Разблокируйте данные из PDF: Конвертация PDF в Excel с помощью бесплатного Python API
Преобразование PDF-документов в таблицы Excel — это критически важный процесс для таких задач, как анализ данных, подготовка отчетов и автоматизация рабочих процессов. В данном руководстве представлены два эффективных метода использования бесплатных библиотек Python для решения этой задачи:
Конвертация полных страниц PDF или целых документов в формат Excel.
Извлечение таблиц из PDF-файлов и их экспорт в Excel.
Сравнив эти методы, вы сможете выбрать оптимальный подход, соответствующий вашим требованиям.
Необходимые библиотеки для установки
Для начала работы вам необходимо установить следующие библиотеки Python:
[ Free Spire.PDF for Python ]: Эта мощная библиотека предоставляет инструменты для работы с PDF-файлами, включая возможность конвертации содержимого PDF в Excel и извлечения табличных данных.
[ openpyxl ]: Известная библиотека с открытым исходным кодом, которая упрощает чтение, запись и изменение файлов Excel.
Вы можете установить обе библиотеки с помощью pip:
pip install spire.pdf.free openpyxl
После установки библиотек мы можем перейти к методам конвертации.
Способ 1: Полная конвертация PDF-документа в Excel
Этот подход подразумевает преобразование всего содержимого PDF (текста, изображений и макета) в таблицу Excel с сохранением исходного дизайна.
Важные настройки конвертации
Класс XlsxLineLayoutOptions определяет, как именно будет происходить конвертация из PDF в Excel. Этот класс принимает следующие параметры:
convertToMultipleSheet (bool) : Если установлено значение True, каждая страница PDF станет отдельным рабочим листом; если False, будет конвертирована только первая страница.
rotatedText (bool) : Управляет отображением повернутого текста, найденного в PDF.
splitCell (bool) : Если True, многострочный текст разделяется на отдельные ячейки в Excel; если False, весь текст сохраняется в одной ячейке.
wrapText (bool) : Активирует перенос текста внутри ячеек Excel.
overlapText (bool) : Определяет, как обрабатывается накладывающийся текст.
Пример реализации кода
from spire.pdf.common import *
from spire.pdf import *
# Создание экземпляра класса PdfDocument
doc = PdfDocument()
# Загрузка нужного PDF-файла
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.pdf")
# Настройка параметров конвертации в XLSX
options = XlsxLineLayoutOptions(False, False, False, True, False)
# Применение параметров к документу
doc.ConvertOptions.SetPdfToXlsxOptions(options)
# Сохранение результата в файл XLSX
doc.SaveToFile("output/ToExcel.xlsx", FileFormat.XLSX)
# Закрытие документа
doc.Close()
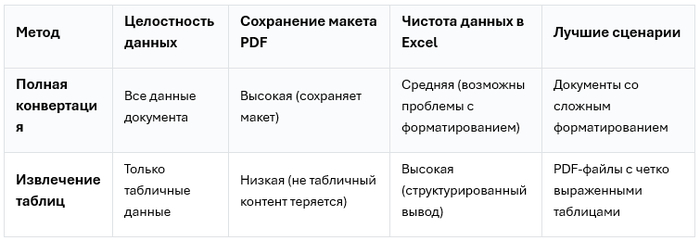
Плюсы:
Сохраняет исходный макет PDF, включая расположение текста и форматирование.
Эффективен для документов со сложной версткой.
Минусы:
Может привести к нежелательному объединению ячеек или изменению размеров строк и столбцов.
Текст может потерять связность, если содержимое распределится по разным ячейкам.
Способ 2: Извлечение табличных данных из PDF в Excel
Этот метод ориентирован на извлечение именно табличных данных из PDF и их экспорт в Excel, что обеспечивает структурированный и чистый результат.
Пример кода для извлечения таблиц
from spire.pdf import *
from openpyxl import Workbook
from openpyxl.utils import get_column_letter
# Создание объекта PdfDocument
doc = PdfDocument()
# Загрузка PDF-файла
doc.LoadFromFile("C:/Users/Administrator/Desktop/input.pdf")
# Настройка экстрактора таблиц для PDF-документа
extractor = PdfTableExtractor(doc)
# Создание новой книги Excel и удаление листа по умолчанию
workbook = Workbook()
workbook.remove(workbook.active)
# Извлечение таблиц со всех страниц
for page_index in range(doc.Pages.Count):
tables = extractor.ExtractTable(page_index)
for t_index, table in enumerate(tables):
# Создание нового рабочего листа для каждой извлеченной таблицы
sheet = workbook.create_sheet(title=f"Page {page_index + 1}_Table {t_index + 1}")
# Отслеживание максимальной длины каждого столбца
max_lengths = [0] * table.GetColumnCount()
for row in range(table.GetRowCount()):
for col in range(table.GetColumnCount()):
text = table.GetText(row, col).replace("\n", " ").strip()
sheet.cell(row=row + 1, column=col + 1, value=text)
max_lengths[col] = max(max_lengths[col], len(text))
# Автоматическая подгонка ширины столбцов
for col in range(table.GetColumnCount()):
adjusted_width = (max_lengths[col] + 2) # Добавление буферного пространства
sheet.column_dimensions[get_column_letter(col + 1)].width = adjusted_width
# Сохранение готовой книги в файл Excel
workbook.save("output/TableData.xlsx")
Плюсы:
Фокусируется исключительно на извлечении данных из таблиц, обеспечивая чистый и организованный результат.
Улучшает читаемость в Excel (позволяет избежать проблем с объединенными ячейками).
Минусы:
Не сохраняет контент, который не является частью таблицы (например, изображения или примечания).
Для точного извлечения требуется четко определенная структура таблиц в PDF.
Сравнение методов
Заключение
Выбирайте метод полной конвертации , если критически важно сохранить исходный макет (включая изображения и произвольный текст), особенно в официальных документах.
Выбирайте метод извлечения таблиц , когда для анализа требуются только структурированные данные.
Каждый метод имеет свои преимущества; ваш выбор должен зависеть от конкретных требований вашего проекта.