
0 просмотренных постов скрыто




MINI DV на внешний диск
Здравствуйте, дорогие друзья!
Я прошу помощи у сообщества, которое всё знает и всё умеет.
Если о себе - я далёк от программирования и прочих it заморочек; максимум, что я сумел в своей жизни сделать интуитивно - установил что-то с рутрекера…
А помощь нужна вот в чём: есть видеокамера sony , которая работает до сих пор, есть кассеты mini dv, на которых многое из жизни нашей семьи записано, и есть желание перенести видео с кассет на флэшку или внешний диск.
Если есть возможность - пришлите ссылку на инструкцию, по возможности для таких чайников, как я.
Профессионалы просят от 9 до 15 рублей за минуту, не то, чтобы жалко, просто их нет.
Гугл рекомендует купить кабель Кабель FireWire IEEE-1394 и возможно ПО какое-то установить.
Заранее спасибо!

Показать полностью
1

Вышла новая модель для оцифровки изображений GLM-OCR
Обнародована модель GLM-OCR (https://huggingface.co/zai-org/GLM-OCR) для понимания документов на базе архитектуры GLM-V.
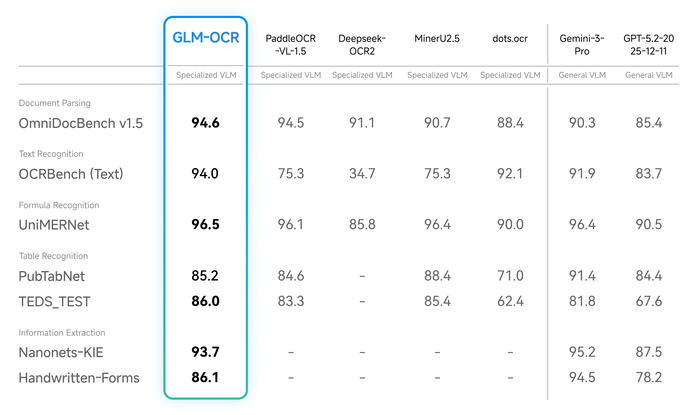
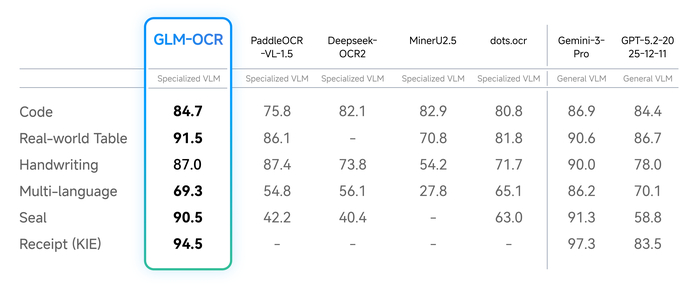
У неё лучшая точность, дающая ей №1 в OmniDocBench (94.62), а также лидерство в распознавании текста, формул и таблиц. Она универсальна, хорошо показывая себя на сложных макетах (таблицы, код, печати, рукопись). По эффективности всё тоже хорошо, так как модель имеет всего 0.9B параметров и обладает быстрым выводом через vLLM/Ollama.
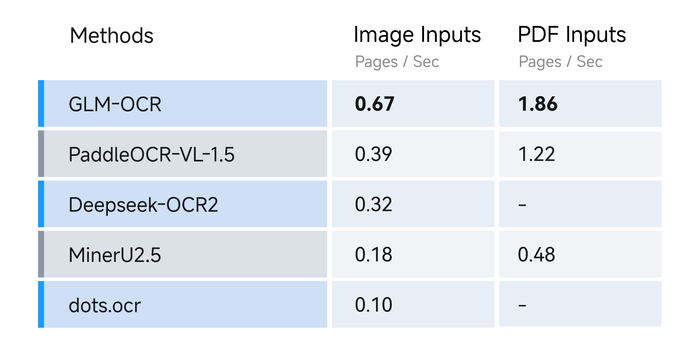
В результате, используя эту модель, мы получаем точность 94.6 в OmniDocBench, 94.0 в OCRBench для текста и 96.5 в UniMERNet для формул, а на сложных сценариях оценки доходят до 84.7 для кода, 91.5 для реальных таблиц и 90.5 для печатей. Скорость анализа PDF составляет 1.86 стр/с, а изображений 0.67 изобр/с, что быстрее аналогов.
Показать полностью
2


Мойдодыр (1927)
Мойдодыр — советский кукольный мультфильм 1927 года, созданный на студии «Межрабпом-Русь» по одноимённой сказке Корнея Ивановича Чуковского. Считался утраченным до 2007 года, когда Народный чешский Киноархив обнаружил у себя плёнку с мультфильмом и поделился ей с Госфильмофондом Российской Федерации, после чего в 2008 году мультфильм показали на кинофестивале «Белые Столбы». С 2023 года в сети были доступны только кадры из мультфильма и 20-секундный отрывок.
Оцифровка 20-секундного фрагмента (плëнки 17 м) была оплачена участницей Елизаветой Осиповой в 2023 году .
Мультфильм считается одним из первых советских объёмных (кукольных) мультфильмов, а также самой первой экранизацией одноимëнной сказки, однако точная дата его выхода на экраны неизвестна. Мультфильм был снят на плёнку 35-мм и является чёрно-белым, и немым. В Госфильмофонде Российской Федерации хранится на двух плёнках — немой (17 м) и с чешскими интертитрами (217 м). Полная ориентировочная продолжительность мультфильма составляет 8 минут (по каталогу фестиваля — 9 минут). У плёнки с чешскими интертитрами не сохранилось около полуторы минуты (217/250 м). В качестве режиссёра–кукловода выступила Мария Бендерская, а оператором и художником-постановщиком выступил Самуил Бендерский.
В декабре 2025 года участником Oleznik Omeznik в Госфильмофонд Российской Федерации было подано заявление на оцифровку плёнки с максимально сохранившимся мультфильмом (с чешскими интертитрами). Ближе к концу января 2026 года мультфильм был полностью оцифрован и получен участником из архива Госфильмофонда. Публикация мультфильма была разрешена, поскольку он перешёл в общественное достояние.
Показать полностью

Как закачивать футбольные трансляции на Ютупъ
Это вопрос.
[БРА - ГЕР 2014 Полуфинал]
Короче есть у меня несколько старых, оцифрованных мною же видосов с Вэхаэски.
А этот подлый Ютуб не пускает их в себя. Грит мол "авторские права"
Но тут же рядом на чужих каналах (не на оф.канале Фифы) - есть несколько видео этого же матча. На польском пожалуйста. На русском (картинка приближена зумом) - тоже есть.
Переозвученная нарезка под другую музыку (это важно) - в наличии. Я уже не говорю про переигровку матча на плойке в игре.
ЧатГопота меньжуется, и темнит. Единственно что грит, это то что сейчас футбольные матчи ещё строже чем голливудские фильмы. Хотя опять же, "Вспомнить всё" со Шварцем есть, а Робокопа оригинального - нету.
Так как? А то не хочется класть свои оцифровки на полку.
Показать полностью
Вышла новая модель для оцифровки изображений DeepSeek-OCR-2
Загружена модель DeepSeek-OCR 2 (https://huggingface.co/deepseek-ai/DeepSeek-OCR-2) с новой архитектурой визуального кодировщика.
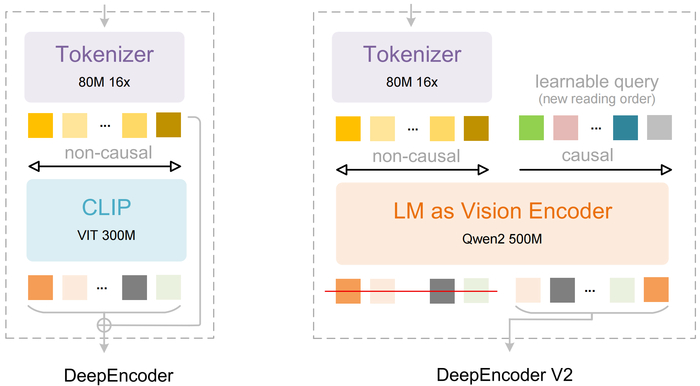
Главная идея разработки состоит в том, что традиционные модели обрабатывают изображение строго по порядку пикселей (слева направо, сверху вниз), что противоречит человеческому восприятию, где взгляд движется по смысловым связям.
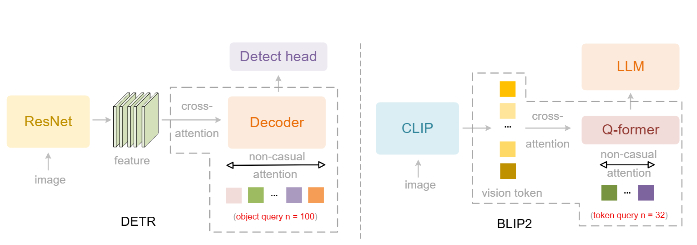
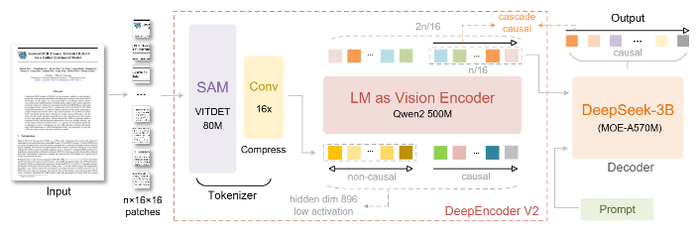
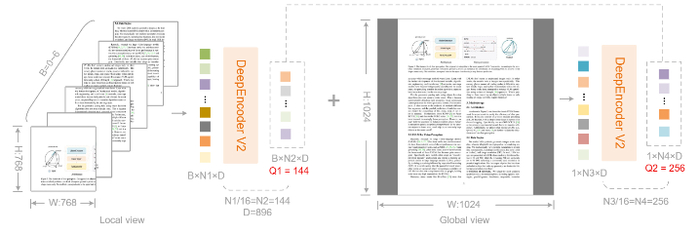
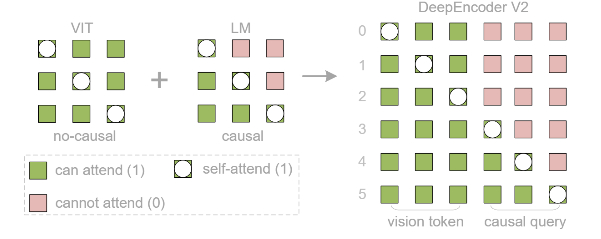
Для решения этой проблемы создан DeepEncoder V2, заменяющий стандартный визуальный кодировщик (CLIP) на архитектуру, похожую на языковую модель (LLM). Он использует "причинно-следственные" обучаемые запросы, которые динамически переупорядочивают визуальные токены на основе семантики изображения, прежде чем передать их в LLM. Кроме того, применяется реализация через комбинированную маску внимания, которая сочетает двунаправленность для визуальных токенов (как в ViT) с причинно-следственной логикой для запросов (как в декодере LLM).
В результате модель имитирует логичный, "причинный" поток человеческого визуального восприятия, особенно для документов со сложной структурой (текст, формулы, таблицы).
Модель сохраняет высокую степень сжатия визуальных токенов (256-1120 на изображение), а на тесте OmniDocBench показывает прирост +3.73% по сравнению с предыдущей версией (DeepSeek-OCR) за счёт лучшего определения порядка чтения.
Показать полностью
4


Старые фотографии - моя мама - 2

шестидесятые... не вспомню точно.

Моя Мама - детское фото 60-ые...

Где-то в Псковской области... (п. Щукино)