
0 просмотренных постов скрыто


4 матерных корня и 5000 словоформ. Как я писал сервис для цензуры русского мата1
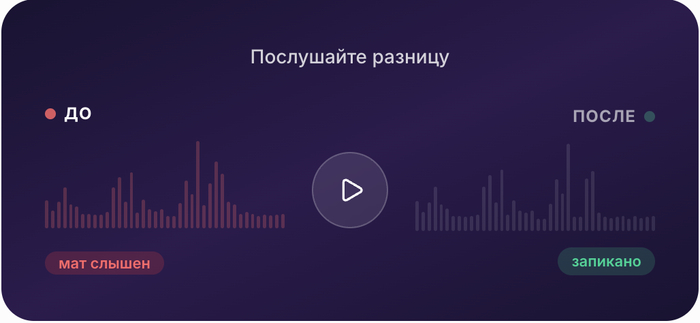
Мне скидывают видосы. Смешные, но мат через слово. Ни показать никому, ни выложить.
Ок, думаю, запикаю руками. Открыл CapCut. Слушаю, пауза, отмотал назад, нашёл где начинается слово, вырезал, бип, подогнал. Одно слово. Следующее. Ещё. И вот то, которое пропустил, потому что тихо.
Двухминутный ролик. Двадцать минут ковыряния.
2024 год. Нейросети генерят видео, пишут код — а я на таймлайне ищу, где человек сказал «бл***».
Мысль сделать сервис для этого была давно. Но я фронтендер. Каждый раз думал «надо бы» и переключался на что-нибудь попроще, потому что даже не представлял, с какой стороны к этому подойти.
А потом наступили новогодние каникулы
Все отдыхают, я сижу с ноутбуком. Решил — ладно, попробую, хуже не будет. За неделю собрал MVP. Кривой, половина кейсов падала, но базовый сценарий работал: кидаешь файл, оно распознаёт речь, находит мат, вставляет бипы.
Первый раз прогнал через него тот самый видос и в нужном месте услышал бип вместо мата. Знаете это чувство, когда что-то, что ты написал, впервые реально работает? Вот это оно.
Дальше, конечно, выяснилось, что от MVP до чего-то рабочего — пропасть. Но процесс затянул.
Про русский мат
Это самая интересная техническая часть, я не ожидал.
Первая мысль была — ну, захардкожу список матерных слов, буду проверять каждое распознанное слово. Делов-то.
Ага.
В русском языке 4 матерных корня. Четыре. А словоформ от них — больше 5000. Берём один корень из трёх букв: х**вый, х**ня, ох**ть, прих**чить, зах**чить, однох**ственно... Каждое ещё склоняется по падежам, родам, числам. И люди постоянно придумывают новые.
Список не спасает. RegEx тоже — или пропускаешь, или ловишь ложные срабатывания.
Пришлось делать нормальный морфологический анализ: каждое слово раскладывается до корня, корень проверяется по базе. Это ловит вообще любую форму, даже выдуманную на ходу.
Кстати, я пока разбирался в этом, узнал про русский мат больше, чем за всю предыдущую жизнь. Прямо целое исследование провёл.
Нейросеть, которая ругается сама
Отдельный прикол — галлюцинации. Нейросеть распознаёт речь и периодически «слышит» слова, которых в аудио не было. И почему-то часто — именно нецензурные.
В записи тишина. В транскрипте — слово из трёх букв. Откуда? Непонятно.
Пришлось писать детектор галлюцинаций. Код, который проверяет, не выдумывает ли нейросеть ругательства. Я когда это делал, сам не мог поверить, что это реальная задача, которую надо решать.
Баги, которые запомнились
Их было много, но вот те, от которых я прям сидел и не понимал, что происходит.
Однажды кто-то загрузил длинный файл, где мата было очень много. FFmpeg-команда для вставки всех бипов стала настолько длинной, что операционная система отказалась её запускать. Ошибка E2BIG — «argument list too long». Я не знал, что у ОС вообще есть такой лимит.
Ещё: когда заглушаешь кусок аудио, на стыке слышен щелчок. Резкий обрыв волны. Надо делать плавное затухание. Казалось бы, элементарная вещь — но я подбирал параметры fade несколько дней, прежде чем перестало щёлкать.
Вертикальные видео роняли сервер. OOM. Оказалось, портретные ролики при обработке жрут кратно больше памяти. Отдельно спасибо всем, кто снимает вертикально.
Ну и классика: обработанное видео не играло в Firefox. Два дня дебага. Причина — цветовое пространство YUV444 вместо YUV420. До этого проекта я не знал, что такое «цветовое пространство видео». Теперь знаю. Мог бы и не знать.
Что вышло в итоге
Сервис, который делает за полминуты то, на что у меня уходило двадцать минут. Загружаешь файл, получаешь версию без мата. Есть режим для песен — нейросеть отделяет вокал от музыки, потом анализирует текст. Можно кинуть ссылку на YouTube вместо файла.
Кто этим пользуется
Думал, буду я один. Кинул друзьям, те — своим.
Больше всего пользуются нарезчики — люди, которые клипуют моменты из стримов и интервью. У них поток: десятки коротких нарезок, в каждой мат, вручную обрабатывать нереально.
Самый неожиданный кейс — суды. Мне в телеграм-чат несколько раз писали, что используют сервис для подготовки аудиозаписей к судебным заседаниям. Есть запись разговора, её нужно приобщить к делу, а там мат. Я даже не думал, что такая проблема существует.
Ну и люди, которые просто хотят чистую версию песни или видоса для себя. С этого всё и начиналось.
Про «я же фронт»
Оглядываясь назад — самым сложным было начать. Не Docker, не FFmpeg, не нейросети. А сесть и написать первую строчку бэкенда, когда до этого всю карьеру писал фронт.
Потом оказалось, что разбираться по ходу — нормально. Больно, но нормально. Гуглишь, ломаешь, чинишь, опять ломаешь. За этот проект я узнал столько, сколько не узнал бы за годы работы в зоне комфорта.
И ещё одна штука, которая удивила: для русского языка инструментов нет. Вообще. Для английского — SaaS на любой чих. А на русском — пустота. И это не только про цензуру мата.
Если хотите потыкать — videocensor.ru
Если есть вопросы про техническую часть или про то, каково это — фронтендеру лезть в бэкенд — спрашивайте.
Показать полностью
1
Сдохни или переводи. Про карающую дубину кириллицы
Привет, ребятушки.
Наверняка вы уже не раз слышали о 168-ФЗ, вступившем в силу с 1 марта 2026 г. В народе он известен как “закон о защите русского языка”. Топовые мемасики собрал для вас внизу.
Закон коснулся очень многих. Считается, что больше всех досталось хореке, кафе, ресторанам и кофейням. Многие использовали на вывесках латиницу и, соответственно, таким же образом оформляли внутренний интерьер и меню. И вот теперь им все надо переделывать.
Но я вам хочу рассказать, как сказался новый закон на производителях крафтового пива, сидра, медовухи и лимонадов.
Вкратце, о том, что там в новом законе. Итак, с 1 марта вся информация в публичном пространстве должна быть русифицирована. Это касается вывесок, навигации, полиграфии и упаковки продукции, в том числе этикеток. Исключения - зарегистрированные товарные знаки и фирменные наименования. Использование иностранных слов допускается только, если есть русский перевод, написанный тем же шрифтом и тем же размером. При этом нельзя просто написать кириллицей. Перевод должен передавать смысл слов.
Так в чем же проблема?
Конкретно в нашей отрасли проблема в том, что подавляющее большинство небольших крафтовых производителей используют латиницу не только в названиях своих брендов, но и в названии и описании сортов своих напитков. Sour ale, IPA, NEIPA, mead украшают 90% ассортимента баров и пивных магазинов.
Плохо это? Ну, наверное, да. Все-таки, во-первых, мы живем в России и говорим на русском языке и должны использовать его в оформлении произведенной здесь продукции.
Во-вторых, когда смотришь на этикетку, хочется сразу понимать, что перед тобой без необходимости погружаться в тонкости пивной крафтовой культуры.
Но есть нюанс. Так уж получилось, что все это изобилие разного крафтового пива пришло к нам с запада в середине 10-х годов. Соответственно, тогда же и утвердилась мода на латиницу в названиях и написаниях. Во многом из-за того, что адекватных аналогов в нашем языке пока что нет. Они попросту не успели сформироваться за прошедшую декаду. Например, по ГОСТу у нас пиво может быть темным или светлым. Места для всяких охмеленок, кислых элей и молочных стаутов там не было. А сами сорта появились.
Поэтому пивовары и пишут на этикетках sour ale, stout, IPL. Вот только с 1 марта так делать нельзя. Будет штраф.
Вообще, такой проблемы быть как будто бы и не должно. Потому что существуют специальные утвержденные словари, в которых перечислены англицизмы, не требующие перевода. Проблема только в том, что в этих словарях катастрофически мало терминов. Они попросту не успевают обновляться и меняться вместе с миром вокруг. А когда бизнес просит добавить устоявшийся термин в словарь, его мольбы никто не слышит.
Вот, к примеру, несколько недель назад была история, как представители кофейной индустрии просили добавить в словари “дрип-кофе”. И это логично. Такие пакетики с кофе в последние пару лет стали очень популярны. Сегодня их можно найти не только в модных столичных кофейнях, но и в сервисах доставки, и даже сетевых магазинах. Но, увы, в ответ только тишина.
Пытливый читатель скажет, что закон един для всех. Вот и давайте, соблюдайте. И будет прав. Вот только под удар попала целая индустрия ребят, которые варят разное вкусное пивко, а не просто светлое, темное, пшеничное. Для них в отличие от пивгигантов перспектива нарисовать и напечатать заново все этикетки (а также по новой все зарегистрировать в ЕГАИС) - это очень большая финансовая нагрузка.
Видимо, из-за этого лично я и не видел, чтобы крафтовики массово бросились все переделывать, переименовывать сорта и вместо sour ale писать “кислое пиво верхового брожения”. Может, это пока распродаются остатки. Хотя производители чая и кофе тоже пока что ничего не изменили. Видимо, все сидят, ждут, что будет дальше. Хотя штрафы для юрлиц и доходят до 500К.
Такие дела. Надеюсь, что какой-то разумный компромисс в итоге будет найден. Когда, с одной стороны, не будет такого засилья англицизмов и латиницы в медийном пространстве. А, с другой стороны, мы не скатимся в переводы с алиэкспресс, где вместо мьельнира надо будет писать “карающая дубина божества грома и молнии”, а вместо дрип-кофе - кофе черный, обжаренный, молотый, фасованный в бумажный пакет. Ждем расширения словарей и массового добавления в них терминологии из различных сфер и ниш.
Ну и обещанные мемасы (все с просторов интернета).





Показать полностью
7


Этимология знания
Речь пойдёт о праиндоевропейском корне *ǵnō- с семантикой "знать". Чуть позже дойдём как раз до нашего слова "знать", которое от него происходит, но начнём с тех, кто поиздевался над звуками меньше.
Изменения звуков здесь будут касаться первого палатализованного *ǵ (который в кентумных языках затвердеет и станет \g\, а в сатемных смягчится ещё больше и станет \z\ или \j\) и гласного *ō, который кое у кого мог перейти в \а\.
📚 латынь: *ǵ твердеет, *ō не меняется, то есть изменения минимальны
Получаем из *ǵnō- глагол "gnōscere" ("знать"). Правда, со временем первый звук отвалился, и получилось "nōscere".
Отсюда происходит прилагательное "nōbilis" ("знатный"), и далее, например, французское и английское "noble" ("благородный").
Также отсюда существительное "nota" ("знак, заметка"), откуда "нотариус" и "нотации".
Ещё у исходного глагола "gnōscere" был антоним "ignōrāre" ("не знать"), что в других языках со временем приобрело основное значение "игнорировать".
С другой приставкой получался глагол "cognōscere" ("узнать, признать"), откуда причастие "cognitus" ("узнанный") и его антоним "incognitus" ("неузнанный"), который мы знаем по попавшему к нам через итальянский слову "инкогнито".
📚 древнегреческий: тоже кентум (*ǵ твердеет), *ō тоже не меняется
Здесь, правда, случилась своя приколюха с появлением дополнительного первого слога, и получился глагол γῐγνώσκω \gĭgnṓskō\ ("знаю").
Нам досталось производное от него слово с отрицательной приставкой — "агностик".
Ещё с приставкой, которая может означать полноту действия, δῐᾰ́γνωσῐς \dĭắgnōsĭs\ ("диагноз", дословно что-то вроде "распознавание").
И ещё с приставкой, отправляющей нас вперёд в будущее — πρόγνωσῐς \prógnōsĭs\ ("прогноз").
📚 прагерманский: здесь сначала кентум, а потом по *g ещё жахнул закон Гримма, то есть *ǵnō- > *gnō- > *knō-
Потом было ещё несколько шагов, о которых сейчас писать будет слишком долго, но на выходе мы получили, например, английский глагол "know" ("знать"). Первая буква, конечно, уже давно не читается, но тем не менее.
📚 праславянский: наконец-то сатемный язык, то есть *ǵ переходит в *z, а ещё *ō переходит в *а
И из *ǵnō- получаем *зна(ти), ну и дальше наш "знать". А также "знак" и "знатный", то есть те же смыслы, что мы наблюдали в латыни.
Показать полностью
Откуда такие берутся?1
Иногда просто поражаюсь некоторым комментаторам на пикабу... Казалось бы, за последние годы киевские власти уже везде расписались, что они терпеть не могут русскую культуру - сносят памятники, отменяют писателей, язык... Но нет же, в комментариях постоянно вылезают какие-то странные люди, которые об этом ничего не слышали... Интересно, откуда такие берутся?
P.S. Проверил ссылку - комментарии были удалены. Как откуда-то взялся этот странный человек - так куда-то и делся...
Показать полностью
Слово "консьерж" связано со "свечкой" (фр. "cierge")?
(рубрика: вопрос от подписчика)
Нет, не связано.
🕯 Французское слово "concierge", скорее всего, происходит от латинского "cōnservus" ("товарищ по службе, коллега-раб"). Приставка "cōn-" аналогична нашей "со-" и означает совместность, а слово "servus" — это "раб" или "слуга".
Про этот корень можно рассказать отдельно.
За пять веков до Юлия Цезаря царем Рима был этруск Сервий Туллий. По легенде он был сыном пленной женщины по имени Окрисия, благородного происхождения, но превращенной в рабыню. Возможно, именно поэтому мальчика и назвали Сервием ("servus" - лат. "раб, слуга").
С другой стороны, это может быть позднейшей народной этимологией, в то время как на самом деле это было изначально этрусское имя, которое означало что-то приличное (𐌔𐌄𐌓𐌅𐌉 [servi], 𐌔𐌄𐌓𐌅𐌄 [serve]). А может, уже и в этрусском такое имя указывало на рабское происхождение его носителя, и перекочевало в латынь не только как имя собственное, но и как обычное слово "servus" ("раб"). Либо этрусское имя просто совпало с этим латинским словом.
И если слово "servus" ("раб") латинское, то его можно вывести из протоиталийского *serwos ("охранник, пастух") от праиндоевропейского *ser ("охранять, наблюдать"), откуда, например, происходит:
🧜🏻♀️ греческое ἥρως [hḗrōs] ("герой"), начальная греческая "h" часто соответствует латинской и не только "s", как в случае с "гелиос" ("helios") и "sol" ("солнце")
🧜🏻♀️ возможно, греческая Ἥρᾱ [Hḗrā], то есть, получается, "охранительница"
🧜🏻♀️ авестийское "haraiti" ("защищать, заботиться")
🧜🏻♀️ латинское "servāre" ("хранить, защищать")
🧜🏻♀️ латинское "servīre" ("служить, быть рабом")
И вот как раз по последнему слову есть вопросы, не этрусское ли оно всё-таки часом. С другой стороны, а почему бы не быть этим глаголам, "servāre" и "servīre" действительно однокоренными. Во-первых, служить кому-то очень часто заключалось в том, чтобы этого кого-то защищать. Во-вторых, могло быть и наоборот, твои рабы - это те, кого ты защищаешь (как у нас из одного корня слова "раб" и "ребёнок", а ещё "холоп" и "хлопец").
Но если с происхождением не всё до конца понятно, то продуктивность у этих слов в любом случае просто зашкаливает:
🎗 "сервант": дословно "служащий" (суффикс "ant" указывает на активное причастие)
🎗 "консервы": латинская приставка "con" соответствует нашей "со", так что получается дословно "сохранное" или "сохраняемое"
🎗 "пресервы" и "презерватив": латинская приставка "пре" соответствует нашей "пред", то есть одно это "предохраняемое", а другое - "предохраняющее"
🎗 "сервис" и "сервиз": одно и то же слово, только полученное через английский и через французский, а дословно переводится оно как "служба" или даже, скорее, "обслуживание"
🎗 "десерт": происходит от французского "desservir" ("убирать со стола"), антонима от "servir" ("обслуживать, накрывать на стол, подавать"), то есть это то, что подают, когда всё, что давали перед этим, убирают со стола
🎗 "консьерж": тут не точно, но, возможно, происходит от латинского "conservus", что переводилось как "раб-сослуживец", "тот, кто служит вместе с тобой рабом" (приставку "con" мы сегодня уже видели)
🎗 "сержант": в поздней латыни на базе нашего корня возникло слово "servientem" ("служащий, вассал, солдат"), старо-французский сделал из этого слово "sergeant", чьё значение свелось к военному, ну и сохранилось в других языках тоже (современный французский: "sergent")
🎗 "сервер": теперь английское слово с активным суффиксом деятеля, получается дословно "хранитель" или "служитель"
🎗 "обсерватория": от латинского "observare" ("наблюдать"), если вы ещё помните значение праиндоевропейского корня *ser ("охранять, наблюдать")
🎗 "резерв", "резервуар", "резервация": от латинского "reservare" ("охранять, сохранять, хранить"), только суффиксы разные, ну и области применения этих слов
Ну и самое непонятное - это Сербия. По одной из версий "сербами" называли пастухов (они как бы "охранники" овец и коз). Впрочем, это может быть простым переосмыслением этнонима со стороны.
🕯 А французское слово "cierge" ("церковная свеча") идёт от латинского прилагательного "cēreus" ("восковой"), от слова "cēra" ("воск"). Кстати, это слово субстратное, и от него также происходит современное французское "cire" ("воск").
Кстати, наш "воск" и заимствованная у германцев "вакса" тоже не вызывают доверия в плане праиндоевропейской реконструкции, то есть могут быть заимствованиями из доиндоевропейского субстрата.
Показать полностью
Русский язык усваивается проще, чем украинский
Мовный омбудсмен Елена Ивановская заявила, что нейролингвистам надо изучать русский язык, потому что украинцы легче усваивают его, чем ридну мову)
Конечно, если существует 100 тысяч версий мовы (кто как придумал), то такой язык сложно учить.

Размышления
с замедлением всего телеграм стал похож на аську. общаться можно, но картинки и видео лучше передавать ссылками в интернет, чтобы посмотреть там.
скайпа нет. впн запретят. может вы знаете альтернативный мессенджер?
пост скриптум: на какую гласную надо ставить ударение в слове "щепоть"?