Недавно попал на одного блогера/кодера и увидел у него прикольное приложение, когда наговариваешь свою мысль и после расшифровки вставляется текст. Но, меня жаба задушила отдавать $20, поэтому решил написать свое решение, с блекджеком и портовыми леди.
WhisperTyper - это приложение, которое позволяет надиктовывать свои мысли голосом и переводить их в текстовый формат. Используется модель Whisper, которая довольно неплохо справляется с данной задачей. После скачивания модели приложение работает без доступа в интернет, автономно.
Как использовать? Настройте приложение, выберите языки, модели, хоткеи, дайте разрешение на использование (если ОС требует) и можете начинать пользоваться. Например, вы хотите написать сообщение в мессенджере: выделяете поле ввода текста, нажимаете хоткей и наговариваете текст. После расшифровки текст будет вставлен в поле ввода и/или скопирован в буфер обмена (смотрите настройки). Таким образом можно надиктовывать большие тексты частями, курсор будет оставаться в поле ввода.
Привет, Пикабу! Вот пример работы данного приложения.
Какую модель выбрать? Для русского языка я использую v3 large, но для многих других лучше подойдут v3 large (turbo) - меньше размер, а качество не хуже. В общем пробуйте.
Какие ОС поддерживаются? Изначально разработка шла под MacOS (M series), Linux и Windows, но протестировал пока только на MacOS (Tahoe). Последующие версии, если таковые будут (возможно никому приложение и не нужно будет), вероятно будут и под другие ОС, так что следите за обновлениями. Меня лично интересует данная версия на мой steamdeck, так что далее буду тестировать на нем.
Что про автообновление? Данная версия без автоматического обновления, поэтому можно периодически заглядывать на данную страницу (скачать тестовую версию здесь же), чтобы проверить появилась ли версия с автообновлением.
Какой потенциал? В теории Whisper неплохо можно тюнить, поэтому легко доработать под определенную нишу, к примеру, здравоохранение, и уже перейти на нормальный ввод диагноза голосом с переводом в текст. А то большую часть приема у врача я сижу и смотрю как он еле-еле набивает текст двумя пальцами. Автономность (нет необходимости в интернете) добавляет некоей конфиденциальности.
Это прямо альфа-версия, могут быть баги в определенных режимах использования, но у меня пока стабильно, так что делюсь. Идеи доработок пишите в комментарии.
p.s. текст надиктовывал с ее помощью с небольшими правками (запятые, пару раз буквы поправить, html-теги).
Всем привет! Команда Microsoft Research выложила в открытый доступ VibeVoice-ASR — нейросетевую модель для распознавания речи с диаризацией (разделением) спикеров. Сегодня хочу рассказать об этой технологии подробнее и поделиться портативной версией.
Меня зовут Илья, я основатель сервиса для генерации изображений ArtGeneration.me, блогер и просто фанат нейросетей. А ещё я собрал портативную версию VibeVoice ASR под Windows и успел её как следует протестировать.
Whisper которому уже года три
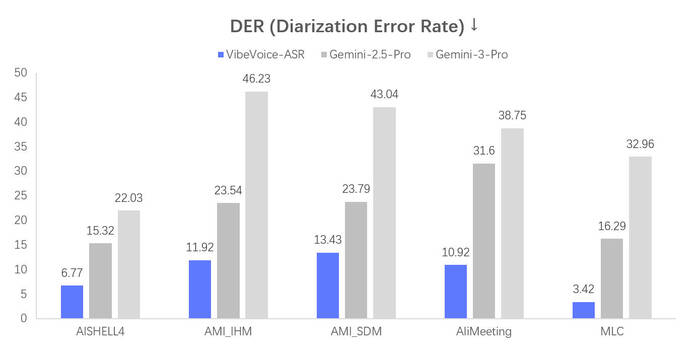
Я сам пользуюсь Whisper уже много лет — делаю транскрипции своих видео, чтобы потом собрать оглавление для YouTube и использовать материал в текстовых статьях. И скажу честно — никогда не был полностью доволен результатом. Да, Whisper быстрый. Но на этом его достоинства для меня заканчивались.
Поэтому к изучению VibeVoice ASR я подошёл со всей ответственностью — протестировал на разных записях, сравнил качество, покрутил настройки.
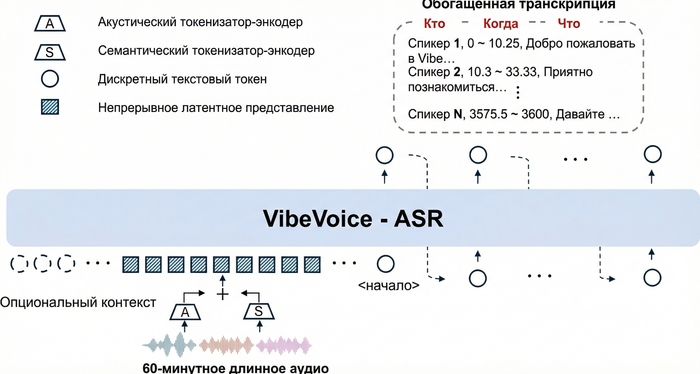
Главная особенность системы в том, что она обрабатывает до 60 минут аудио за один проход без нарезки на чанки. На выходе — структурированная транскрипция с указанием кто говорит, когда и что именно сказал. И всё это работает локально на вашем компьютере.
Как это работает
В основе VibeVoice-ASR лежит архитектура на базе Qwen 2.5 (~9 млрд параметров). Ключевая инновация — двойная система токенизации с ультранизким frame rate 7.5 Hz: акустический и семантический токенизаторы.
Такой подход позволяет модели работать с контекстным окном в 64K токенов — это и даёт возможность обрабатывать целый час аудио без потери контекста. Для сравнения: Whisper режет аудио на 30-секундные кусочки и теряет связность на границах сегментов.
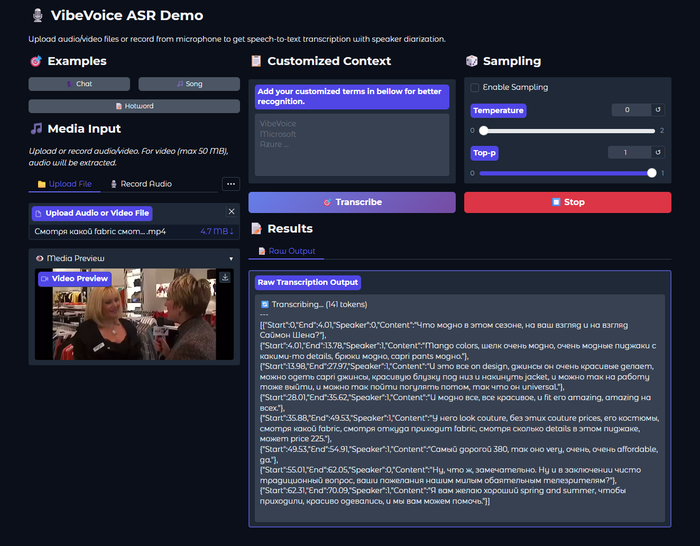
На выходе модель генерирует Rich Transcription — структурированный поток с тремя компонентами:
{"Start":1.51,"End":7.49,"Speaker":0,"Content":"У неё преждевременное сохранять невозможно, родила, начала сразу родильная деятельность."},
{"Start":7.51,"End":9.41,"Speaker":1,"Content":"Марина, что с ней?"},
{"Start":10.28,"End":16.22,"Speaker":0,"Content":"У неё преждевременное сохранять невозможно, отошли годы, начала, начала сразу родовая деятельность."},
{"Start":16.22,"End":18.02,"Speaker":1,"Content":"Марина, что с ней?"},
{"Start":18.13,"End":27.94,"Speaker":0,"Content":"Она рожает, привезли в ближайшую больницу родовую. В каком состоянии ребёнок ещё хуже, срок маленький."},
Помимо спикеров, модель размечает неречевые события: [Music], [Silence], [Noise], [Human Sounds] (смех, кашель), [Environmental Sounds], [Unintelligible Speech]. Это сделано чтобы модель не галлюцинировала текст во время пауз или фоновой музыки.
Обработка длинных записей: до 60 минут аудио за один проход без потери контекста. Идеально для митингов, подкастов, лекций.
Диаризация спикеров: автоматическое определение кто говорит в каждый момент времени. Работает на записях с несколькими участниками.
Временные метки: точные таймкоды для каждого сегмента речи. Готовый материал для субтитров.
Customized Hotwords: вот что меня реально зацепило — возможность задать пользовательский контекст. Перед распознаванием указываешь список слов: фамилии, названия продуктов, термины, сокращения. Всё то, что обычно произносится нестандартно и превращается в кашу. Если в видео часто звучит "ArtGeneration" или "НЕЙРО-СОФТ" — просто добавляешь в контекст, и модель ВСЕГДА распознаёт корректно. Для технического контента — просто спасение.
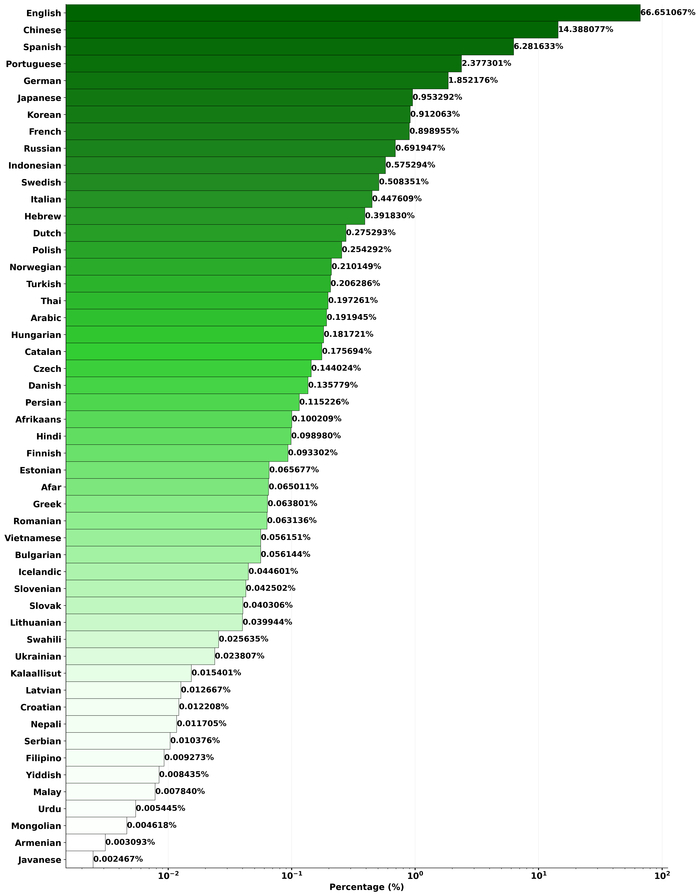
51 язык: включая русский, хотя основной фокус на английском и китайском.
Набор языков отличный
Модели
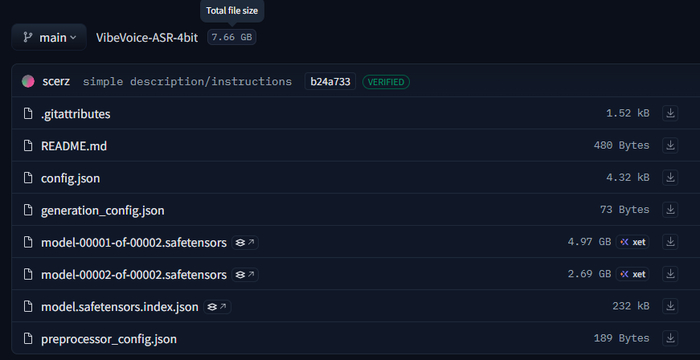
Помимо оригинальной модели от Microsoft, сообщество уже сделало квантованные версии для видеокарт с меньшим объёмом памяти.
Полная модель — microsoft/VibeVoice-ASR Размер 17.3 GB, требует ~8 ГБ VRAM. Лучшее качество распознавания.
4-bit квантизация — scerz/VibeVoice-ASR-4bit Требует ~4 ГБ VRAM, немного медленнее. Подходит для видеокарт с меньшим объёмом памяти.
В моей портативке доступны обе версии — можно выбрать прямо в интерфейсе. Также есть эмуляция 4-bit квантизации для полной модели, если хотите попробовать оригинал, но памяти впритык.
Текущие ограничения
К сожалению, не все задачи система решает одинаково хорошо:
Перекрывающаяся речь: если два человека говорят одновременно, модель не разделит их корректно.
Короткие фрагменты: диаризация плохо работает на высказываниях менее 1 секунды.
Только batch processing: нет real-time режима, только обработка готовых файлов.
Ресурсоёмкость: требует достаточно мощную видеокарту для комфортной работы.
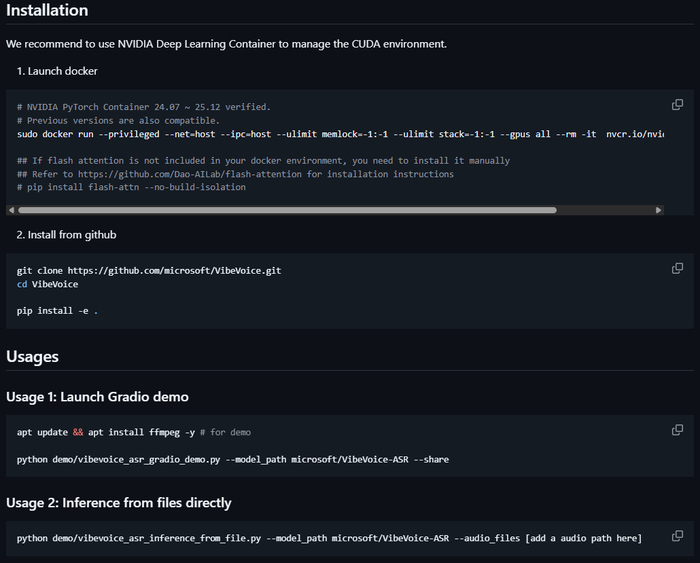
Я с каналом Нейро-Софт подготовил портативную сборку VibeVoice ASR Portable RU. В ней:
Русифицированный интерфейс
Установка в один клик (install.bat)
Поддержка полной и 4-bit моделей
Парсер результатов с фильтрацией — можно отдельно включать/выключать временные метки, спикеров, дескрипторы (музыка, шум, тишина). Удобно когда нужен только чистый текст без разметки
Фильтр по спикерам — можно вывести текст только конкретного участника разговора
Выбор видеокарты и установка нужной версии CUDA
Flash Attention 2 для RTX 30xx/40xx/50xx
Поддержка всех форматов аудио и видео через FFmpeg
Тёмная тема интерфейса
Всё необходимое уже включено в дистрибутив, просто распакуйте и запускайте, есть версия с готовым окружением под win 11 и RTX4090. Забирайте архив тут.
NVIDIA GPU с 8+ ГБ видеопамяти (или 4+ ГБ для 4-bit модели)
Windows 10/11 64-bit
16 ГБ оперативной памяти
10 ГБ свободного места на диске
Распакуйте в любую папку (путь без кириллицы), запустите install.bat, выберите видеокарту из списка. Модели скачаются при первом запуске.
Рассказывайте в комментариях как вы могли бы использовать такой инструмент и чего не хватает.
Я рассказываю больше о нейросетях у себя на YouTube, в Телеграм и на Бусти. Буду рад вашей подписке и поддержке. На канал Нейро-Софт тоже подпишитесь, чтобы не пропустить полезные репаки. Всех обнял. Удачных транскрипций!
Создал инструмент для автоматической локализации аудио в играх. Изначально делал для себя — для перевода небольших старых проектов.
Качество, конечно, до профессиональной озвучки не дотягивает: пока использую один голос и накладываю его на оригинальное аудио. Зато эмоции персонажей сохраняются, получается как в фильмах 90-х — та самая одноголосая озвучка на кассете, немного ностальгии.
Пару обработанных файлов тут (тут аудио не выкладываются)
🔹 Фильтрует смех и звуки — не озвучивает "ха-ха", "вуху", "смеется", "wow" и подобное. Смех остается оригинальным.
🔹 Исправляет ударения — ставит правильные ударения в русском тексте, особенно в игровых терминах (атака́, защи́та, урове́нь).
🔹 Работает в один клик — веб-интерфейс в браузере, отслеживание прогресса, статистика.
Технологии:
Whisper AI — распознавание английской речи
Silero TTS — синтез русской речи
LibreTranslate — перевод
Python — основа всего
Недостатки:
Доставать файлы из игры и запаковывать обратно всё так же сложно
Пропуски в фильтрации смеха еще есть (будем исправлять)
Скоро покажу полную демонстрацию. А пока — пример исходного и обработанного файла в приложении тут.
Первый пост прям залетел аж 14 плюсиков и всего 3 минуса, это успех...
Не буду долго расписывать что да как просто ссылок накидаю... небыло специально обученной модели под русский язык, сегодня ночью переконвертировал small модель для русского в формат ggml для whisper.cpp до этого нормально распознавало только на больших моделях large и medium работало долго. Теперь доступна small для русского языка к стати whisper.cpp работает и на windows и на linux даже на телефоне на обычном CPU очень качественная транскрипация получается со знаками препинания скобочками кавычками дефисам, это очень круто.