О! Задавили Замедлили интернеты! Срочно кодомудим куки, , шмуки, "зарегистрировайся", щупальца в интернет, картинки, анимашки, закругляшки, пидоршки, обновляшки, градиентики, х..дрыгания и пару гигов (т.е. не меньше 4 ГБ) чего попало! Быстрей пацаны! Быстрей! Вдруг снова всё включат!
Такое ощущение, что про подыхание замедление интернета программисты Яндексов, Вилдов, Сберов-Шмеров не в курсе: "У нас же за 1.27 секунды загрузилось! Все летает, как наскипидаренное. Benchmark, внатуре!" Ну, слава Богу, чё...
Немного не в тему. Когда "Обновить Сбер-Онлайн, иначе хер тебе" совпадает с "Обнови Ру-склад (сториии, ёптыть), иначе хер тебе" - начинаешь вдвойне, втройне и вообще на на всю життя, що залишилася, любить всю эту IT-халястру. Но не очень искренне.
"Сохрани чек" в том же "Сберкасса-онлайн" добавляет теплых чуйств. И RGB(EFEFEF) на фоне RGB(EEEEEE) очень креативно. И повсеместный бред - нажал [Enter], получил <p><p><p>, оно же 0xD0 0x0A 0xD0 0x0A 0xD0 0x0A. Зачем, ёптыть? Пикабу...
PS Да, да, я в курсе, что во всем виноват хтонический менеджер, но не ITешешнички. И в РКНе ни одного ITешника нет, глубокое пальпирование пакетов придумал дядя Вася проктолог и тот НКВДешник из расстрельной команды. Угу. И Ру-ютуб и Ру-Мах нам накодомудили злобные зеленые хуюмбалы из галактики Вонючие Канавки. Программистики только клавиатуры подтаскивали, за "200 тыр для нас оскорбление".
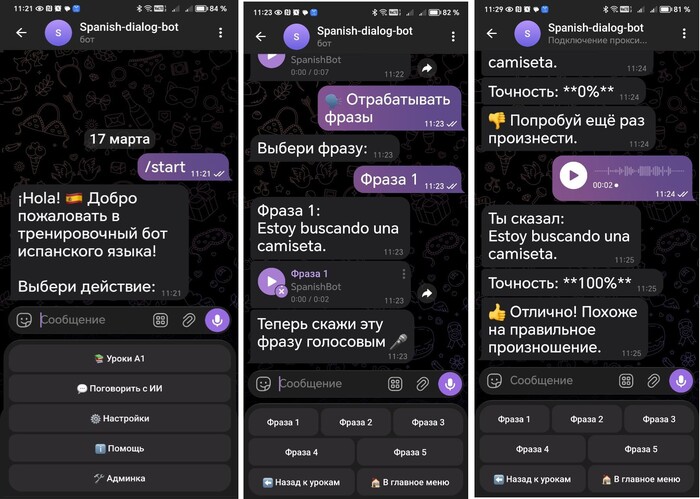
Меня зовут Влад, и я начинающий программист. Решил я как-то выучить испанский язык. Купил учебник, включил аудио... И понял главную проблему: я всё понимаю, когда слушаю диктора, но стоит мне самому открыть рот — я чувствую себя овощем. Нет обратной связи. Не с кем поговорить. А репетиторы стоят как крыло от самолета.
Подумал я: «А что, если сделать себе учителя из кода?» 💻
бот учитель испанского языка.
Так родился мой Telegram-бот, который теперь слушает мои голосовые, распознает речь и честно говорит: «Senor, ты сказал "каса" вместо "casa", точность 60%, попробуй еще раз!».
Что под капотом? (Для технарей)
Я не стал платить за дорогие API. Взял старый добрый Python, библиотеку aiogram и развернул на сервере Whisper.cpp (локально!).
Бот принимает голосовое. Прогоняет через локальную нейросеть Whisper (модель tiny, чтобы быстро работало). Сравнивает текст с эталоном из урока.
Выдает процент точности.
А еще там есть режим «Болталка с ИИ», где можно поговорить о жизни на испанском, и нейросеть поддержит диалог и исправит ошибки.
Получился такой цифровой полиглот-друг. 🦜
Зачем я это выкладываю?
Хочется поделиться результатом. Для меня это первый большой проект, где я соединил код и реальную пользу.
Мне нужны тестировщики! Бот работает, но чем больше людей будут им пользоваться, тем лучше я смогу его докрутить (добавить новые уроки, улучшить проверку).
Может, кому-то из пикабушников реально пригодится для практики, особенно тем, кто стесняется говорить с людьми.
Как попробовать?
Всё бесплатно. Заходите, тыкайте кнопки, ругайте бота за ошибки (или хвалите, если понравится 😄).
Недавно на Хабре вышла статья «Почему наш язык — худший язык для программирования». Автор справедливо отметил проблему двусмысленности естественного языка (ЕЯ) и предупредил, что программирование словами приведет к хаосу.
Я начну с неожиданного: автор оригинальной статьи абсолютно прав.
Он прав, если мы говорим о программировании заклинаниями (vibe-coding) — популярном сегодня подходе, когда человек пишет в окно чата: «Сделай мне интернет-магазин с красивым дизайном», а потом тонет в неконтролируемой лапше сгенерированного кода. В формате свободной болтовни с ботом естественный язык для написания кода действительно ужасен.
Но естественный язык можно использовать по-другому. Можно не просто болтать с ChatGPT — это ошибочный метод программирования на естественном языке. Его надо использовать как основу для строгих декларативных спецификаций.
Инструменты вроде CodeSpeak (публичная альфа-версия от создателя Kotlin Андрея Бреслава, о которой я подробно писал в своей статье) уже сегодня демонстрируют свой огромный потенциал: если загнать естественный язык в рамки контрактов, он способен стать лучшим, самым высоким из доступных нам уровней абстракции.
Будущее разработки: перекладывание JSON-ов или контроль смыслов через ИИ?
Эволюция роли разработчика: от ручного управления синтаксисом до архитектурного контроля смыслов с помощью ИИ.
Переход от ручного кодинга к управлению спецификациями: почему естественный язык становится новым инструментом архитектурного контроля смыслов, а роль разработчика трансформируется в валидатора ИИ-систем.
Миф №1: «Придется писать в 10 раз больше текста»
Оппонент утверждает, что для точного описания логики на английском или русском потребуется в 10 раз больше слов, чем в коде. Практика CodeSpeak доказывает ровно обратное: объем того, что поддерживает человек, сокращается в 6–10 раз.
В CodeSpeak вместо написания кода вы пишете спецификацию в Markdown-файле .cs.md. Это не роман и не поток сознания. Это структурированный естественный язык, упакованный в жесткий Markdown-формат с четкими разделами (входные данные, структура вывода, требования).
Взгляните на реальный пример спецификации из моей статьи:
``` # EmlConverter
Converts RFC 5322 email files (.eml) to Markdown using Python's built-in `email` module.
## Accepts
`.eml` extension or `message/rfc822` MIME type.
## Output Structure
1. **Headers section**: From, To, Cc, Subject, Date as `**Key:** value` pairs 2. **Body**: plain text preferred; if only HTML, convert to markdown 3. **Attachments section** (if any): list with filename, MIME type, human-readable size
## Parsing Requirements
- Decode RFC 2047 encoded headers (e.g., `=?UTF-8?B?...?=`) - Decode body content (base64, quoted-printable) - Handle multipart: walk parts, prefer `text/plain` over `text/html` - For `message/rfc822` parts: recursively format as quoted nested message - Extract attachment metadata without decoding attachment content ```
Здесь нет синтаксического шума, бойлерплейта или ручного управления памятью. Здесь описана чистая бизнес-логика и контракты ввода-вывода. LLM (например, Claude Opus) читает этот файл, генерирует код и тесты. Синтаксис программирования не умирает — он просто поднимается на уровень выше, скрываясь под капотом LLM-компилятора.
Миф №2: Ловушка зеленых тестов
Автор оригинала пугает нас тем, что всего через десяток-другой изменений проект превратится в «клубок», где новые фичи ломают старые, а нейросеть пишет неправильный код, который проходит такие же неправильные тесты (ведь машина выполнила двусмысленный запрос формально верно).
Это реальная проблема, но она решается жесткой архитектурной изоляцией, которую, например, предлагает CodeSpeak или другой аналогичный инструмент разработки.
В CodeSpeak ИИ не работает в режиме «перепиши мне всё». Обычно он ограничен рамками одной или нескольких связанных спецификаций. Изменение логики парсинга писем никогда не сломает модуль оплаты, потому что LLM работает строго в границах локального контракта.
А как же тесты? Да, LLM пишет их сама. Но здесь меняется роль человека: он становится архитектором смыслов. Разработчик больше не ищет пропущенные запятые в Python-скрипте, он проводит ревью спецификаций и сгенерированных тест-кейсов. Двусмысленность устраняется на этапе согласования требований человеком, а не на этапе генерации.
Миф №3: «В точных науках нужен строгий формализм, а не слова»
Оппонент ссылается на аппаратные ограничения и математическую точность. Да, если вы пишете драйвер для видеокарты или ядро СУБД, вам нужен Rust или C++.
Но 90% софта в мире — это бизнес-логика. И здесь уместно вспомнить, как работают сами математики. Дональд Кнут в «Искусстве программирования» дает алгоритмы в строгом MIX-ассемблере, но обязательно подробно объясняет их на естественном языке.
В точных науках формулы нужны для строгого доказательства, а естественный язык — для передачи интуиции и смысла. Математики не общаются только формулами, иначе они бы не поняли друг друга.
В программировании будущего будет точно так же:
Человек использует естественный язык для проектирования архитектуры и бизнес-правил.
LLM берет на себя «механические вычисления» — трансляцию этих правил в Python, Java или Go.
Комментарии в коде — лучшее доказательство
Вспомните самую сложную и запутанную часть вашей кодовой базы. Скорее всего, над ней висит огромный комментарий на естественном языке.
Почему? Потому что код отвечает на вопрос «как», а естественный язык отвечает на вопрос «зачем». Код не способен передать высокоуровневую мотивацию и граничные случаи так же емко, как это делает человеческая речь. И именно эти комментарии сегодня помогают LLM-моделям при рефакторинге не терять суть задачи. Так почему бы не сделать эти «комментарии» самим источником истины (Source of Truth)?
Эволюция языков программирования не остановится на Python
Мы уже прошли долгий путь: машинный код → ассемблер → C → Java/Python. Каждый шаг — это отказ от ручного контроля в пользу более высокой абстракции.
Делегирование рутины компиляторам — это естественный прогресс. Да, пока мы находимся на этапе тестирования публичных альфа-версий подобных инструментов, но LLM — это просто следующий, сверхмощный компилятор, который уже сегодня понимает естественный язык без критических галлюцинаций, если его загнать в достаточно простые рамки формализма спецификаций.
Естественный язык в виде неструктурированной болтовни — действительно худший инструмент разработчика. Но естественный язык, упакованный в достаточно строгие контракты с автоматической кодогенерацией и тестами — это лучший язык программирования. Он детерминирован рамками модуля, он понятен бизнесу, и он позволяет инженеру быть инженером, а не синтаксическим принтером.
Пришло время перестать бороться с естественным языком и научиться его правильно готовить.
Что думаете? Готовы ли вы делегировать написание кода LLM, оставив за собой контроль контрактов, или продолжите вручную перекладывать JSON-ы до пенсии?
Для поиска информации в ГОСТах. Для исправления технических описаний — чтобы превращать мой корявый текст в нормальный. Где-то в тексте нужно, например, изменить одни значения на другие, и не простым «найти — заменить», а по-нормальному, со склонениями и прочим.
Как-то попросил решить мою задачу в Excel. Просто не знал, есть ли такие инструменты, а «Гугл» выдаёт только ссылки на колхозные решения.
А тут решил заняться «программированием». Есть потребность создавать папки, в папках — ещё папки, а в них — ещё. В общем, для проекта — готовая структура. Это помогает не создавать «Новая папка (10)» и обеспечивает строгую структуру, когда ты знаешь, где что искать. Так вот, на это дело я потратил где-то час.
Быстро пробуешь, просишь поправить — были проблемы с кодировкой языка. И всё, теперь у меня есть отличный инструмент.
Но важно помнить: я эти задачи мог решить и окольными путями. Я точно знал, какой результат мне нужен и как его формализовать. Я не использовал ИИ как «сделай заебись» — я ставил чёткую задачу.
Предыдущий новостной дайджитсу был написан около 3 месяцев назад. Дааааа, затянулось у меня возвращение к написательству статей. Ну шо жеж, возвращаемся и присутпаем.
Стартап Миры Мурати получит 1 ГВт мощностей от Nvidia.
Ссылке. Nvidia и Thinking Machines Lab объявили о многолетнем стратегическом партнерстве. Стартап экс-CTO OpenAI Миры Мурати развернет как минимум гигаватт вычислительных мощностей на системах нового поколения Vera Rubin — начало поставок запланировано на 2027 год. Nvidia также стала стратегическим инвестором компании, хотя сумму вложений стороны не раскрыли. По оценке самого Дженсена Хуанга, гигаватт ИИ-инфраструктуры стоит до $50 млрд.
Помимо поставок железа, партнерство предполагает совместную оптимизацию разработок Thinking Machines под архитектуру Nvidia. Компания делает ставку на настраиваемый ИИ: пока единственный продукт — Tinker, API для дообучения открытых языковых моделей, запущенный в октябре 2025 года. Мурати обещает расширить доступ к фронтирным моделям для бизнеса, исследователей и научного сообщества.
Мюсли. Вообще эта ваша Миры Мурати выбрала достаточно интересную стратегию. Смотрите, на рынке уже куча компаний, предоставляющих свои чаты и апи с языковыми моделями. Лезть сюда и отгрызать свой кусочек пирога глупо. Поэтому решили поступит хитрее, вместо готовых решений предоставлять инструменты (железячные мощности) для обучения/дообучения языковых моделей под конкретные задачи. Некоторые крупные компании уже так делают, посмотрите хотя бы на Qwen3-Coder-Next, которая специально затачивалась под программирование. Я тоже такой задачей занимался и занимаюсь, а именно, обучаю малую языковую модель (240 миллионов параметров) задаче извлечения ключевых слов (семантических сущностей) из произвольного текста. Писал об этом тут и тут, а тек же, запилил бота @keywords_extractor_bot, чтобы все могли попробовать.
Nvidia выпустила опенсорсную языковую модель NVIDIA-Nemotron-3-Super-120B-A12B.
Ссычуан. Компания Nvidia анонсировала новую открытую модель Nemotron 3 Super, предназначенную для создания сложных систем из множества AI-агентов. Модель позиционируется как базовая платформа для разработки агентных архитектур, где несколько ИИ-модулей могут совместно выполнять сложные задачи.
Nemotron 3 Super построена на архитектуре Mixture of Experts (MoE), что позволяет эффективно распределять вычисления между специализированными «экспертами» внутри модели. По данным Nvidia, новая версия работает в пять раз быстрее и показывает примерно в два раза более высокую точность, чем предыдущая версия Nemotron Super.
Мюсли. Джейсон «Куртка» Хуанг поднапрягся и выпустил опенсорсную модель с 1 миллионом токенов контекста. 4-х битные кванты этой модели будет занимать около 64-84 гигабайт оперативной памяти. На обычном компьютере такой запустить будет проблематично, а вот на райзен неттопах с 128 гигабайтами оперативы, вполне.
Рецепт пельменей получил офер на фронтендера.
Чик. Для проверки алгоритмов некой площадки по поиску работы псевдонимный автор из Threads разместил десяток фальшивых резюме. Как рассказал экспериментатор, одно из них было очевидно шуточным и содержало рецепт пельменей. Именно рецепт пельменей пригласили на собеседование и предложили дать офер даже после объяснения ситуации.
Мюсли. Еще одно доказательство того, что HR окончательно и бесповоротно сломан.
Ну наконец-то хоть какие-то мемы
Видеогенератор Sora от OpenAI скоро появится в ChatGPT.
Пауч-пауч. OpenAI планирует развернуть генератор видео Sora в качестве встроенной функции чат-бота ChatGPT, пишет Information. В настоящее время инструмент доступен только на сайте и в виде отдельного приложения.
Мюсли. Сейчас Sora позиционируется, как отдельный сервис с возможностью нагенерировать кучу нейрослопа и поделиться им с миром.
Актуальный скриншот соры на момент написания статьи
Похоже, что Семушка Альтманов пытается привлеч новых пользователей и удержать текущих пользователей, на фоне возрастающей популярности Клода (не того, который Жан).
Нейросеть «Алиса» в умных устройствах «Яндекса» теперь работает на продвинутой ИИ‑модели.
Чпоньк. Теперь миллионы пользователей умных устройств получают более подробные и точные ответы «Алисы» — особенно на тему кино, игр, бытовых задач и путешествий. Это крупнейшее обновление ИИ‑модели в устройствах «Яндекса» за последний год.
По данным замеров методом слепого сравнения (Side by Side, SBS), текущая модель отвечает лучше предыдущей в 60% случаев. «Алиса» лучше понимает суть вопроса и чаще дает исчерпывающий ответ с первого раза. Сравнение моделей показало, что пользователи продвинутой версии на 9,9% реже переспрашивают «Алису». Сами ответы стали более подробными — их длина увеличилась в среднем на 37%. Кроме того, «Алиса» теперь лучше объясняет сложные вещи — к примеру, она подберёт понятные собеседнику аналогии, чтобы объяснить разницу между ИИ‑моделями разного размера.
Мюслие. Использую яндекс станцию с нового года, общее впечатление положительное. Да, запрогать в агентском режиме микросервис она вам не поможет, но как устройство для быстрого и простого поиска информации, а также воспроизведения музыки, вполне себе годится.
А на этом все, пацантре и пацантрины. Да, с телегой беда беда, но все же укажу ссылки на запиленых ботов, а именнобота для автоматического поиска организаций по городам, писал об этом тут. Так же реализовал бота мотиватора/вдохновлятора, который пишет «приятности», для поднятия настроения, писал о нем тут. Буду искать пути решения, посмотрим, мб придется из тг переходить на веб, что, к сожалению, создаст немного трудностей в реализации.
Как без образования из говна и палок мерседес собрать? Да спросим нейронку, чего бы нет. Идите блять учите базу! Затрахали недопрогеры, за вами потом переделывать дороже, зачем вы в нашу сферу лезете не имея никакого багажа знаний?
Набросал структуру алгоритма сознания в виде псевдокода, который легко можно переписать хоть на Python хоть на C++. В нем пока не реализованы функция обучения агента (бота) в среде, и алгоритм самой среды, а также эксперименты которые может делать сознание и оценка ценности целей. Имеет смысл написать точные алгритмы для простейших игр - например тетрис или змейки , или даже попроще игры с небольшими полями для игр. Комментарии по привычке написал на английском