
0 просмотренных постов скрыто


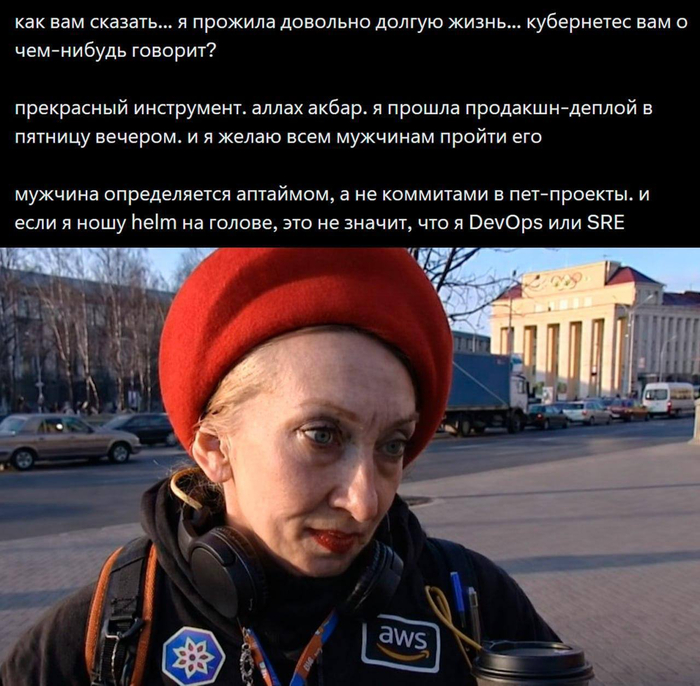


Ответ на пост «Сисадмин эволюционировал в DevOps — и вот что из этого вышло»1
Что за бред я прочитал под видом длинопоста месячной давности?
И почему не надо хоститься в Git In Sky, судя по этому посту.
Для лиги лени: опять на Пикабу тащат старье с выродившегося в маркетинг хабра
стал DevOps-тимлидом
Вместо трелей будильника мой телефон издает тревожный звон сообщений из системы мониторинга и экстренных звонков от клиента.
На телефон лида никогда, ни при каких обстоятельствах, не идут ни данные мониторинга, ни звонки от клиентов. Вообще никогда. И то, и другое, идет на первую линию, максимум на вторую.
вижу, что сломалась база данных. В такой ранний час из кластера предательски вывалилась одна нода.
База данных не "ломается" просто так. Кроме случаев, когда в нее кто-то кривыми руками полез, и что-то в ней удалил. И ни в каком случае это не связано с выпадением ноды из кластера.
Есть два основных сценария:
1 База данных не очень важна, не очень нужна, и можно положиться на работу сервиса High availability (HA). Ну умерла одна физическая нода, да и ладно, через 2-5 минут система перезагрузится на другой
2 База данных важна, нужна, и очень нужна. В таком случае строится или RAC или Always on, в разных вариантах, по бедности, и когда база все же нужна, но не очень, можно обойтись Pacemaker&Corosync, или Patroni . Stolon может быть. Если вы смелый и старый - Galera.
При любых условиях выпадение ноды из кластера порождает только алерты, которые закрываются первой линией.
Как мне подсказывают, еще такое "отсутствие HA" бывает при внедрении "типа-импортозамещения" методом далее-далее, там HA отсутствует, в привычном понимании.
Инициализировав новую ноду и добавив ее в кластер
Чего чего там происходит? Достав со склада холодный резерв? И за 5 минут его подготовив к работе, прямо из дома в ЦОД? Что я только что прочитал?
И при чем тут девопс лид?
Подъем по тревоге” ночью или в выходные происходит не часто (один-два раза в месяц).
Это значит, что система абсолютно не настроена, и построена из говна и свиста. Нет резервов, нет кластера, нет людей. Все задачи свалены на как-бы лида, но по фактическим задачам - инженера, ответственного за физическую инфраструктуру.
Как и у многих хостинговых компаний на рынке, у нас сложилась “многоярусная” система реагирования на проблемы с инфраструктурой.
Но при чем тут девопс, если речь про хостинг? Где тут в схеме "вышел из строя физический сервер" - CI или CD ?
Мы сознательно отказались от полностью автоматической системы и поставили между инфраструктурой и инженерами людей. Автоматика бы отзванивалась на любой чих в системе.
То есть автоматика не просто не настроена, ее вообще нет.
Сегодня инженер, ответственный за проект, не подошел к телефону
Как легко увидеть, налицо экономия на качестве и кадрах. Нормальная система слежения требует 2 (двух) людей на уровне, и только потом эскалацию на уровень выше. Опять же, совершенно не поняна иерархия - почему заявлены проблемы в железной части, но звонок ушел на девопс-инженера и девопс-лида?
Умываюсь и иду на дейлик в 10:00 по Москве, где мы отчитываемся о наших задачах.

Собери совещание
Обязательно присутствуют проджекты, которые приносят обратную связь от заказчиков - допустим, клиент приходил в пятницу и просил побыстрее что-то сделать. Мы оцениваем срочность и, если это необходимо, раздвигаем очередь задач, чтобы сфокусироваться на самом важном.
то есть спринтов нет, метод "бегаем туда - бегаем сюда".
Классика.
В общей сложности на опрос 20 с лишним человек уходит 18-20 минут.
20 человек в девопс команде на одного лида, но при этом один дежурный инженер? Цифры не сходятся. Никак.
Как выяснилось, тот поставил телефон на зарядку в соседней комнате и не услышал звонка. Обсудили ситуацию, договорились больше так не делать.
Исправлять ситуацию, конечно, никто не собирался. Но это уже другая история
Послеобеденное время — период, когда можно тет-а-тет обсудить задачи коллег. Сегодня, например, минут 40 проводил плановый performance-аудит баз данных одного из проектов.
Какое отношение perf аудит, который зависит еще и от запросов, не говоря про оптимизацию внутри базы, чем занимаются DBA, имеет к devops ? Да, observability находится на мониторинге, в том числе, у devops команды, но в реальном мире devops инженер обычно не лезет в план запросов.
Помимо встреч, мне с разных сторон прилетают задачки. Например, приходят коллеги из отдела маркетинга с заявками от клиентов. Они ждут совета, как и в какой пакет обернуть требуемую услугу, какую сделать презентацию. Будучи архитектором,
только что был девопс лидом, а стал архитектором. Волшебная трансформация. Маркетолог, писавший текст, забыл о чем писал?
Вечером, уже дома, могу посмотреть кино с женой или сажусь за свой пет-проект.
После подьема по алерту в 4 утра, два раза в месяц, к 20 человек падает в кровать. Какой уж тут пет-проект.
Впрочем, удивляться нечему. Если текст размещен на Хабре в 2025 - значит, это обычное маркетинговое творение. Накрыть пленкой, весной закопать в грядки перед посадкой картошки.
Показать полностью
1
1

Сисадмин эволюционировал в DevOps — и вот что из этого вышло1
Дмитрий, тимлид DevOps-команды в Git In Sky, о том, как проходят будни DevOps-инженера и какие вызовы приносит стремительный рост рынка облачных решений.
Был сисадмином, затем техническим директором — стал DevOps-тимлидом. В идеальном мире моя задача — автоматизировать рутину, настроить CI/CD, мониторинг и придерживаться принципа “Инфраструктура как код”.
Но это в теории. На практике же стабильность системы держится на честном слове, пока кто-то не решит "чуть-чуть поправить" прод. Поэтому DevOps — это вечный "День Радио" в отдельно взятой инфраструктуре.
“День Радио” — это фильм с сюжетом, что в прямом эфире вот-вот должен стартовать марафон, но за десять минут до начала выясняется, что заранее подготовленная тема перехвачена конкурентами. И начинается суета и множество сюжетных поворотов и проблем 🙂
6:00. С добрым утром, кластер
Ранним утром понедельника, когда солнечные лучи ещё не дребезжат на горизонте, когда город за окном только-только начинает оживать, и на улицах появляются первые люди, спешащие на работу на другой конец города, я уже за работой. Вместо трелей будильника мой телефон издает тревожный звон сообщений из системы мониторинга и экстренных звонков от клиента.
Ещё даже не проснувшись, но уже общаясь с клиентом, одним глазом смотрю в отчеты системы оповещений и вижу, что сломалась база данных. В такой ранний час из кластера предательски вывалилась одна нода. Все так же в режиме "автопилота", машинально копирую выжимку логов сервера, для ознакомления с ними позже и принятия мер по недопущению досадного инцидента в будущем, а затем применяю стандартный набор инструментов восстановления.
Инициализировав новую ноду и добавив ее в кластер, я заботливо отписываюсь клиенту, что работа системы будет восстановлена в ближайшее время и только после этого укладываюсь обратно в кровать, чтобы урвать драгоценные оставшиеся минуты сна..
“Подъем по тревоге” ночью или в выходные происходит не часто (один-два раза в месяц). Только если отваливается проект, по которому ответственный я, или кто-то из инженеров моей группы, который не смог принять вызов.
Как и у многих хостинговых компаний на рынке, у нас сложилась “многоярусная” система реагирования на проблемы с инфраструктурой. Первый уровень - это младшие дежурные, которые сидят посменно: по 12 часов в режиме 24/7. Когда-то и я начинал с такого, но в другой компании.
Мы сознательно отказались от полностью автоматической системы и поставили между инфраструктурой и инженерами людей. Автоматика бы отзванивалась на любой чих в системе. А задача младших дежурных - провести первичный аудит проблемы, т.е. подтвердить, что она действительно требует решения, это не ложное срабатывание.
Если проблема не отсеивается и не решается на нижнем уровне, младший дежурный звонит инженеру. У каждого инженера есть набор проектов, по которым к нему могут обратиться круглосуточно. Плюс, в компании предусмотрена система эскалации — если инженер недоступен, звонок поступает вышестоящему коллеге — в первую очередь мне, как лиду. Если бы и я не снял трубку, звонок пошел бы техническому директору.
Сегодня инженер, ответственный за проект, не подошел к телефону, но цепочка остановилась на мне.
10:00. Утренний скрам

Штатный подъем — тремя часами позже. Умываюсь и иду на дейлик в 10:00 по Москве, где мы отчитываемся о наших задачах. Как правило, по задачам у нас две встречи: ровно в десять мы отчитываемся, что делали вчера — в данном случае в пятницу, что произошло за выходные, что будем делать сегодня и в какой последовательности.
Эта встреча помогает правильно расставить приоритеты. Обязательно присутствуют проджекты, которые приносят обратную связь от заказчиков - допустим, клиент приходил в пятницу и просил побыстрее что-то сделать. Мы оцениваем срочность и, если это необходимо, раздвигаем очередь задач, чтобы сфокусироваться на самом важном.
Стараемся быть предельно краткими — ничего не обсуждаем, просто ставим приоритеты и синхронизируем статусы. В общей сложности на опрос 20 с лишним человек уходит 18-20 минут.
10:20. Разбор полетов
Следом проходит After scrum, где мы уже устраиваем разбор полетов. Тема сегодняшнего утра - почему подъем по тревоге был у меня, а не у ответственного инженера. Как выяснилось, тот поставил телефон на зарядку в соседней комнате и не услышал звонка. Обсудили ситуацию, договорились больше так не делать.
В целом в подобных ситуациях мы друг на друга не обижаемся. У нас сыгранная команда и доброжелательные отношения. В данном случае было бы гораздо хуже, если бы я был недостаточно знаком с проектом. В подобных случаях понять даже самые простые вещи спросонья не так-то просто.
На After scrum мы обсуждаем не только инциденты, но и то, кому и как решать те или иные задачи. Младшие приходят к старшим, а я часто выступаю эдаким “играющим тренером” - раздаю ребятам задачки, принимаю результаты работы и даю подсказки, наводящие на решения возникающих трудностей.
Чаще всего, кстати, при приемке срабатывает проверка “на дурака” - что в задаче действительно выполнены все пункты, именно так, как просил клиент, а не как додумал DevOps-инженер. В анализе задач всегда приходится включать здравый смысл. В нашей сфере задача вполне может быть решена (допустим, попросили добавить какой-то флаг PHP — ты добавил), а проблема клиента — нет. Это частая история. Иногда даже приходится применять решение, противоречащее best practice, потому что именно оно, а не что-то другое, решает задачу клиента.
11:00. Архитектурный созвон
Расходимся мы около 11 часов. После этого по понедельникам я созваниваюсь с архитекторами — это 3-4 человека по всей команде. Зачастую присутствуют и проджекты, которые ведут данные проекты.
У нас около 30 проектов — больше, чем у других команд в компании. На созвоне проджекты называют их по алфавиту, а мы обсуждаем, что в них произошло за последнюю неделю. У кого-то не происходило ничего, где-то мы отчитались о последних выполненных работах, но клиент с обратной связью не вернулся, у кого-то были инциденты, и мы их починили, и так далее. Событий много, так что и времени на эти обсуждения уходит прилично — до полутора часов.
В другие дни недели вместо архитектурной встречи у меня есть час или два свободного времени, чтобы решить свои задачи.
12:30. Анализ логов
После окончания созвона выдался момент, чтобы наконец проанализировать, что произошло рано утром. Нужно не только понять, что вызвало падение ноды, но и написать отчет клиенту — его, как правило, пишет инженер, который обработал инцидент, т.е. я.
Скорее всего роль сыграли изменения от разработки клиента. Моя задача: описать случившееся и отчитаться об общем даунтайме, если он был. Сегодня инцидент имел место, но система просто перешла в режим деградации, на продукте это никак не сказалось. Готовый отчет я направляю разработчику, который ведет проект со стороны клиента, а также прикладываю к задаче в нашем таск-трекере (в зависимости от того, каким инструментом пользуется клиент).
Как правило, инцидент — это проблемная область с определенными симптомами, если говорить терминами управления. Так что я не только отчитываюсь письменно, но и созваниваюсь с клиентом, чтобы выяснить, как я могу помочь решить эту проблему на системном уровне, чтобы повторно таких событий не возникало.
По итогам всех изысканий мы выстраиваем цепочку гипотез и подтверждений. И если знаем, куда копать, идем решать - проверяем гипотезы одну за другой, пока не доходим до проблемной точки. В зависимости от поломки, эта история может растянуться на неделю и больше, хотя, если кейс простой, все решается за пару часов.
Сегодня у меня не было свободного окна между встречами, поэтому обед пришлось поглощать за компьютером. В короткой паузе между созвонами сходил на кухню, поцеловал жену в щечку, залез в холодильник и достал уже готовый обед — сегодня это ежики. Разогрел в микроволновке, пошел обратно на свое рабочее место.
14:00. Ворох задач

Послеобеденное время — период, когда можно тет-а-тет обсудить задачи коллег. Сегодня, например, минут 40 проводил плановый performance-аудит баз данных одного из проектов. Потом отвечал на вопросе в чате пресейлов.
Помимо встреч, мне с разных сторон прилетают задачки. Например, приходят коллеги из отдела маркетинга с заявками от клиентов. Они ждут совета, как и в какой пакет обернуть требуемую услугу, какую сделать презентацию. Будучи архитектором, я также занимаюсь планированием различных работ и разбором уже выполненных операций перед тем, как они будут сданы клиенту. А еще с каждым из клиентов у меня есть еженедельный созвон по событиям за эту неделю. Могу так же, как инженер, сделать какие-то задачи из общего трекера: сегодня я переделал раннеры в GitLab CI, достал данные из логов по просьбе коллеги, ответил на вопросы в чате разработчиков.
В своей работе мы в основном опираемся на подход инфраструктура как код (Iaac). Основные инструменты — Ansible и Terraform, так что 80% времени мы работаем с заготовками Ansible. У нас есть копилка плейбуков для Ansible, которые модифицируются всеми командами. Это общий котел с заготовками, откуда мы периодически вынимаем и добавляем нужное. Но вопросы в чате все равно возникают часто.
Иногда дело доходит и до собеседований. Как именно я собеседую — на что и почему смотрю — я расскажу отдельно. Это довольно обширная тема.
В таком потоке задач приходится постоянно помнить о приоритизации. Высшую важность для меня имеют задачи, связанные с поломками или то, что нужно выполнить строго по дедлайну. Следующий уровень — пресейлы. Также стараюсь максимально быстро делать задачи от коллег из других отделов, чтобы не держать коллег в ожидании - чтобы они могли пойти дальше общаться с клиентом.
19:00. Вечер трудного дня
Мой рабочий день заканчивается в 19 часов. Под конец дня я заполняю отчет, куда потратил свое время - мы трекаем все в Redmine. После этого иду к техдиру и спрашиваю в переписке, как прошел день, какие есть проблемы, не нужно ли что-то подхватить. Делаю я это уже обычно с телефона, сидя на кухне. С техдиром мы в свободной форме обсуждаем ситуацию и расходимся отдыхать.
Кажется, что мой график не нормирован. Но на самом деле это только одна сторона медали. Вторая сторона, что я могу работать всего 4 часа за день. У нас свободное отношение к присутствию на рабочем месте (если не случился инцидент, конечно). Надо жену в магазин отвезти посреди дня — пожалуйста. В МФЦ документы подать — тоже без проблем.
Понедельник у меня довольно насыщен работой. Во вторник и четверг вечером после окончания рабочих дел я собираю сумку и иду в спортзал, чтобы покрутить педали и отдохнуть в парилке. После нее кажется, что жизнь удалась!
Вне дома я люблю слушать аудиокниги. В последнее время мне нравится "боярка". Порой книги настолько увлекают, что я даже пытаюсь растянуть дорогу на машине, чтобы послушать подольше. Сейчас слушаю “Идеальный мир для лекаря”.
Вечером, уже дома, могу посмотреть кино с женой или сажусь за свой пет-проект. Просто изучать технологии мне уже не так неинтересно, а под конкретную задачу — вполне. В рамках пет-проекта я собираю опенсорсный сервис мониторинга — эдакий “швейцарский нож” девопсов. Пытаюсь найти для него кирпичики: смотрю чужие проекты и сервисы, экспериментирую с ними. Там бывают интересные задачки — можно случайно залипнуть и “очнуться” в 3 часа ночи, понимая, что уже как 3 часа ты должен спать =D.

День подошел к концу. Завтра снова буду следить за инфраструктурой и чинить возникающие поломки, чтобы сделать разработчиков наших клиентов чуть более счастливыми.
Хочу запросить обратную связь у коллег-айтишников. Что интересного у вас в течение дня происходит?
Показать полностью
3
Задачки для DevOps и SRE

В этом репозитории собраны вопросы и упражнения по различным техническим темам, иногда связанным с DevOps и SRE.
📊 На данный момент 2624 упражнений и вопросов.
Вы можете использовать их для подготовки к собеседованию, но большинство вопросов и упражнений не представляют собой настоящее собеседование.
Если вы заинтересованы в карьере инженера DevOps, изучение некоторых концепций, упомянутых здесь, будет полезно, но вы должны знать, что речь идет не об изучении всех тем и технологий, упомянутых в этом репозитории.
Показать полностью


Бесплатный курс "SRE: стратегии и методы"
МТС будет бесплатно готовить SRE - специалистов, которые обеспечивают доступность и надежность разрабатываемых компанией IT-систем и сервисов.
Обучение стартует в сентябре на онлайн-платформе образовательного центра МТС.Тета. Курс состоит из четырех модулей, занятия проходят в формате вебинаров дважды в неделю.
В первом модуле слушатели познакомятся с базовыми принципами SRE, затем студентам расскажут, что такое идеальное приложение с точки зрения данной узкой специализации, научат выстраивать системы мониторинга и работать с индикаторами.
Третий модуль будет посвящен балансировке нагрузки и работе с базами данных. Финальный модуль раскроет главную тайну - как проводятся те самые канареечные развертывания и Post mortem-анализ. Каждую из тем отработают на реальных кейсах.
Как создавать софт, как SRE
Перевод очень интересной статьи "How to Build Software like an SRE", в которой разбираются подходы к созданию приложений с точки зрения SRE.
Принципы надежности и компромиссы, усвоенные на собственном горьком опыте
Я занимаюсь этой “надежностью” уже некоторое время (около 5 лет), в компаниях, насчитывающих от 20 до более чем 2000 человек. Меня всегда в первую очередь всегда интересовали те элементы ПО, которые я описываю как живущие “вне” приложения — например, как приложение получает свою конфигурацию? На каких типах серверов оно запускается и являются ли эти типы наиболее подходящими? Что с ним происходит на пути от “кода в репозитории” до “запуска на проде”? И я всегда следил за тем, что мне нравится — какие механизмы позволяют быструю итерацию, а какие вызывают разочарование, какие приводят к сбоям, а какие предотвращают их.
Я думаю, что будет полезно, если я все это запишу, даже если это будет просто для меня в качестве справочника.
Обратите внимание, что этот список немного странный с точки зрения SRE. Моя цель не заключается в том, чтобы “построить все так, чтобы надежность была 100%”; это больше похоже на “как достичь 80% надежности, затратив 20% усилий, при этом позволяя разработчикам работать быстро”, что в конечном итоге дает нам систему, которая выглядит совсем по-другому. Но это стоит попробовать — если делать это хорошо, работа с продом становится интересной, а не уныло безопасной или ужасающе опасной.
Также, пожалуйста, сделайте мне одолжение и мысленно дополните каждый из следующих пунктов словом “обычно”. Каждая ситуация уникальна, и то, что я не сталкивался с тем, что (например) использование Git является плохой идеей, не означает, что такого случая не существует. “Только Ситхи всё возводят в абсолют”, и т.д.
Итак! Пройдя через всё это — вот как я бы начал все сначала, если бы мог.
Coding (параметры? да я их еле знаю!)
Никаких конфигов, зашитых в код. Если ваш сервис по какой-либо причине не может загрузить конфигурацию при запуске, он должен просто аварийно завершиться — этот случай гораздо проще диагностировать, чем результат того, что инстанс выполнил старый код, потому что никто не вспомнил о том, что нужно удалить строку config.get(enable_cool_new_thing, false).
Чрезвычайно строгие настройки RPC. Я говорю о нуле (или МОЖЕТ БЫТЬ одной) повторных попыток и таймауте, в 3 раза превышающем p⁹⁹. Здесь мы стремимся к предсказуемости, и многократные повторные попытки или длительные таймауты в качестве быстрого решения проблемы в работе сервиса превратятся в недельное расследование и головную боль через год. Исправьте неисправный сервис!
Никогда не отказывайтесь от локального тестирования. Это значительно сокращает время цикла разработки, чем необходимость полагаться (и возиться с этим) на CI или удаленные рабочие среды. Контейнеризация локальной тестовой среды может упростить управление зависимостями и обеспечить их переносимость между машинами.
Избегайте использования состояния как чумы. Управление сервисом с сохранением состояния (stateful) значительно сложнее, чем без сохранения состояния. Существует много хороших управляемых баз данных и кэшей, просто используйте один из них!
Merging (там, куда мы идем — тесты не нужны)
Используйте Git. Используйте его для всего — инфраструктуры, конфигов, кода, дашбордов, графиков дежурств. Ваш репозиторий Git — это источник истины, который можно восстановить на определенный момент времени.
Не тратьте время на полное покрытие кода тестами. И вообще, не занимайтесь “расстановкой галочек” — это только для красивых графиков и диаграмм, которые имеют очень мало общего с тем, какую фактическую ценность дает ваше изменение (см. ниже).
Уделяйте приоритетное внимание тестам в реальных условиях. Самый ценный тест, который занимает меньше всего времени, — это просто применение вашего изменения на стейджинге (или, еще лучше, на проде!) и демонстрация того, что оно делает то, что вы хотели, и не ломает всё. На втором месте по эффективности находятся интеграционные тесты, а юнит-тесты идут последними — то есть, “только если у вас есть на них время”.
При изменениях в инфраструктуре делайте планы максимально ясными и очевидными. Это может означать “положить Terraform Plan как коммент к пуллреквесту”, так же сделайте с diff helm. Существуют отличные инструменты, позволяющие убедиться, что изменения, которые, по вашему мнению, вы вносите, являются теми изменениями, которые вы вносите на самом деле, поэтому убедитесь, что они находятся в центре внимания.
При внесении изменений в код делайте регрессии максимально очевидными. Журналы ошибок, использование ЦП и частота ошибочных запросов являются отличными сигналами, позволяющими выявить около 90% плохих версий и работают для практически любого сервиса (полностью универсальны). Так что не отбрасывайте их!
Deploying (no sleep til prod)
Используйте Docker. Это отраслевой стандарт не просто так — разбор зависимостей в средах с такими инструментами, как Chef или Ansible, всегда проигрывает этой приятной автономности.
Развертывайте всё и всегда. Каждый день, который проходит без вашего деплоя, увеличивает вероятность того, что он на самом деле был незаметно сломан (в результате чьего-то изменения, обновления зависимостей, удаления стороннего API), и через две недели будет очень трудно выяснить, что и где пошло не так.
Проверяйте развертывания по мере их выполнения. Можете ли вы создать полностью поврежденный образ и успешно разлить его на все машины? Почему? Это можно исправить несколькими способами, включая canary/shadow развертывания или даже просто хорошими readiness проверками.
Включите ограничение на “мгновенное” развертывание конфигов. Это может показаться нелогичным (“мгновенное” часто означает “сломать все сразу и быстро”), но возможность отключить проблемную функцию или заблокировать IP менее чем за 5 минут с лихвой компенсирует повышенный риск. Это позволяет всё делать быстро, но управлять этим нужно осторожно!
Operating (my god, it’s full of pods)
Используйте Kubernetes. Предполагая, что у вас есть более одного сервиса и более одного инстанса, вам либо нужны, либо будут нужны такие вещи, как обнаружение сервисов, автоматическое масштабирование и управление версиями развертывания, и вы не хотите управлять всем этим самостоятельно. Kubernetes дает командам инфраструктуры сверхспособности масштабирования.
Используйте Helm. Или какой-то другой инструмент для управления манифестами Kubernetes, я не привередлив — главное, чтобы вы никогда не использовали прямые команды kubectl apply, edit или delete. Жизненный цикл ресурсов должен быть доступен в системе контроля версий.
Избегайте операторов и CRD (Custom Resource Definition). Как уже упоминалось выше, я люблю Kubernetes, но для очень многих разработчиков он очень сложен, и пользовательские операторы резко уходят в область “Что это за херня?”, что создает ему сложную репутацию. Пусть все будет просто.
Запускайте по 3 экземпляра всего. Как и с резервными копиями, два экземпляра — это один, а один — не существует :) Кроме того, убедитесь (действительно проверьте на проде), что 2 из 3 “штук” могут справиться с полной нагрузкой самостоятельно — в противном случае у вас на самом деле нет такой устойчивости к сбоям, как вы думаете.
Структурированные логи — это неотъемлемая часть. Вместе с идентификаторами трассировки они позволяют вам пройти 90% пути к APM (application performance monitoring), но при гораздо меньших затратах и усилиях со стороны разработчиков.
Итак, это текущий список! Думаю, что буду периодически возвращаться сюда и добавлять что-то еще. Пожалуйста, не стесняйтесь обращаться ко мне, если что-то из этого особенно вас раздражает или если у вас есть ещё что-то, о чем бы вы хотели бы поговорить 😜
Показать полностью
Лекторий по SRE
Полезный и бесплатный цикл лекций "Образовательный видеокурс по SRE от А до Я" от ведущего специалиста в этой области Дмитрия Масленникова.
Кому подойдет лекторий:
Начинающим специалистам: студентам старших курсов и начинающим SRE-специалистам, которые уже имеют опыт в промышленной разработке
Опытным DevOps-инженерам: которые хотят расширить свою экспертизу
Разработчикам: которые интересуются работой высоконагруженных систем