16 ГБ (в идеале до 32 ГБ). Это наиболее эффективная долгосрочная мера для расширения кэширования данных и снижения количества обращений к диску.
☑️Настройка контрольных точек (Checkpoint) и WAL (5 из 5 отчетов)
Текущий размер WAL (max_wal_size = 4 ГБ) может быть недостаточным, что приводит к частым контрольным точкам и пиковым нагрузкам на запись.
Рекомендация: Увеличить max_wal_size до 8-16 ГБ (или даже 32 ГБ), чтобы сгладить нагрузку на диск и уменьшить частоту синхронных записей во время контрольных точек. Включить log_checkpoints = on для мониторинга.
☑️Мониторинг и проактивное обнаружение (4 из 5 отчетов)
Необходимо внедрить систему сбора метрик для раннего выявления подобных инцидентов в будущем.
Рекомендация: Настроить алерты по критическим метрикам: свободная RAM < 5%, iowait (wa) > 10%, количество процессов в состоянии b > количества ядер CPU, размер dirty pages. Регулярно анализировать данные из pg_stat_statements и pg_wait_sampling.
☑️Корректировка shared_buffers (4 из 5 отчетов)
Увеличение shared_buffers до 3 ГБ (во втором эксперименте) дало некоторый прирост, но hit ratio остался на уровне ~97%, что указывает на нехватку памяти для рабочего набора данных.
Рекомендация: Хотя в отчетах есть разночтения (кто-то предлагает еще увеличить, кто-то — уменьшить в пользу кэша ОС), консенсус в том, что текущий размер в 3 ГБ при дефиците общей памяти требует пересмотра. Оптимальным видится увеличение RAM, а затем повторная калибровка shared_buffers до 25-40% от нового объема ОЗУ.
Возможные случайные ошибки
Некоторые рекомендации встретились только в одном или двух отчетах и не получили большинства голосов. Это может быть связано с неверной интерпретацией данных в конкретном прогоне модели.
❌Снижение shared_buffers до 2–2.5 ГБ
Где встретилось: В отчете test4.txt.
Предполагаемая причина ошибки: Эта рекомендация противоречит выводам остальных четырех отчетов, где предлагается либо оставить текущий объем, либо увеличить его. Вероятно, модель в этом прогоне сделала неверный акцент на том, что shared_buffers отнимает память у кэша ОС (page cache), посчитав это первостепенной проблемой. Однако при тотальном дефиците памяти (менее 5% свободной RAM) уменьшение shared_buffers лишь незначительно увеличит кэш ОС, но не решит проблему нехватки памяти в принципе. Корень проблемы — общий объем RAM, а не распределение между кэшами PostgreSQL и ОС.
❌Упоминание LWLock как скрытой проблемы
Где встретилось: В отчете test2.txt.
Предполагаемая причина ошибки: Модель могла придать излишнее значение наличию статистически значимой корреляции (p<0.05) для LWLock, хотя в тексте самого отчета указано, что вклад этих блокировок ничтожно мал ("ВКО <0.01"). В условиях доминирующей проблемы с IO (85% ожиданий), попытка углубиться в микроскопические корреляции LWLock является избыточной и отвлекает от главной цели. Это пример «ложного позитива» при анализе больших данных.
❌Некорректная интерпретация autovacuum_work_mem
Где встретилось: В отчете test4.txt.
Предполагаемая причина ошибки: В отчете test4.txt рекомендуется проверить, достаточно ли autovacuum_work_mem (512 МБ). Однако в условиях жесточайшего дефицита оперативной памяти (менее 5% свободной RAM) любые рассуждения об увеличении памяти для автовакуума выглядят преждевременными и потенциально опасными, так как могут усугубить memory pressure. Проблема с автовакуумом (если она есть) является вторичной по отношению к проблеме нехватки памяти и перегрузки диска. Модель могла ошибочно воспринять штатный параметр как проблемный, не оценив общий контекст нехватки ресурсов.
2. Результат голосования при N=11
Ниже представлен анализ 11 отчетов с использованием метода «majority vote». Рекомендации, упомянутые в 6 и более отчетах (т.е. более чем в половине), считаются достоверным сигналом. Рекомендации, встретившиеся менее 3 раз, отнесены к возможным случайным ошибкам.
Достоверные рекомендации по оптимизации производительности
(отранжировано по частоте упоминаний – от самых частых к менее частым)
☑️Оптимизация проблемного запроса select scenario1() (queryid -2753873076014177353)
Частота: 11 из 11
Суть: Запрос генерирует ~85% всех ожиданий ввода-вывода (DataFileRead). Требуется немедленный разбор с EXPLAIN (ANALYZE, BUFFERS), проверка индексов, рефакторинг или секционирование таблиц.
☑️Настройка параметров виртуальной памяти ядра ОС (vm.dirty_*)
Частота: 11 из 11
Суть: Высокая корреляция размера «грязных» страниц с процессами в состоянии b (ожидание I/O) и записанными блоками (bo). Рекомендуется снижение порогов: vm.dirty_background_ratio до 2–5% и vm.dirty_ratio до 8–15% для более раннего старта фоновой записи и предотвращения блокировок.
☑️Увеличение оперативной памяти (RAM)
Частота: 11 из 11
Суть: Во всех отчетах зафиксирован критический уровень свободной RAM (<5% при 7.5 ГБ). Это вызывает memory pressure, вытеснение кэша страниц ОС и рост дисковой нагрузки. Рекомендуется расширение ОЗУ как минимум до 16–32 ГБ.
☑️Увеличение max_wal_size
Частота: 9 из 11
Суть: Текущий размер (4 ГБ) приводит к частым контрольным точкам и пиковым нагрузкам на запись. Увеличение до 8–16 ГБ (с учетом свободного места на /wal) позволит сгладить нагрузку на дисковую подсистему.
☑️Анализ дисковой подсистемы с помощью iostat
Частота: 9 из 11
Суть: Необходимо провести замеры %util, await, avgqu-sz для устройств /dev/vdd (данные) и /dev/vdc (WAL), чтобы подтвердить, что диск является узким местом, и определить, какое именно устройство не справляется.
☑️Проверка физического разделения дисков для WAL и данных
Частота: 7 из 11
Суть: В конфигурации используется разделение на тома (/wal на vdc, /data на vdd). Рекомендуется убедиться, что эти логические тома находятся на физически разных дисках, а не конкурируют за один и тот же накопитель.
☑️Корректировка shared_buffers
Частота: 7 из 11
Суть: Есть два противоположных мнения (увеличить до 4–4.5 ГБ или уменьшить до 2–2.5 ГБ для экономии места под кэш ОС). Однако сам факт необходимости пересмотра этого параметра на фоне дефицита памяти является достоверным сигналом.
☑️Настройка контрольных точек (checkpoint_completion_target)
Частота: 6 из 11
Суть: Увеличение checkpoint_completion_target с дефолтного 0.5 до 0.9 для растягивания записи "грязных" страниц во времени и сглаживания пиковых нагрузок.
☑️Настройка планировщика ввода-вывода (I/O Scheduler)
Частота: 6 из 11
Суть: Для SSD/NVMe в виртуальной среде (KVM) рекомендуется использовать планировщик none (или noop), чтобы избежать лишних накладных расходов.
☑️Проверка параметров random_page_cost и effective_io_concurrency
Частота: 6 из 11
Суть: Текущие значения (1.1 и 500) соответствуют NVMe. Однако требуется убедиться, что фактическая производительность дисков соответствует этим настройкам (возможно, требуется калибровка с помощью fio).
☑️Мониторинг переключений контекста (cs) и прерываний (in)
Частота: 6 из 11
Суть: Высокая корреляция между cs и in указывает на высокую нагрузку на ядро, вызванную дисковой системой. Рекомендация по анализу perf и настройке affinity для прерываний.
Возможные случайные ошибки
*(рекомендации, встретившиеся в 1-2 отчетах)*
❌Увеличение work_mem до 128 МБ
Где встретилось: Отчет №2.
Вероятная причина ошибки: Недооценка количества одновременных соединений. При max_connections = 239 увеличение work_mem до 128 МБ может привести к тому, что общий объем выделяемой памяти под сортировки/хэши превысит доступную RAM, усугубив проблему нехватки памяти (которая и так критична).
❌Отключение synchronous_commit
Где встретилось: Отчеты №3, №6.
Вероятная причина ошибки: Это рискованная рекомендация, которая может привести к потере данных при сбое. Она уместна только в том случае, если бизнес-требования допускают потерю последних транзакций. В контексте общей проблемы (узкое место диска) это паллиатив, а не лечение, и предлагается без анализа рисков для целостности.
❌Использование материализованных представлений
Где встретилось: Отчет №4.
Вероятная причина ошибки: Предложение использовать материализованные представления без анализа частоты обновления данных. Если данные изменяются часто, поддержка материализованных представлений в актуальном состоянии может создать дополнительную, еще более тяжелую нагрузку на запись.
❌Увеличение autovacuum_max_workers до 8
Где встретилось: Отчет №4.
Вероятная причина ошибки: При 8 ядрах CPU и уже существующей дисковой перегрузке, увеличение числа рабочих процессов автовакуума может усилить конкуренцию за диск и ухудшить ситуацию, а не улучшить ее.
❌Уменьшение max_wal_size для более частых контрольных точек
Где встретилось: Отчеты №8, №9.
Вероятная причина ошибки: Эта рекомендация противоречит основному тренду (увеличение max_wal_size). В условиях высокой нагрузки на запись частые контрольные точки приведут к еще более интенсивной пиковой записи, что противопоказано при перегруженном диске. Вероятно, это результат неверной интерпретации данных.
3. Анализ влияния количества отчетов в голосовании на достоверные рекомендации и случайные ошибки
Сравнительный анализ результатов голосования для N=5 и N=11
Введение
Метод majority vote применялся к двум наборам отчетов: первый включал 5 прогонов модели, второй – 11 прогонов. Цель – оценить, как увеличение числа голосующих отчетов влияет на достоверность итоговых рекомендаций и снижение случайных ошибок. Ниже представлены ключевые наблюдения и выводы.
☑️Достоверные рекомендации (основной консенсус)
При N=5 (порог ≥4 голосов)
Оптимизация проблемного запроса (5/5) – главный источник I/O ожиданий.
Настройка параметров виртуальной памяти ядра (vm.dirty_*) (5/5).
Анализ и апгрейд дисковой подсистемы (5/5).
Увеличение оперативной памяти (5/5).
Настройка контрольных точек и WAL (5/5).
Мониторинг и проактивное обнаружение (4/5).
Корректировка shared_buffers (4/5).
При N=11 (порог ≥6 голосов)
Оптимизация проблемного запроса (11/11).
Настройка vm.dirty_* (11/11).
Увеличение RAM (11/11).
Увеличение max_wal_size (9/11).
Анализ дисковой подсистемы с iostat (9/11).
Проверка физического разделения дисков (7/11).
Корректировка shared_buffers (7/11).
Настройка checkpoint_completion_target (6/11).
Настройка планировщика ввода-вывода (6/11).
Проверка random_page_cost и effective_io_concurrency (6/11).
Мониторинг переключений контекста (6/11).
Сравнение:
Базовый набор проблем (запрос, память, диск, WAL) подтверждается в обоих случаях. Однако при N=11 добавляются более тонкие, но статистически значимые аспекты (планировщик I/O, параметры стоимости, анализ контекстных переключений). Они не набрали бы нужного числа голосов при N=5, но при большем количестве прогонов становятся достоверными сигналами.
❌Возможные случайные ошибки
При N=5 (встретились в 1–2 отчетах)
Снижение shared_buffers до 2–2.5 ГБ – противоречит общему выводу о нехватке памяти.
Упоминание LWLock как скрытой проблемы – ничтожный вклад в ожидания.
Некорректная интерпретация autovacuum_work_mem – преждевременная рекомендация на фоне дефицита RAM.
При N=11 (встретились в 1–2 отчетах)
Увеличение work_mem до 128 МБ – риск перерасхода памяти.
Отключение synchronous_commit – риск потери данных без анализа требований.
Использование материализованных представлений – может усугубить нагрузку на запись.
Увеличение autovacuum_max_workers до 8 – усилит конкуренцию за диск.
Уменьшение max_wal_size для более частых контрольных точек – противоречит основной рекомендации.
Сравнение:
При N=11 список возможных ошибок шире, но все они отвергнуты большинством. Это демонстрирует, что с ростом числа отчетов ложные идеи не набирают критической массы и отсеиваются, тогда как при N=5 некоторые из них могли бы остаться незамеченными просто потому, что не попали в выборку. Важно, что ни одна из ошибок не пересекается с достоверными рекомендациями, что говорит о хорошей фильтрации.
Влияние количества отчетов на достоверность
1️⃣Укрепление доверия к основным выводам
Рекомендации, получившие 5/5 при N=5, при N=11 также имеют максимальную поддержку (11/11). Это подтверждает их фундаментальную важность.
2️⃣Выявление дополнительных значимых факторов
При увеличении выборки становятся заметны проблемы, которые ранее могли быть скрыты шумом или не достигали порога (например, настройка планировщика I/O). Это позволяет получить более полную картину узких мест.
3️⃣Снижение влияния случайных ошибок
Ложные или вредные советы, возникающие в единичных прогонах, не набирают большинства. При N=11 порог (6 голосов) жёстче, чем при N=5 (4 голоса), поэтому фильтрация шума эффективнее. Редкие аномалии остаются в разделе «возможные ошибки» и не попадают в финальные рекомендации.
4️⃣Ранжирование по частоте упоминаний
В N=11 чётко видна градация важности: от абсолютного консенсуса (11/11) до умеренного (6/11). Это помогает расставить приоритеты при внедрении изменений. В N=5 все достоверные рекомендации находятся в узком диапазоне 4–5 голосов, что не позволяет так же тонко дифференцировать их значимость.
Заключение
Увеличение числа отчетов при голосовании повышает надёжность итоговых рекомендаций за счёт:
многократного подтверждения ключевых проблем;
выявления менее очевидных, но систематических факторов;
надёжного отсеивания случайных и потенциально вредных советов.
Метод majority vote с большим N (например, 11) даёт более полную и точную картину, позволяя принимать обоснованные решения по оптимизации производительности. ➡️Рекомендуется использовать не менее 10–11 прогонов для достижения устойчивого консенсуса и минимизации ложноположительных срабатываний.
Послесловие
Проведённое исследование подтвердило эффективность применения метода «majority vote» для нивелирования недетерминированности выводов нейросетевой модели при анализе производительности СУБД PostgreSQL. Увеличение числа независимых прогонов с пяти до одиннадцати позволило не только многократно верифицировать ключевые проблемы (дефицит оперативной памяти, перегрузка дисковой подсистемы, неоптимальные параметры ядра и контрольных точек), но и выявить статистически значимые, хотя и менее очевидные факторы, такие как необходимость тонкой настройки планировщика ввода-вывода и параметров стоимостных оценок. Одновременно с этим расширение выборки обеспечило надёжное отсеивание ложноположительных и потенциально вредных рекомендаций, которые возникали в единичных отчётах, что подтверждает высокую фильтрующую способность метода при достаточном объёме голосующих экземпляров.
Полученные результаты непосредственно влияют на развитие методики анализа производительности, реализованной в комплексе pg_expecto. Обоснована целесообразность включения в стандартный сценарий использования комплекса требования о многократном (не менее 10–11 повторений) запуске модели с последующим автоматизированным голосованием. Это позволяет повысить достоверность итогового заключения, ввести объективное ранжирование рекомендаций по частоте упоминаний и минимизировать риск принятия ошибочных решений при оптимизации.