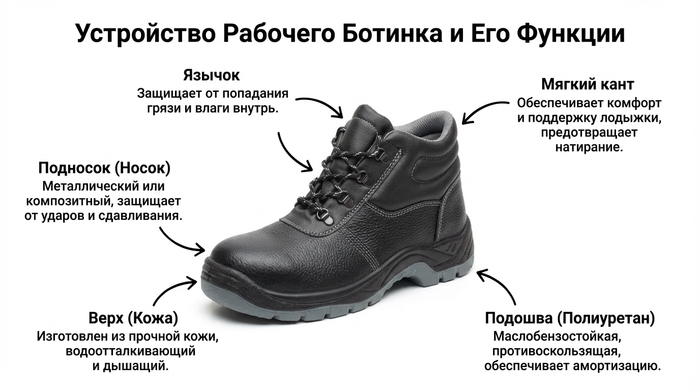
Подбор товаров для тендера с помощью искусственного интеллекта
Любой тендерный специалист знает, что процесс обработки технических заданий (ТЗ) из тендерной документации требует значительных затрат времени. Специалисту необходимо изучить длинный перечень требований, выделить ключевые технические характеристики и найти соответствующие позиции среди тысяч строк в своем каталоге или в десятках каталогах различных поставщиков. А что если вы новый человек в специфике? А что если много данных и к тому же они специфичны?
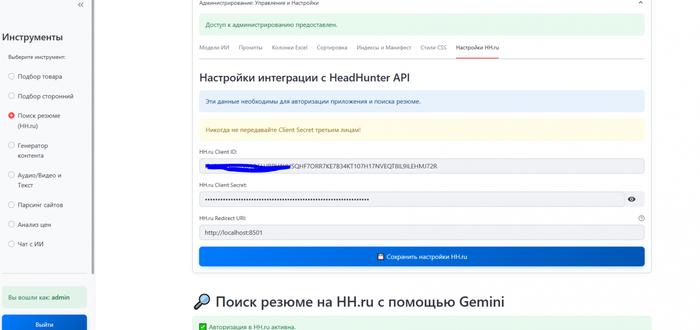
Для решения этой задачи я разработал специализированный инструмент Rybakov Studio AI, которая в данный момент не представлен в публичном доступе и не имеет прямых аналогов на массовом рынке. Система использует локальные базы данных пользователя, алгоритмы обработки естественного языка и большие языковые модели (LLM) для автоматизации процесса сопоставления.
Центральным элементом системы является модуль интеллектуального поиска. Далее постараюсь объяснить что и как работает.
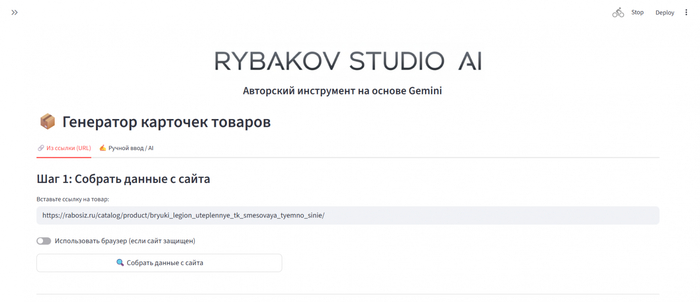
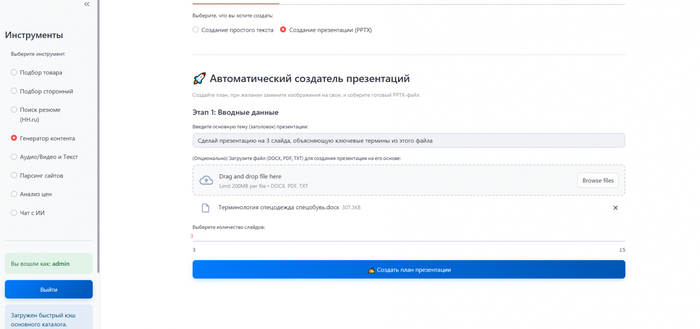
1. Откуда брать данные?
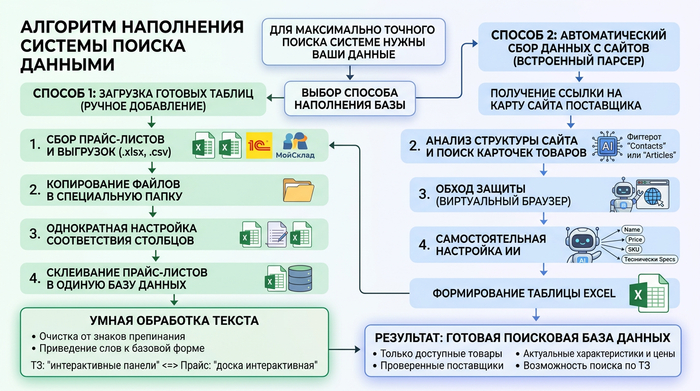
Для того чтобы поиск был точным входящие данные также должны быть хорошо структурированы.
Наполнить систему информацией можно двумя способами.
Загрузка готовых таблиц (Excel, CSV, 1С)
Это основной метод работы с данными дистрибьюторов или данными из собственных учетных систем. Собственно тут все просто, данные выгрузили согласно нужных данных из учетной системы, положили в нужную директорию — ВСЁ!
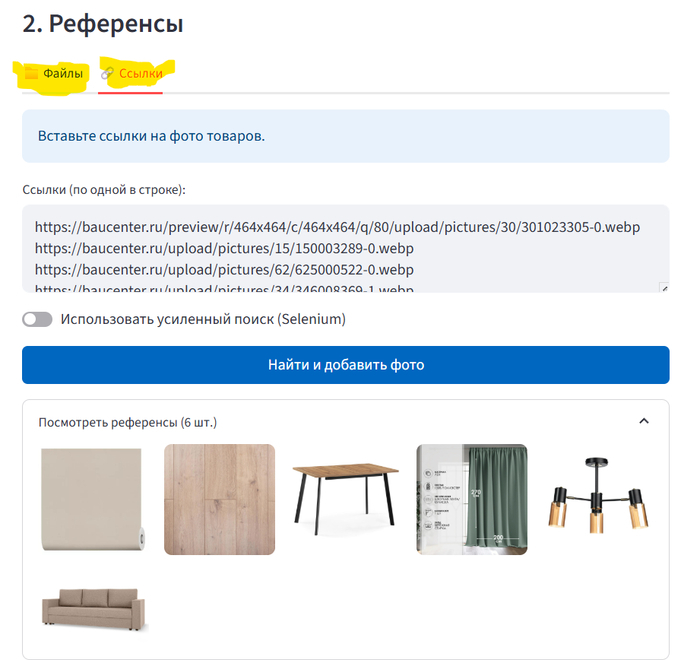
Автоматический сбор с сайтов (Встроенный парсер)
Если у производителя нет прайс-листа в Excel, а товары представлены только в каталоге на сайте? Для этого предусмотрен дополнительный инструмент парсинга. Как работает данный механизм:
Умный отбор: Вы даете ссылку на сайт, а Искусственный Интеллект сам находит карточки товаров, игнорируя лишнюю информацию (новости, контакты, условия доставки).
Обход ограничений: Система имитирует действия реального пользователя (через виртуальный браузер), что позволяет собирать данные даже с защищенных сайтов.
Настройка без программиста: ИИ самостоятельно понимает структуру страницы: где находится цена, где описание, а где технические характеристики.
Итог: Вся собранная с сайта информация превращается в стандартную таблицу Excel, которую система сразу начинает использовать для поиска и подбора оборудования под ваши задачи.
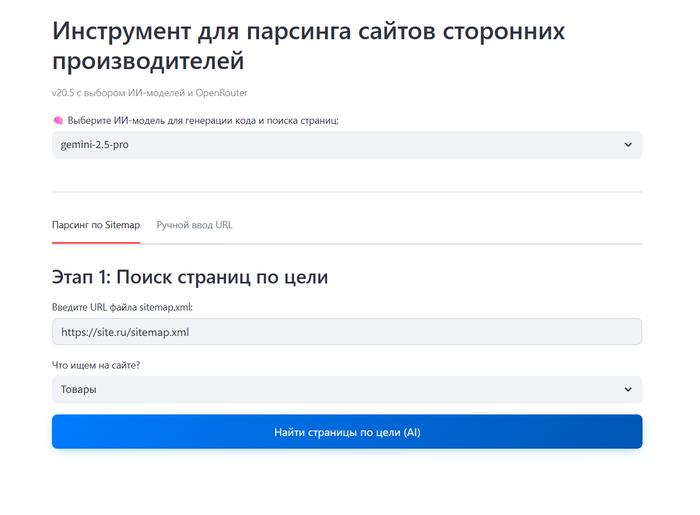
Интерфейс парсера
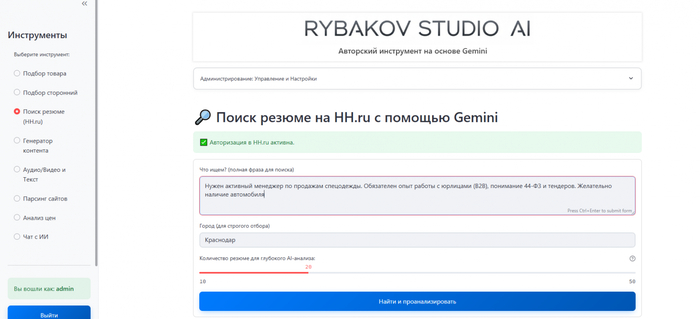
2. Модуль поиска (Инструмент «Подбор по ТЗ»): режимы работы
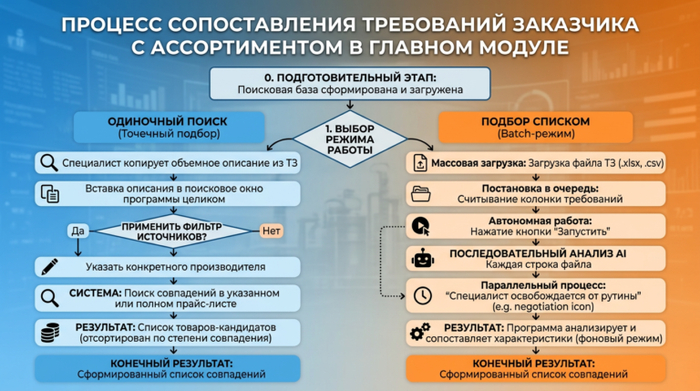
После того как поисковая база сформирована и загружена, начинается основной этап работы — сопоставление требований заказчика с вашим доступным ассортиментом. Этот процесс происходит в главном модуле и функционально подходит для любых товарных ниш.
Чтобы инструмент был удобен как для быстрой проверки пары позиций, так и для просчета огромных спецификаций, он разделен на два режима работы.
Одиночный поиск (Точечный подбор)
Этот режим идеально подходит для сложных, нестандартных или единичных запросов. Часто в тендерной документации описание всего одного товара занимает целый абзац: в нем перемешаны габариты, материалы, ссылки на ГОСТы и различные допуски.
Как строится работа в этом режиме:
Специалисту больше не нужно вручную вычленять главные слова из этого текста, чтобы вбить их в обычный поиск. Он просто копирует весь объемный абзац из ТЗ (технического задания) и вставляет его в поисковое окно программы целиком.
Для повышения точности предусмотрен фильтр источников. Например, если по характеру описания вы понимаете, что заказчик прописал спецификацию под конкретный завод, вы можете указать программе искать совпадения только в прайс-листе этого производителя, полностью игнорируя остальную базу. В результате система выдаст короткий список из наиболее подходящих товаров-кандидатов, отсортированных по степени совпадения характеристик.
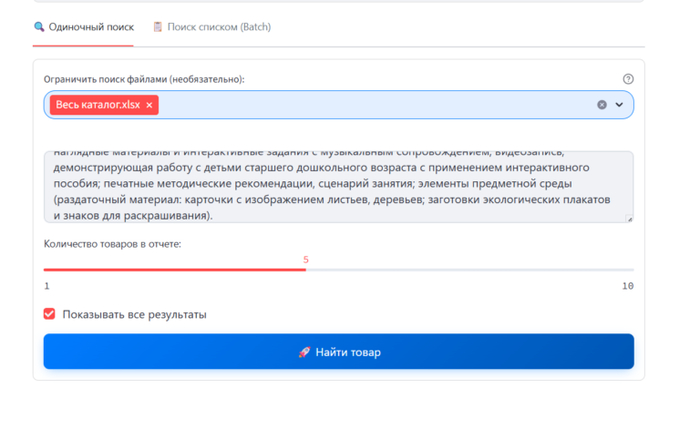
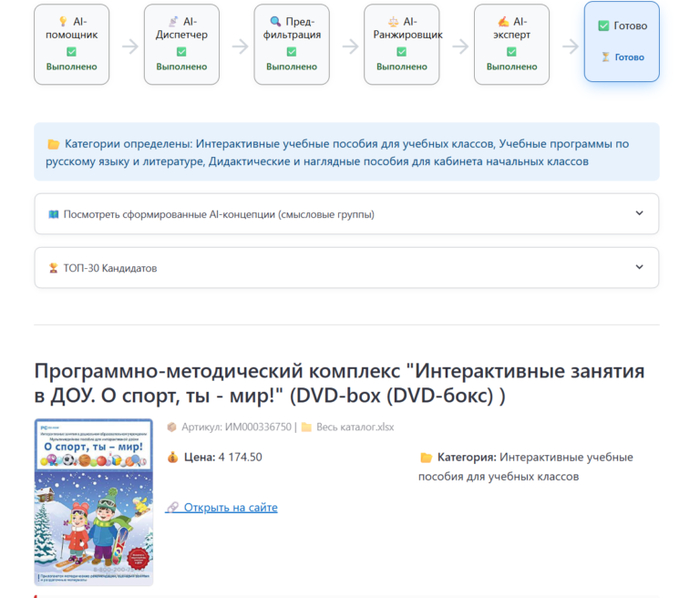
Интерфейс инструмента одиночного подбора
Подбор списком (Batch-режим)
Это основной, самый востребованный сценарий работы для специалистов по тендерам и закупкам. Режим разработан специально для ситуаций, когда спецификация состоит из десятков или сотен строк.
Главная проблема при работе с большими ТЗ — это необходимость брать каждую строчку, копировать ее, переходить в Excel-прайсы, искать совпадения, анализировать их и заносить результат обратно в свою смету. Эта монотонная механическая работа отнимает рабочие дни и сильно подвержена ошибкам из-за человеческого фактора (усталости, потери концентрации).
Режим «Подбор списком» забирает эту рутину на себя:
Массовая загрузка: Вы просто загружаете в программу готовый файл с техническим заданием (в формате .xlsx или .csv).
Постановка в очередь: Программа автоматически считывает колонку, в которой содержатся требования к товарам, и выстраивает все запросы в очередь на обработку.
Автономная работа: После нажатия кнопки «Запустить» система начинает последовательно применять алгоритмы искусственного интеллекта к каждой строке из вашего файла. Процесс идет полностью в фоновом режиме, без какого-либо участия человека.
В среднем на глубокий машинный анализ, перебор базы и поиск одной сложной позиции у системы уходит около одной минуты. Главное преимущество здесь заключается в автономности: пока программа самостоятельно анализирует сотни строк спецификации и сопоставляет характеристики, специалист освобождается от рутины и может заниматься переговорами, подготовкой документов или другими высокоприоритетными задачами.
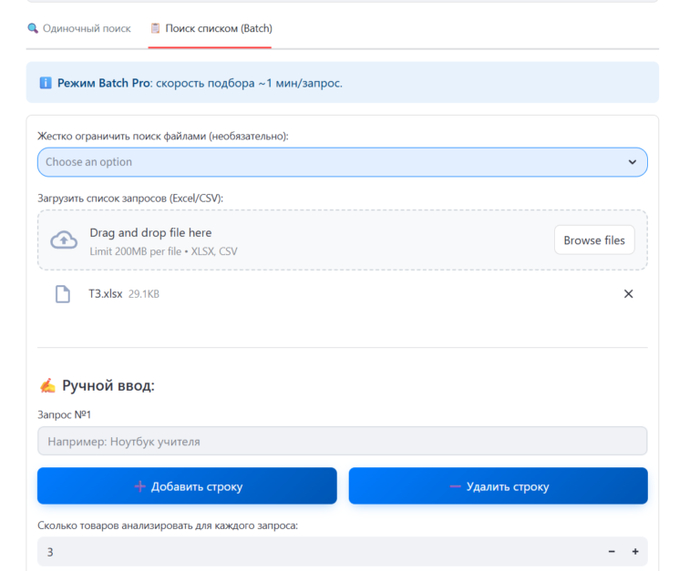
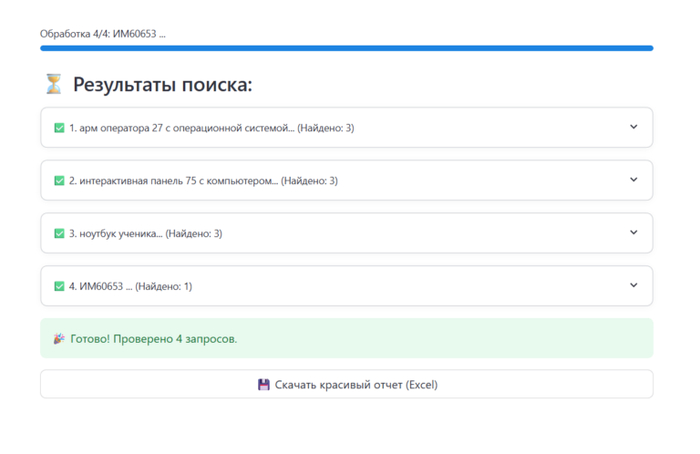
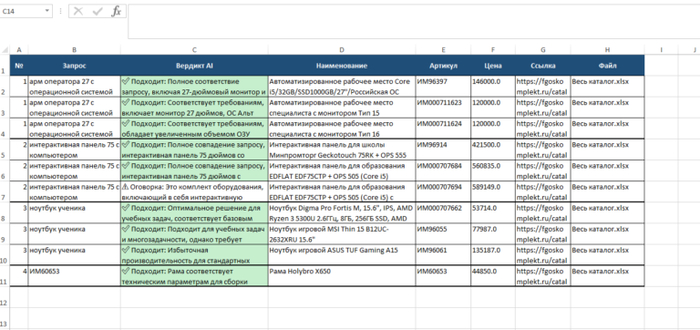
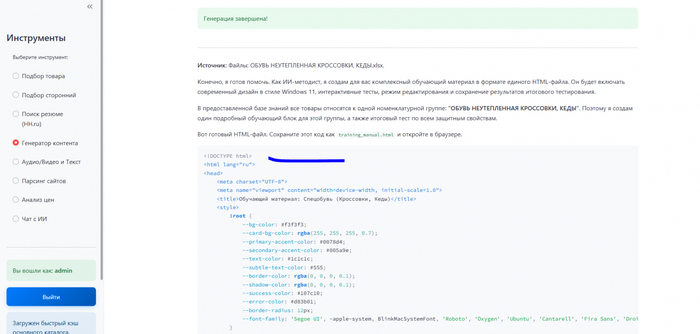
Пример результатов подбора
3. Как работает поиск «под капотом»
Высокая точность подбора достигается за счет многоступенчатого конвейера обработки данных (Pipeline), который комбинирует математические алгоритмы и искусственный интеллект.
AI-Диспетчер (Выбор категории): Модель анализирует запрос и сопоставляет его с существующими категориями в базе. Если ищется «микроскоп», диспетчер отсекает прайс-листы с мебелью и оставляет файлы с лабораторным оборудованием.
AI-Помощник (Извлечение смыслов): Запрос из ТЗ редко совпадает с названием товара напрямую. ИИ разбивает длинный текст на «смысловые группы» (например, группа 1: «ноутбук, лэптоп», группа 2: «15 дюймов», группа 3: «intel core»).
Математический скоринг: Программа сканирует лемматизированную базу данных. Товар получает баллы в зависимости от того, где найдено совпадение. Точное совпадение по артикулу дает максимальный балл. Совпадение смысловой группы в начале заголовка оценивается выше, чем совпадение в конце технического описания.
AI-Ранжировщик: Математика отбирает топ-20 кандидатов. Затем языковая модель анализирует этот короткий список на логику. Например, ИИ обучен применять правило «Анти-комплект»: если в ТЗ требуется одна позиция (стол), а математика нашла товар «Комплект мебели: стол и 4 стула», ИИ принудительно опустит этот результат вниз списка.
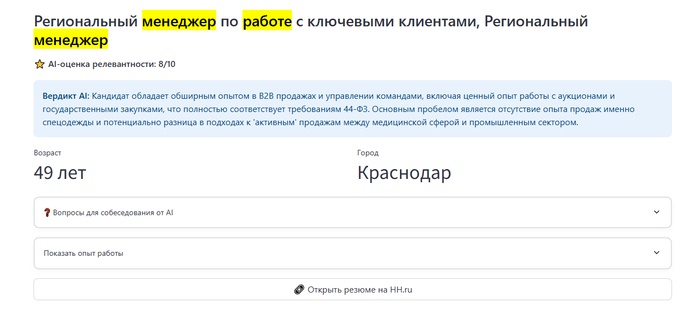
AI-Эксперт (Формирование отчета): Для финальных результатов (например, топ-3 позиции) ИИ пишет аналитическое заключение. Он сравнивает текст исходного ТЗ с описанием найденного товара и формирует вердикт.
4. Какой результат получает пользователь: форматы отчетов и их применение
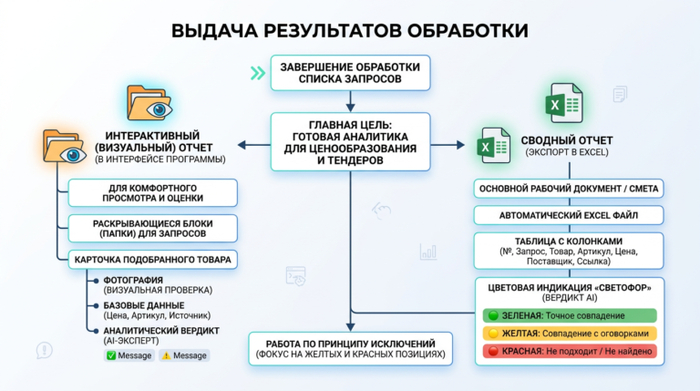
Когда система завершает обработку списка запросов, она не выдает просто набор «сырых» ссылок. Главная цель инструмента — предоставить специалисту готовую аналитику, на основе которой можно сразу принимать решения о ценообразовании и участии в тендере.
Для удобства работы результаты формируются в двух взаимодополняющих форматах: для быстрой визуальной проверки и для дальнейших финансовых расчетов.
Интерактивный (визуальный) отчет в интерфейсе программы
Этот формат предназначен для комфортного просмотра и оценки предложенных вариантов прямо в окне приложения.
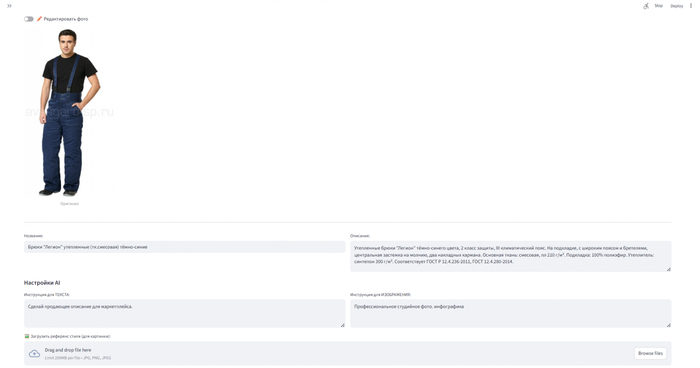
Вместо сплошного текста пользователь видит структурированную ленту. Каждая строчка из исходного технического задания превращается в отдельный раскрывающийся блок (папку).
Внутри такого блока система показывает от одного до нескольких наиболее подходящих товаров. Как выглядит карточка подобранного товара:
Фотография: Если в загруженных прайс-листах или на спарсенном сайте была ссылка на изображение, программа автоматически подтянет и покажет фото товара. Это позволяет визуально убедиться в правильности выбора.
Базовые данные: Сразу отображаются цена, артикул и название файла-источника (чтобы специалист сразу понимал, какому поставщику принадлежит этот товар).
Аналитический вердикт (AI-Эксперт): Это ключевая функция системы. Программа не просто ставит два товара рядом, она пишет краткое объяснение. Например: « Подходит: характеристики процессора и диагональ экрана полностью совпадают с запросом» или « Оговорка: запрошен стол из дерева, а найденный вариант выполнен из ЛДСП». Благодаря этому специалисту не нужно открывать карточку товара и вчитываться в мелкий шрифт технических характеристик — нейросеть уже провела сравнение.
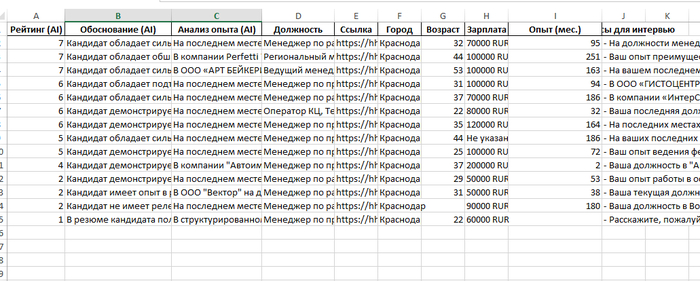
Сводный отчет (экспорт в Excel)
Визуальный интерфейс удобен для проверки, но основным рабочим документом тендерного специалиста или снабженца является смета. Поэтому итоговым продуктом работы программы выступает автоматически сгенерированный файл Excel.
Это готовая сводная таблица, в которой собрана вся необходимая информация для просчета экономики проекта. В файле содержатся следующие колонки:
Номер по порядку и исходный текст запроса.
Наименование подобранного товара и его артикул.
Актуальная цена из базы.
Название прайс-листа (поставщика).
Ссылка на сайт (если есть).
Умная цветовая индикация (Светофор):
Самая важная колонка в этом Excel-файле — «Вердикт AI». Чтобы максимально сэкономить время человека, система автоматически раскрашивает ячейки с результатами:
Зеленая заливка (Точное совпадение): ИИ уверен, что найденный товар полностью отвечает требованиям ТЗ. Специалист может практически не тратить время на проверку этих строк и сразу брать предложенные цены в расчет рентабельности.
Желтая заливка (Совпадение с оговорками): Система нашла аналог, но он имеет незначительные технические расхождения. Внимание специалиста должно быть сфокусировано именно на этих строках: человеку нужно прочитать вердикт и решить, допустимо ли предложить такой аналог заказчику.
Красная заливка (Не подходит / Не найдено): Программа честно сигнализирует, что в загруженных базах поставщиков нет подходящего товара (например, ищут трактор, а в базе только запчасти).
Такой подход позволяет специалисту не проверять сотни строк вручную, а работать по принципу исключений, фокусируя свое внимание только на проблемных (желтых и красных) позициях таблицы.
5. Решаемые задачи и сценарии применения
Инструмент закрывает несколько ключевых потребностей в сфере закупок, снабжения и оптовых продаж:
Первичный просчет тендера: Специалисту необходимо понять общую маржинальность ТЗ. Загрузка спецификации в систему позволяет за час получить ориентировочные цены и артикулы от своих поставщиков на спецификацию из 50-70 пунктов.
Импортозамещение и подбор аналогов: Когда в ТЗ указан конкретный бренд или товар, ушедший с рынка, система, опираясь на технические характеристики, находит аналогичные товары из доступных баз данных. Вердикт AI-Эксперта сразу указывает, в чем найденный аналог совпадает, а в чем уступает оригиналу.
Мониторинг ассортимента конкурентов: Загрузив прайс-лист с описанием товара конкурента в качестве базы, пользователь может прогнать через систему свои топовые товары и получить сводную таблицу аналогов конкурента с сопоставлением характеристик.
Заключение: объективные преимущества использования
Человек, интегрирующий данный инструмент в свои рабочие процессы, получает измеримые результаты. Главное преимущество — колоссальная экономия времени на рутинной механической работе. Задачи, требовавшие использования поиска «Ctrl+F» по десяткам вкладок Excel в течение нескольких рабочих дней, делегируются вычислительным мощностям.
Оригинал статьи